


LZ77 e DEFLATE: a base do PNG e do ZIP (visão geral)
Olá leitor, seja muito bem vindo de volta a mais uma etapa da nossa jornada aqui no Portal da Micilini 😊
Este é o sétimo artigo da nossa série de ~20, e o último da Fase 2 — Fundamentos de Compressão.
Nos artigos anteriores, aprendemos duas técnicas de compressão:
Mas existe um terceiro tipo de redundância que nenhuma dessas duas técnicas explora: padrões que se repetem em posições diferentes dos dados.
Para que você possa entender, gostaria que você imaginasse a frase: "o rato roeu a roupa do rei de roma" 👑🐀
Percebe que "ro" aparece 3 vezes? E "r" seguido de vogal aparece várias vezes? O RLE não ajuda aqui (os caracteres não se repetem consecutivamente).
O Huffman ajuda um pouco (o "r" e o "o" são frequentes), porém ele não captura o fato de que sequências inteiras se repetem.
E é exatamente aí que entra o LZ77, o algoritmo principal deste artigo!
E quando combinamos o LZ77 com o Huffman, temos o DEFLATE, que é o algoritmo por trás do ZIP, do GZIP e do PNG.
Então pega seu café ☕, sente-se confortavelmente, e vamos fechar a Fase 2 com chave de ouro!
A história por trás: Lempel, Ziv e o ano de 1977
O LZ77 foi inventado por Abraham Lempel e Jacob Ziv, dois pesquisadores israelenses do Technion (Instituto de Tecnologia de Israel). O paper original foi publicado em 1977 (daí o "77" no nome).
Lempel e Ziv perceberam algo que Shannon, Huffman e os outros pioneiros não tinham explorado a fundo: na maioria dos dados do mundo real, sequências inteiras se repetem ao longo do arquivo, não apenas símbolos individuais.
Um texto em português repete palavras inteiras ("de", "que", "para", "não"), expressões ("por exemplo", "no entanto"), e até frases. Um código-fonte repete padrões de sintaxe (for (int i = 0;if (x != NULL)return 0;
A sacada de Lempel e Ziv foi: em vez de codificar cada símbolo individualmente (como o Huffman faz), por que não apontar de volta pra uma ocorrência anterior do mesmo padrão?
É como se em vez de escrever uma frase de novo, você dissesse: "repete aquilo que eu falei 5 linhas atrás, começando na terceira palavra, pegando 4 palavras".
Essa ideia parece simples, mas mudou o mundo. O LZ77 (e suas variações) está por trás de praticamente toda compressão lossless que usamos no dia a dia: ZIP, GZIP, 7z, PNG, HTTP/2, Git objects...
Um ano depois, em 1978, Lempel e Ziv publicaram uma variação chamada LZ78, que trabalha de forma ligeiramente diferente (com um dicionário explícito em vez de uma janela deslizante). O famoso LZW (usado no formato GIF e no comando compress do Unix) é baseado no LZ78.
A ideia central: referências ao passado
A ideia do LZ77 é genial na sua simplicidade.
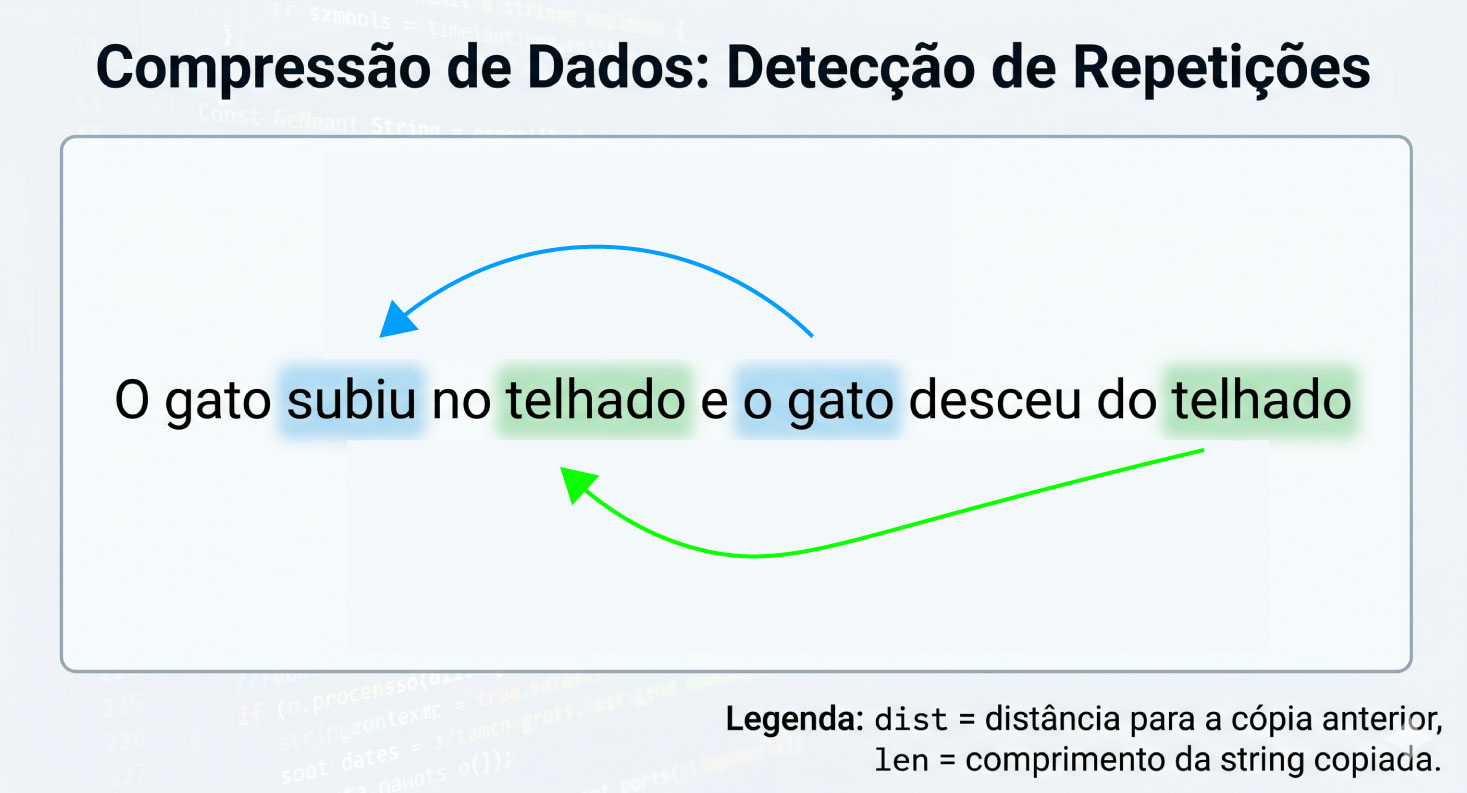
Imagine que você está lendo um livro e encontra a seguinte frase na página 50:
"O gato subiu no telhado e o gato desceu do telhado"
Em vez de escrever "o gato" e "telhado" duas vezes, você poderia escrever:
"O gato subiu no telhado e [volta 29 caracteres, copia 6] desceu do [volta 17 caracteres, copia 7]"
A primeira ocorrência é escrita normalmente (chamada de literal). As ocorrências seguintes são substituídas por referências que dizem "isso aqui é igual a algo que já apareceu antes".
Cada referência tem dois valores:
- Distância (distance): quantas posições pra trás olhar
- Comprimento (length): quantos bytes copiar a partir dessa posição
Então no LZ77, os dados comprimidos são uma mistura de:
- Literais: bytes que aparecem pela primeira vez (armazenados como estão)
- Referências (distância, comprimento): "copie X bytes de Y posições atrás"
A Janela Deslizante (Sliding Window)
Um detalhe importante: o LZ77 não olha pro arquivo inteiro pra encontrar repetições. Ele usa uma janela deslizante (sliding window) de tamanho fixo.
Imagine uma janela de 32 KB (32.768 bytes) que "desliza" pelo arquivo conforme ele é processado. A qualquer momento, o compressor só pode fazer referências a dados que estão dentro dessa janela (ou seja, nos últimos 32 KB já processados).
A janela é dividida em duas partes:
... dados já processados ... | ... dados sendo processados ... | ... dados futuros ...
←── JANELA ──→ ←── LOOKAHEAD ──→
(search buffer) (lookahead buffer)- Search buffer (buffer de busca): os dados que já foram comprimidos. É aqui que o compressor procura por correspondências (matches).
- Lookahead buffer: os próximos bytes que estão sendo analisados. O compressor tenta encontrar esses bytes em algum lugar do search buffer.
Conforme o compressor avança, a janela desliza pra frente, e dados antigos saem da janela (não podem mais ser referenciados).
E por que não olhar pro arquivo inteiro?
Duas razões principais, vejamos:
- Memória: manter o arquivo inteiro na memória pode ser impossível pra arquivos grandes (imagine um vídeo de 4 GB).
- Velocidade: buscar correspondências no arquivo inteiro é muito mais lento do que buscar numa janela de 32 KB.
No DEFLATE (que é o que nos interessa), a janela é de 32.768 bytes (32 KB) e o comprimento máximo de uma correspondência é 258 bytes.
Esses são os limites definidos pela especificação.
Exemplo passo a passo: comprimindo com LZ77
Vamos ver o LZ77 em ação com um exemplo concreto. Vejamos uma string curta pra poder mostrar cada passo:
Entrada: ABRACADABRA_ABRACADABRAAgora, eu vou processar da esquerda pra direita, mantendo o controle do que já foi processado (search buffer) e o que está sendo analisado (lookahead).
Passo 1: Posição 0, nada no search buffer ainda.
Search: (vazio)
Lookahead: ABRACADABRA_ABRACADABRANão tem nada pra referenciar. Emite literal: A
Passo 2: Posição 1.
Search: A
Lookahead: BRACADABRA_ABRACADABRA"B" não existe no search buffer. Emite literal: B
Passo 3: Posição 2.
Search: AB
Lookahead: RACADABRA_ABRACADABRA "R" não existe no search buffer. Emite literal: R
Passo 4: Posição 3.
Search: ABR
Lookahead: ACADABRA_ABRACADABRA "A" existe no search buffer (na posição 0)! Mas é só 1 caractere. O LZ77 exige um comprimento mínimo (geralmente 3) pra que a referência valha a pena (senão o overhead da referência custa mais que o literal), sendo assim, novamente emitimos a literal: A
Passos 5 a 11: Mesma lógica, processando C, A, D, A, B, R, A, _. Não encontra correspondências longas o suficiente (mínimo 3), então emite tudo como literais.
Se pararmos para perceber, até aqui, emitimos: A B R A C A D A B R A _
Passo 12: Posição 12. Agora vem a mágica!
Search: ABRACADABRA_
Lookahead: ABRACADABRAO compressor olha pro lookahead e tenta encontrar "ABRACADABRA" no search buffer. Encontra exatamente essa sequência começando na posição 0, com comprimento 11!
Emite referência: (distância=12, comprimento=11), e isso significa que o LZ77 vai dizer para a máquina: "volte 12 posições e copie 11 bytes".
Resultado final:
Original: ABRACADABRA_ABRACADABRA (23 bytes)
Comprimido: A B R A C A D A B R A _ (dist=12, len=11)
12 literais + 1 referênciaA segunda metade inteira ("ABRACADABRA") foi substituída por uma única referência de 2 valores. Em vez de armazenar 11 bytes, armazenamos uma referência que ocupa tipicamente 3-4 bytes.
O que representa uma economia significativa!
LZ77 em dados binários: como fica em bytes?
No exemplo acima, eu trouxe um exemplo de texto para facilitar o seu entendimento, porém, no mundo real o LZ77 trabalha com bytes genéricos (0 a 255). Vamos ver um exemplo com bytes crus:
Entrada: [10, 20, 30, 40, 50, 10, 20, 30, 40, 50, 10, 20, 30]Vamos entender como isso pode ser processado:
- Posições 0-4:
10 20 30 40 50 - Posição 5: o lookahead é
10 20 30 40 50 10 20 3010 20 30 40 50
Mas espera, o LZ77 permite algo surpreendente: a correspondência pode se estender além do search buffer pra dentro do lookahead. Isso permite codificar padrões repetitivos muito eficientemente.
Por exemplo, na posição 5, a referência (distância=5, comprimento=8) significa: "volte 5 posições e copie 8 bytes". Mas o search buffer só tem 5 bytes! Sendo assim, como fazemos para copiar 8?
O truque é que a cópia é feita byte a byte. Ao copiar o 6º byte, a posição de cópia já alcançou o que acabamos de escrever. Ou seja, é como uma sequencia de repetição cíclica:
Posição 5: copia de posição 0 → 10
Posição 6: copia de posição 1 → 20
Posição 7: copia de posição 2 → 30
Posição 8: copia de posição 3 → 40
Posição 9: copia de posição 4 → 50
Posição 10: copia de posição 5 → 10 (que acabou de ser escrito!)
Posição 11: copia de posição 6 → 20
Posição 12: copia de posição 7 → 30E como resultado nós temos:
Original: [10, 20, 30, 40, 50, 10, 20, 30, 40, 50, 10, 20, 30] (13 bytes)
Comprimido: [10, 20, 30, 40, 50] + referência(dist=5, len=8)
5 literais + 1 referência ≈ 8-9 bytesEssa propriedade de "copiar de si mesmo" é poderosa pra padrões periódicos (como texturas repetitivas em imagens, ou dados regulares em geral) 😉
DEFLATE: LZ77 + Huffman = o melhor dos dois mundos
Agora vamos ao algoritmo que realmente nos interessa: o DEFLATE.
O DEFLATE foi criado por Phil Katz em 1993, como parte do formato PKZIP (que depois virou o ZIP que conhecemos). Phil Katz pegou as duas melhores técnicas de compressão da época (LZ77 e Huffman) e combinou elas numa sequência inteligente.
O pipeline do DEFLATE funciona assim:
Etapa 1 — LZ77 (eliminação de repetições):
O LZ77 percorre os dados e substitui sequências repetidas por referências (distância, comprimento). O resultado é uma mistura de literais e referências.
Etapa 2 — Huffman (compressão estatística):
Os literais e as referências geradas pelo LZ77 são codificados com Huffman. Os valores mais frequentes (literais comuns, distâncias curtas, comprimentos pequenos) recebem códigos binários menores.
A combinação é sinérgica:
- O LZ77 sozinho é bom, mas os literais e referências ainda são armazenados de forma "crua".
- O Huffman sozinho é bom, mas não captura repetições de sequências, só frequências de símbolos individuais.
- Juntos, o LZ77 elimina as repetições (reduzindo a quantidade de dados) e o Huffman comprime o resultado de forma ótima (reduzindo os bits por símbolo).
É como se o LZ77 fosse o cara que organiza a bagunça do quarto (juntando roupas iguais em pilhas), e o Huffman fosse o cara que empacota as pilhas na mala da forma mais eficiente possível. Cada um faz o que sabe de melhor.
Dados originais
│
▼
[LZ77] → Literais + Referências (distância, comprimento)
│
▼
[Huffman] → Códigos binários de tamanho variável
│
▼
Dados comprimidos (DEFLATE)💡 Curiosidade: O DEFLATE na verdade usa duas árvores de Huffman separadas: uma pra codificar os literais e comprimentos, e outra pra codificar as distâncias. Isso permite que cada tipo de dado tenha sua própria distribuição de frequências otimizada.
Onde o DEFLATE é usado?
O DEFLATE está em todo lugar. Literalmente, e quando eu digo que ele é um dos algoritmos mais importantes da computação moderna, não estou exagerando 😂
ZIP e GZIP, são formatos que usam DEFLATE como algoritmo padrão, e isso significa que todo arquivo .zip que você já baixou, todo arquivo .tar.gz que um desenvolvedor já descompactou, usa DEFLATE por baixo dos panos.
No caso do PNG, o formato usa DEFALTE também, pra comprimir os dados de pixels. Isso explica por que o PNG é lossless: ele não descarta nenhuma informação, apenas usa LZ77 + Huffman pra representar os mesmos pixels com menos bytes.
Mas tem um detalhe interessante: antes de aplicar o DEFLATE, o PNG aplica filtros de predição em cada linha de pixels.
Esses filtros transformam os valores dos pixels em diferenças em relação aos vizinhos, o que cria muitos valores pequenos e repetitivos que o DEFLATE comprime muito melhor.
É como se o PNG dissesse: "em vez de armazenar o pixel (135, 180, 220), vou armazenar a diferença em relação ao pixel anterior (135-132=3, 180-178=2, 220-219=1)".
Diferenças pequenas se repetem muito mais do que valores absolutos, então o LZ77 encontra mais correspondências e o Huffman gera códigos menores.
Já no HTTP (na internet), quando acessamos um site, o servidor web frequentemente comprime a página HTML, o CSS e o JavaScript com GZIP (que usa DEFLATE) antes de enviar pro seu navegador.
Tipo de coisa que ajuda a reduzir o tempo de carregamento da página.
Se você olhar os headers de qualquer resposta HTTP, provavelmente vai encontrar Content-Encoding: gzip
Por fim, temos o git, que nada mais é do que um sistema de controle de versão que também faz o uso do DEFLATE internamente pra comprimir os objetos (commits, trees, blobs) que armazena no repositório. Cada arquivo que você versiona no Git é comprimido com DEFLATE.
LZ77 vs RLE vs Huffman: a comparação final
Agora que você conhece as 3 técnicas, vamos fazer a comparação definitiva:
RLE (Run-Length Encoding):
- Explora: repetições consecutivas (runs de valores iguais)
- Força: dados com grandes áreas uniformes (imagens simples, fax)
- Fraqueza: dados variados sem repetição consecutiva (fotos reais)
- Complexidade: muito simples
- Tipo: lossless
Huffman:
- Explora: frequências desiguais de símbolos individuais
- Força: dados onde alguns valores são muito mais comuns que outros
- Fraqueza: não captura repetições de sequências, só de símbolos individuais
- Complexidade: moderada (árvore binária)
- Tipo: lossless
LZ77:
- Explora: sequências que se repetem em posições diferentes dos dados
- Força: texto, código-fonte, dados estruturados, qualquer coisa com padrões repetitivos
- Fraqueza: dados puramente aleatórios (sem padrões)
- Complexidade: moderada (janela deslizante + busca de correspondências)
- Tipo: lossless
DEFLATE (LZ77 + Huffman):
- Explora: tudo de uma vez — repetições de sequências E frequências desiguais
- Força: quase tudo (texto, código, imagens lossless, dados genéricos)
- Fraqueza: dados já comprimidos ou puramente aleatórios
- Complexidade: alta (dois algoritmos combinados)
- Tipo: lossless
Implementando um LZ77 simplificado em C
Para fixar a teoria, vamos implementar uma versão simplificada neste primeiro momento do LZ77 em C.
Não vai ser uma implementação completa do DEFLATE neste tópico (mas no próximo será) mas vai demonstrar o conceito fundamental de encontrar correspondências e emitir literais ou referências.
Para isso, crie uma nova pasta chamada de lz77-test, e dentro dela um arquivo chamado main.c com o seguinte conteúdo:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// ============================================================
// LZ77 SIMPLIFICADO
// ============================================================
//
// Parâmetros da janela:
// WINDOW_SIZE: tamanho do search buffer (onde procurar matches)
// LOOKAHEAD_SIZE: tamanho do lookahead buffer
// MIN_MATCH: comprimento mínimo pra uma referência valer a pena
//
// No DEFLATE real: WINDOW_SIZE = 32768, MAX_MATCH = 258, MIN_MATCH = 3
// Aqui usamos valores menores pra facilitar a visualização.
#define WINDOW_SIZE 256
#define LOOKAHEAD_SIZE 64
#define MIN_MATCH 3
// Cada token de saída é:
// - Um LITERAL: type=0, valor=byte
// - Uma REFERÊNCIA: type=1, distância + comprimento
typedef struct {
int type; // 0 = literal, 1 = referência
unsigned char literal; // o byte literal (se type=0)
int distancia; // distância pra trás (se type=1)
int comprimento; // quantos bytes copiar (se type=1)
} TokenLZ77;
// ============================================================
// ENCODER: encontra correspondências e emite tokens
// ============================================================
int lz77_encode(unsigned char *entrada, int tamanho,
TokenLZ77 *saida, int max_tokens) {
int pos = 0; // posição atual na entrada
int num_tokens = 0; // quantos tokens já emitimos
while (pos < tamanho && num_tokens < max_tokens) {
int melhor_dist = 0;
int melhor_len = 0;
// Define os limites do search buffer
// (não pode olhar antes do início do arquivo)
int inicio_busca = pos - WINDOW_SIZE;
if (inicio_busca < 0) inicio_busca = 0;
// Define o limite do lookahead
int lookahead_max = tamanho - pos;
if (lookahead_max > LOOKAHEAD_SIZE) lookahead_max = LOOKAHEAD_SIZE;
// Procura a melhor correspondência no search buffer
for (int s = inicio_busca; s < pos; s++) {
int len = 0;
// Conta quantos bytes consecutivos são iguais
// Note: a cópia pode se estender além de 'pos'
// (o truque do "copiar de si mesmo")
while (len < lookahead_max && entrada[s + len] == entrada[pos + len]) {
len++;
}
// Se essa correspondência é a melhor até agora, salva
if (len > melhor_len) {
melhor_len = len;
melhor_dist = pos - s;
}
}
// Decide: emitir literal ou referência?
if (melhor_len >= MIN_MATCH) {
// Correspondência boa o suficiente → emite referência
saida[num_tokens].type = 1;
saida[num_tokens].distancia = melhor_dist;
saida[num_tokens].comprimento = melhor_len;
num_tokens++;
pos += melhor_len; // avança pelo comprimento da correspondência
} else {
// Correspondência muito curta (ou nenhuma) → emite literal
saida[num_tokens].type = 0;
saida[num_tokens].literal = entrada[pos];
num_tokens++;
pos += 1; // avança 1 byte
}
}
return num_tokens;
}
// ============================================================
// DECODER: reconstrói os dados a partir dos tokens
// ============================================================
int lz77_decode(TokenLZ77 *tokens, int num_tokens,
unsigned char *saida, int max_saida) {
int pos = 0; // posição atual na saída
for (int i = 0; i < num_tokens && pos < max_saida; i++) {
if (tokens[i].type == 0) {
// Literal: escreve o byte diretamente
saida[pos] = tokens[i].literal;
pos++;
} else {
// Referência: copia bytes de uma posição anterior
int dist = tokens[i].distancia;
int len = tokens[i].comprimento;
int src = pos - dist; // posição de onde copiar
// Copia byte a byte (importante pra o caso de
// dist < len, onde copiamos de nós mesmos)
for (int j = 0; j < len && pos < max_saida; j++) {
saida[pos] = saida[src + j];
pos++;
}
}
}
return pos;
}
// ============================================================
// MAIN — Testa com exemplos concretos
// ============================================================
int main() {
printf("=== LZ77 Simplificado ===\n\n");
// ----- Teste 1: ABRACADABRA_ABRACADABRA -----
printf("--- Teste 1: ABRACADABRA_ABRACADABRA ---\n\n");
char *texto1 = "ABRACADABRA_ABRACADABRA";
int tamanho1 = strlen(texto1);
TokenLZ77 tokens1[100];
int num_tokens1 = lz77_encode((unsigned char *)texto1, tamanho1,
tokens1, 100);
printf("Original: \"%s\" (%d bytes)\n\n", texto1, tamanho1);
printf("Tokens LZ77:\n");
int literais1 = 0, refs1 = 0;
for (int i = 0; i < num_tokens1; i++) {
if (tokens1[i].type == 0) {
printf(" [L] '%c'\n", tokens1[i].literal);
literais1++;
} else {
printf(" [R] (dist=%d, len=%d)\n",
tokens1[i].distancia, tokens1[i].comprimento);
refs1++;
}
}
printf("\nTotal: %d literais + %d referências = %d tokens\n",
literais1, refs1, num_tokens1);
// Estimar tamanho comprimido
// (1 byte por literal, 3 bytes por referência: 1 flag + 1 dist + 1 len)
int tam_comp1 = literais1 * 1 + refs1 * 3;
printf("Tamanho estimado: ~%d bytes (original: %d bytes)\n",
tam_comp1, tamanho1);
printf("Economia estimada: ~%.1f%%\n\n",
(1.0 - (double)tam_comp1 / tamanho1) * 100.0);
// Verificação lossless
unsigned char dec1[100];
int tam_dec1 = lz77_decode(tokens1, num_tokens1, dec1, 100);
dec1[tam_dec1] = '\0';
int ok1 = (tam_dec1 == tamanho1) && (memcmp(texto1, dec1, tamanho1) == 0);
printf("Decodificado: \"%s\"\n", dec1);
printf("Lossless: %s\n\n", ok1 ? "SIM" : "NÃO (ERRO!)");
// ----- Teste 2: Padrão repetitivo longo -----
printf("--- Teste 2: Padrão repetitivo longo ---\n\n");
// Cria uma string com um padrão de 5 bytes repetido 10 vezes
unsigned char teste2[50];
for (int i = 0; i < 50; i++) {
unsigned char padrao[] = {10, 20, 30, 40, 50};
teste2[i] = padrao[i % 5];
}
int tamanho2 = 50;
TokenLZ77 tokens2[100];
int num_tokens2 = lz77_encode(teste2, tamanho2, tokens2, 100);
printf("Original: [10,20,30,40,50] repetido 10x (%d bytes)\n\n", tamanho2);
printf("Tokens LZ77:\n");
int literais2 = 0, refs2 = 0;
for (int i = 0; i < num_tokens2; i++) {
if (tokens2[i].type == 0) {
printf(" [L] %d\n", tokens2[i].literal);
literais2++;
} else {
printf(" [R] (dist=%d, len=%d)\n",
tokens2[i].distancia, tokens2[i].comprimento);
refs2++;
}
}
printf("\nTotal: %d literais + %d referências = %d tokens\n",
literais2, refs2, num_tokens2);
int tam_comp2 = literais2 * 1 + refs2 * 3;
printf("Tamanho estimado: ~%d bytes (original: %d bytes)\n",
tam_comp2, tamanho2);
printf("Economia estimada: ~%.1f%%\n\n",
(1.0 - (double)tam_comp2 / tamanho2) * 100.0);
unsigned char dec2[100];
int tam_dec2 = lz77_decode(tokens2, num_tokens2, dec2, 100);
int ok2 = (tam_dec2 == tamanho2) && (memcmp(teste2, dec2, tamanho2) == 0);
printf("Lossless: %s\n\n", ok2 ? "SIM" : "NÃO (ERRO!)");
// ----- Teste 3: Dados sem repetição (pior caso) -----
printf("--- Teste 3: Dados sem repetição (pior caso) ---\n\n");
unsigned char teste3[20];
for (int i = 0; i < 20; i++) teste3[i] = (unsigned char)(i * 13 + 7);
int tamanho3 = 20;
TokenLZ77 tokens3[100];
int num_tokens3 = lz77_encode(teste3, tamanho3, tokens3, 100);
int literais3 = 0, refs3 = 0;
for (int i = 0; i < num_tokens3; i++) {
if (tokens3[i].type == 0) literais3++;
else refs3++;
}
printf("Original: 20 bytes sem padrão\n");
printf("Tokens: %d literais + %d referências\n", literais3, refs3);
int tam_comp3 = literais3 * 1 + refs3 * 3;
printf("Tamanho estimado: ~%d bytes (original: %d bytes)\n",
tam_comp3, tamanho3);
printf("Economia: ~%.1f%% %s\n\n",
(1.0 - (double)tam_comp3 / tamanho3) * 100.0,
tam_comp3 >= tamanho3 ? "(sem ganho)" : "");
unsigned char dec3[100];
int tam_dec3 = lz77_decode(tokens3, num_tokens3, dec3, 100);
int ok3 = (tam_dec3 == tamanho3) && (memcmp(teste3, dec3, tamanho3) == 0);
printf("Lossless: %s\n\n", ok3 ? "SIM" : "NÃO (ERRO!)");
// ----- Resumo -----
printf("=== Resumo ===\n");
printf("Teste 1 (ABRACADABRA×2): %2d bytes → ~%2d bytes (%.1f%%)\n",
tamanho1, tam_comp1, (1.0-(double)tam_comp1/tamanho1)*100.0);
printf("Teste 2 (padrão×10): %2d bytes → ~%2d bytes (%.1f%%)\n",
tamanho2, tam_comp2, (1.0-(double)tam_comp2/tamanho2)*100.0);
printf("Teste 3 (sem padrão): %2d bytes → ~%2d bytes (%.1f%%)\n",
tamanho3, tam_comp3, (1.0-(double)tam_comp3/tamanho3)*100.0);
return 0;
}Pra compilar e rodar siga os passos abaixo no seu terminal:
cd ~/lz77-test
gcc main.c -o lz77
./lz77Repare no Teste 2: um padrão de 5 bytes repetido 10 vezes (50 bytes) é comprimido pra apenas ~8 bytes. O LZ77 encontra o padrão inteiro na primeira ocorrência e referencia ele com uma única referência (distância=5, comprimento=45). Isso é algo impressionante!
E repare no Teste 3: dados sem padrão nenhum resultam em 100% de literais e zero referências. O LZ77, como o RLE e o Huffman, precisa de redundância pra funcionar. Sem padrões repetitivos, não tem o que comprimir.
Dito isso, recomendo você pegar mais um café, porque no próximo tópico, iremos construir juntos um LZ77 completo com serialização binária real.
Ele será capaz de gerar um arquivo comprimido e um decoder que reconstrói o original 🤓
Implementando um LZ77 completo em C
Agora vamos ao que interessa de verdade: implementar um LZ77 completo e funcional em C. Nada de versão simplificada ou "de brinquedo". Vamos construir um compressor e descompressor real, com:
- Serialização binária com BitWriter e BitReader (escrita e leitura bit a bit)
- Formato de arquivo próprio (.lz77) com header, magic number e metadados
- Interface de linha de comando pra comprimir e descomprimir qualquer arquivo
- Janela de 32 KB e match máximo de 258 bytes (mesmos parâmetros do DEFLATE)
- 6 testes internos que verificam lossless em diferentes cenários
O código é um arquivo único (main.c) com ~500 linhas, todo comentado.
Dito isso, vamos construir peça por peça 🤗
Antes de partir para o código, vamos entender a arquitetura do nosso compressor:
COMPRESSOR
Arquivo original → [Encoder LZ77] → BitWriter → Arquivo .lz77
┌──────────┐
│ HEADER │
│ "LZ77" │
│ tam_orig │
│ janela │
│ max_match │
├──────────┤
│ DADOS │
│ (bits) │
└──────────┘
DESCOMPRESSOR
Arquivo .lz77 → [Header] → BitReader → [Decoder LZ77] → Arquivo restauradoÉ importante ressaltar também que o formato possui um header fixo de 12 bytes, seguido dos dados comprimidos:
[Header — 12 bytes]
Bytes 0-3: Magic number "LZ77" (pra identificar o formato)
Bytes 4-7: Tamanho original do arquivo (4 bytes, little-endian)
Bytes 8-9: Tamanho da janela (2 bytes, little-endian)
Bytes 10-11: Comprimento máximo do match (2 bytes, little-endian)
[Dados comprimidos — tamanho variável]
Sequência de tokens, cada um começando com 1 bit de flag:
Flag 0 → LITERAL: 8 bits do byte original = 9 bits total
Flag 1 → REFERÊNCIA: 15 bits de distância + 8 bits de comprimento = 24 bits totalPor que 15 bits pra distância? Porque a janela é de 32.768 bytes, e 2¹⁵ = 32.768. Exatamente o necessário.
Por que 8 bits pro comprimento? Porque o match máximo é 258. Com o comprimento armazenado como (valor - MIN_MATCH), 8 bits representam 0 a 255, que correspondem a comprimentos de 3 a 258. Exatamente o que precisamos.
Quando vale a pena emitir uma referência em vez de literais? Uma referência custa 24 bits (3 bytes). Três literais custam 27 bits. Então qualquer match de 3 bytes ou mais já economiza. Por isso MIN_MATCH = 3.
Peça 1: BitWriter e BitReader
Como os tokens não são alinhados em bytes (um literal custa 9 bits, uma referência custa 24 bits), precisamos de estruturas que permitam escrever e ler bit a bit.
O BitWriter acumula bits num buffer de bytes, preenchendo cada byte do bit mais significativo (MSB) pro menos significativo (LSB). Quando um byte está cheio (8 bits escritos), avança pro próximo.
O BitReader faz o inverso: lê bits individuais do buffer na mesma ordem em que foram escritos.
Peça 2: O Encoder (encontrar matches + serializar)
O encoder percorre os dados de entrada da esquerda pra direita. Em cada posição, ele tenta encontrar a melhor correspondência (a mais longa) no search buffer (os últimos 32 KB já processados).
A busca funciona assim: pra cada posição possível no search buffer, o encoder compara byte a byte com o lookahead. Ele guarda a correspondência mais longa que encontrar.
Se a melhor correspondência tem 3 bytes ou mais, emite uma referência (flag=1, distância, comprimento). Caso contrário, emite um literal (flag=0, byte).
Um detalhe importante: a correspondência pode se estender além do search buffer, pra dentro do próprio output. Isso permite codificar padrões periódicos (tipo "ABCABCABC...") com uma única referência onde distância < comprimento. O decoder lida com isso naturalmente, porque copia byte a byte.
Peça 3: O Decoder (ler tokens + reconstruir)
O decoder é bem mais simples que o encoder. Ele lê o header, cria um BitReader pros dados comprimidos, e processa token por token:
- Lê 1 bit de flag
- Se flag=0: lê 8 bits = um byte literal, escreve na saída
- Se flag=1: lê 15 bits de distância + 8 bits de comprimento, copia os bytes correspondentes da saída (que já foi parcialmente escrita)
A cópia é feita byte a byte (não com memcpy), justamente pra lidar com o caso de distância < comprimento.
O código completo
Segue abaixo num único arquivo main.c
Sendo assim, crie uma pasta chamada lz77-complete-test, e dentro dela um arquivo chamado main.c com a seguinte lógica:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// ============================================================
// PARÂMETROS DO LZ77
// ============================================================
// Mesmos parâmetros do DEFLATE:
// Janela de 32 KB, match máximo de 258 bytes, mínimo de 3
#define WINDOW_SIZE 32768
#define MAX_MATCH 258
#define MIN_MATCH 3
#define DIST_BITS 15 // 2^15 = 32768 (cobre a janela inteira)
#define LEN_BITS 8 // 8 bits = 0..255, que com offset +3 = 3..258
// ============================================================
// BITWRITER — Escreve bits individuais num buffer de bytes
// ============================================================
//
// Os tokens do LZ77 não são alinhados em bytes:
// - Literal: 1 bit flag + 8 bits valor = 9 bits
// - Referência: 1 bit flag + 15 bits dist + 8 bits len = 24 bits
//
// Por isso precisamos escrever bit a bit.
// O BitWriter preenche cada byte do MSB (bit 7) pro LSB (bit 0).
typedef struct {
unsigned char *buffer; // array de bytes
int capacidade; // tamanho alocado
int byte_pos; // qual byte estamos preenchendo
int bit_pos; // qual bit (7=MSB, 0=LSB)
int total_bits; // total de bits escritos
} BitWriter;
BitWriter *bitwriter_criar(int capacidade_inicial) {
BitWriter *bw = (BitWriter *) malloc(sizeof(BitWriter));
bw->buffer = (unsigned char *) calloc(capacidade_inicial, 1);
bw->capacidade = capacidade_inicial;
bw->byte_pos = 0;
bw->bit_pos = 7;
bw->total_bits = 0;
return bw;
}
// Dobra o buffer se necessário
void bitwriter_garantir_espaco(BitWriter *bw, int bytes_extras) {
while (bw->byte_pos + bytes_extras >= bw->capacidade) {
int cap_antigo = bw->capacidade;
bw->capacidade *= 2;
bw->buffer = (unsigned char *) realloc(bw->buffer, bw->capacidade);
memset(bw->buffer + cap_antigo, 0, bw->capacidade - cap_antigo);
}
}
// Escreve um único bit (0 ou 1)
void bitwriter_escrever_bit(BitWriter *bw, int bit) {
bitwriter_garantir_espaco(bw, 4);
if (bit) {
bw->buffer[bw->byte_pos] |= (1 << bw->bit_pos);
}
bw->bit_pos--;
bw->total_bits++;
if (bw->bit_pos < 0) {
bw->byte_pos++;
bw->bit_pos = 7;
}
}
// Escreve N bits de um valor inteiro (MSB primeiro)
void bitwriter_escrever_bits(BitWriter *bw, int valor, int num_bits) {
for (int i = num_bits - 1; i >= 0; i--) {
bitwriter_escrever_bit(bw, (valor >> i) & 1);
}
}
// Quantos bytes os bits escritos ocupam (arredondando pra cima)
int bitwriter_bytes_usados(BitWriter *bw) {
return (bw->bit_pos == 7) ? bw->byte_pos : bw->byte_pos + 1;
}
void bitwriter_liberar(BitWriter *bw) {
free(bw->buffer);
free(bw);
}
// ============================================================
// BITREADER — Lê bits individuais de um buffer de bytes
// ============================================================
typedef struct {
unsigned char *buffer;
int tamanho;
int byte_pos;
int bit_pos;
} BitReader;
BitReader *bitreader_criar(unsigned char *buffer, int tamanho) {
BitReader *br = (BitReader *) malloc(sizeof(BitReader));
br->buffer = buffer;
br->tamanho = tamanho;
br->byte_pos = 0;
br->bit_pos = 7;
return br;
}
int bitreader_ler_bit(BitReader *br) {
if (br->byte_pos >= br->tamanho) return 0;
int bit = (br->buffer[br->byte_pos] >> br->bit_pos) & 1;
br->bit_pos--;
if (br->bit_pos < 0) {
br->byte_pos++;
br->bit_pos = 7;
}
return bit;
}
int bitreader_ler_bits(BitReader *br, int num_bits) {
int valor = 0;
for (int i = 0; i < num_bits; i++) {
valor = (valor << 1) | bitreader_ler_bit(br);
}
return valor;
}
void bitreader_liberar(BitReader *br) {
free(br);
}
// ============================================================
// HEADER DO ARQUIVO .lz77
// ============================================================
typedef struct {
char magic[4]; // "LZ77"
unsigned int tamanho_orig; // tamanho do arquivo original
unsigned short janela; // tamanho da janela
unsigned short max_match; // comprimento máximo
} HeaderLZ77;
// ============================================================
// ENCODER — Busca correspondências e serializa em bits
// ============================================================
// Encontra o match mais longo no search buffer
int encontrar_match(unsigned char *dados, int tamanho, int pos,
int *melhor_dist) {
int melhor_len = 0;
*melhor_dist = 0;
int inicio = pos - WINDOW_SIZE;
if (inicio < 0) inicio = 0;
int max_len = tamanho - pos;
if (max_len > MAX_MATCH) max_len = MAX_MATCH;
for (int s = inicio; s < pos; s++) {
int len = 0;
// Compara byte a byte
// Permite len avançar além de pos (copiar de si mesmo)
while (len < max_len && dados[s + len] == dados[pos + len]) {
len++;
}
if (len > melhor_len) {
melhor_len = len;
*melhor_dist = pos - s;
if (melhor_len == max_len) break; // não dá pra melhorar
}
}
return melhor_len;
}
// Comprime dados e retorna o buffer do arquivo .lz77
unsigned char *lz77_comprimir(unsigned char *entrada, int tam_entrada,
int *tam_saida) {
BitWriter *bw = bitwriter_criar(tam_entrada + 1024);
int pos = 0;
int num_literais = 0, num_refs = 0;
while (pos < tam_entrada) {
int dist = 0;
int len = encontrar_match(entrada, tam_entrada, pos, &dist);
if (len >= MIN_MATCH) {
// REFERÊNCIA: flag=1 + distância (15 bits) + comprimento (8 bits)
bitwriter_escrever_bit(bw, 1);
bitwriter_escrever_bits(bw, dist, DIST_BITS);
bitwriter_escrever_bits(bw, len - MIN_MATCH, LEN_BITS);
pos += len;
num_refs++;
} else {
// LITERAL: flag=0 + byte (8 bits)
bitwriter_escrever_bit(bw, 0);
bitwriter_escrever_bits(bw, entrada[pos], 8);
pos++;
num_literais++;
}
}
// Monta o arquivo: header + dados comprimidos
int dados_bytes = bitwriter_bytes_usados(bw);
int total = sizeof(HeaderLZ77) + dados_bytes;
unsigned char *saida = (unsigned char *) malloc(total);
HeaderLZ77 *h = (HeaderLZ77 *) saida;
memcpy(h->magic, "LZ77", 4);
h->tamanho_orig = (unsigned int) tam_entrada;
h->janela = WINDOW_SIZE;
h->max_match = MAX_MATCH;
memcpy(saida + sizeof(HeaderLZ77), bw->buffer, dados_bytes);
*tam_saida = total;
printf(" Estatísticas: %d literais, %d referências\n",
num_literais, num_refs);
printf(" Bits: %d literais × 9 + %d refs × 24 = %d bits\n",
num_literais, num_refs,
num_literais * 9 + num_refs * 24);
bitwriter_liberar(bw);
return saida;
}
// ============================================================
// DECODER — Lê o arquivo .lz77 e reconstrói o original
// ============================================================
unsigned char *lz77_descomprimir(unsigned char *arquivo, int tam_arquivo,
int *tam_saida) {
if (tam_arquivo < (int)sizeof(HeaderLZ77)) {
printf("ERRO: arquivo muito pequeno.\n");
*tam_saida = 0;
return NULL;
}
HeaderLZ77 *h = (HeaderLZ77 *) arquivo;
if (memcmp(h->magic, "LZ77", 4) != 0) {
printf("ERRO: magic number inválido.\n");
*tam_saida = 0;
return NULL;
}
int tam_orig = (int) h->tamanho_orig;
printf(" Header: magic=LZ77, tam_orig=%d, janela=%d, max_match=%d\n",
tam_orig, h->janela, h->max_match);
unsigned char *saida = (unsigned char *) malloc(tam_orig);
if (!saida) {
printf("ERRO: sem memória.\n");
*tam_saida = 0;
return NULL;
}
BitReader *br = bitreader_criar(
arquivo + sizeof(HeaderLZ77),
tam_arquivo - sizeof(HeaderLZ77));
int pos = 0;
while (pos < tam_orig) {
int flag = bitreader_ler_bit(br);
if (flag == 0) {
// LITERAL
saida[pos] = (unsigned char) bitreader_ler_bits(br, 8);
pos++;
} else {
// REFERÊNCIA
int dist = bitreader_ler_bits(br, DIST_BITS);
int len = bitreader_ler_bits(br, LEN_BITS) + MIN_MATCH;
// Copia byte a byte (essencial pro caso dist < len)
int src = pos - dist;
for (int i = 0; i < len && pos < tam_orig; i++) {
saida[pos] = saida[src + i];
pos++;
}
}
}
bitreader_liberar(br);
*tam_saida = pos;
return saida;
}
// ============================================================
// LEITURA E ESCRITA DE ARQUIVOS
// ============================================================
unsigned char *ler_arquivo(const char *caminho, int *tamanho) {
FILE *f = fopen(caminho, "rb");
if (!f) {
printf("ERRO: não consegui abrir '%s'\n", caminho);
*tamanho = 0;
return NULL;
}
fseek(f, 0, SEEK_END);
*tamanho = (int) ftell(f);
fseek(f, 0, SEEK_SET);
unsigned char *dados = (unsigned char *) malloc(*tamanho);
if (fread(dados, 1, *tamanho, f) != (size_t)*tamanho) {
printf("ERRO: falha ao ler '%s'\n", caminho);
free(dados);
fclose(f);
*tamanho = 0;
return NULL;
}
fclose(f);
return dados;
}
int escrever_arquivo(const char *caminho, unsigned char *dados, int tamanho) {
FILE *f = fopen(caminho, "wb");
if (!f) {
printf("ERRO: não consegui criar '%s'\n", caminho);
return 0;
}
fwrite(dados, 1, tamanho, f);
fclose(f);
return 1;
}
// ============================================================
// TESTES INTERNOS
// ============================================================
void rodar_testes() {
printf("=== TESTES INTERNOS DO LZ77 COMPLETO ===\n\n");
// Teste 1: String com repetição
printf("--- Teste 1: ABRACADABRA_ABRACADABRA ---\n");
{
char *texto = "ABRACADABRA_ABRACADABRA";
int tam_orig = strlen(texto);
int tam_comp;
unsigned char *comp = lz77_comprimir((unsigned char *)texto, tam_orig, &tam_comp);
printf(" Original: %d bytes | Comprimido: %d bytes | Compressão: %.1f%%\n",
tam_orig, tam_comp, (1.0-(double)tam_comp/tam_orig)*100.0);
int tam_dec;
unsigned char *dec = lz77_descomprimir(comp, tam_comp, &tam_dec);
int ok = (tam_dec==tam_orig) && (memcmp(texto,dec,tam_orig)==0);
printf(" Lossless: %s\n\n", ok ? "✅ SIM" : "❌ NÃO (ERRO!)");
free(comp); free(dec);
}
// Teste 2: Padrão repetitivo longo
printf("--- Teste 2: Padrão [10,20,30,40,50] × 200 (1000 bytes) ---\n");
{
unsigned char dados[1000];
unsigned char padrao[] = {10, 20, 30, 40, 50};
for (int i = 0; i < 1000; i++) dados[i] = padrao[i % 5];
int tam_orig = 1000;
int tam_comp;
unsigned char *comp = lz77_comprimir(dados, tam_orig, &tam_comp);
printf(" Original: %d bytes | Comprimido: %d bytes | Compressão: %.1f%%\n",
tam_orig, tam_comp, (1.0-(double)tam_comp/tam_orig)*100.0);
int tam_dec;
unsigned char *dec = lz77_descomprimir(comp, tam_comp, &tam_dec);
int ok = (tam_dec==tam_orig) && (memcmp(dados,dec,tam_orig)==0);
printf(" Lossless: %s\n\n", ok ? "✅ SIM" : "❌ NÃO (ERRO!)");
free(comp); free(dec);
}
// Teste 3: Dados aleatórios (pior caso)
printf("--- Teste 3: 500 bytes pseudo-aleatórios (pior caso) ---\n");
{
unsigned char dados[500];
unsigned int seed = 12345;
for (int i = 0; i < 500; i++) {
seed = seed * 1103515245 + 12345;
dados[i] = (unsigned char)((seed >> 16) & 0xFF);
}
int tam_orig = 500;
int tam_comp;
unsigned char *comp = lz77_comprimir(dados, tam_orig, &tam_comp);
printf(" Original: %d bytes | Comprimido: %d bytes | %.1f%% %s\n",
tam_orig, tam_comp, (1.0-(double)tam_comp/tam_orig)*100.0,
tam_comp >= tam_orig ? "(EXPANDIU — esperado!)" : "");
int tam_dec;
unsigned char *dec = lz77_descomprimir(comp, tam_comp, &tam_dec);
int ok = (tam_dec==tam_orig) && (memcmp(dados,dec,tam_orig)==0);
printf(" Lossless: %s\n\n", ok ? "✅ SIM" : "❌ NÃO (ERRO!)");
free(comp); free(dec);
}
// Teste 4: Texto longo em português
printf("--- Teste 4: Texto longo em português ---\n");
{
char *texto =
"O rato roeu a roupa do rei de Roma. "
"O rato roeu a roupa do rei de Roma. "
"A rainha com raiva resolveu remendar. "
"A rainha com raiva resolveu remendar. "
"O rato roeu a roupa do rei de Roma. "
"O rato roeu a roupa do rei de Roma. "
"A rainha com raiva resolveu remendar. "
"A rainha com raiva resolveu remendar. "
"Pedro Paulo Pereira Pinto pintou paredes. "
"Pedro Paulo Pereira Pinto pintou paredes. "
"Pintou paredes com primor e perfeição. "
"Pintou paredes com primor e perfeição. ";
int tam_orig = strlen(texto);
int tam_comp;
unsigned char *comp = lz77_comprimir((unsigned char *)texto, tam_orig, &tam_comp);
printf(" Original: %d bytes | Comprimido: %d bytes | Compressão: %.1f%%\n",
tam_orig, tam_comp, (1.0-(double)tam_comp/tam_orig)*100.0);
int tam_dec;
unsigned char *dec = lz77_descomprimir(comp, tam_comp, &tam_dec);
int ok = (tam_dec==tam_orig) && (memcmp(texto,dec,tam_orig)==0);
printf(" Lossless: %s\n\n", ok ? "✅ SIM" : "❌ NÃO (ERRO!)");
free(comp); free(dec);
}
// Teste 5: Melhor caso absoluto
printf("--- Teste 5: 10000 bytes todos iguais (melhor caso) ---\n");
{
unsigned char dados[10000];
memset(dados, 0xAA, 10000);
int tam_orig = 10000;
int tam_comp;
unsigned char *comp = lz77_comprimir(dados, tam_orig, &tam_comp);
printf(" Original: %d bytes | Comprimido: %d bytes | Compressão: %.1f%%\n",
tam_orig, tam_comp, (1.0-(double)tam_comp/tam_orig)*100.0);
int tam_dec;
unsigned char *dec = lz77_descomprimir(comp, tam_comp, &tam_dec);
int ok = (tam_dec==tam_orig) && (memcmp(dados,dec,tam_orig)==0);
printf(" Lossless: %s\n\n", ok ? "✅ SIM" : "❌ NÃO (ERRO!)");
free(comp); free(dec);
}
// Teste 6: Ida e volta pelo disco
printf("--- Teste 6: Ida e volta pelo disco ---\n");
{
char *conteudo =
"Lorem ipsum dolor sit amet, consectetur adipiscing elit. "
"Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. "
"Lorem ipsum dolor sit amet, consectetur adipiscing elit. "
"Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. ";
int tam_orig = strlen(conteudo);
escrever_arquivo("teste_original.txt", (unsigned char *)conteudo, tam_orig);
int tam_comp;
unsigned char *comp = lz77_comprimir((unsigned char *)conteudo, tam_orig, &tam_comp);
escrever_arquivo("teste_original.txt.lz77", comp, tam_comp);
int tam_lido;
unsigned char *lido = ler_arquivo("teste_original.txt.lz77", &tam_lido);
int tam_dec;
unsigned char *dec = lz77_descomprimir(lido, tam_lido, &tam_dec);
escrever_arquivo("teste_restaurado.txt", dec, tam_dec);
int tam_rest;
unsigned char *rest = ler_arquivo("teste_restaurado.txt", &tam_rest);
int ok = (tam_rest==tam_orig) && (memcmp(conteudo,rest,tam_orig)==0);
printf(" Original: %d bytes → Comprimido: %d bytes → Restaurado: %d bytes\n",
tam_orig, tam_comp, tam_rest);
printf(" Compressão: %.1f%% | Ida e volta: %s\n\n",
(1.0-(double)tam_comp/tam_orig)*100.0,
ok ? "✅ PERFEITO" : "❌ ERRO!");
free(comp); free(lido); free(dec); free(rest);
}
}
// ============================================================
// MAIN — Interface de linha de comando
// ============================================================
int main(int argc, char *argv[]) {
if (argc < 2) {
printf("=== LZ77 Compressor/Descompressor Completo ===\n\n");
printf("Uso:\n");
printf(" %s comprimir <arquivo> <arquivo.lz77>\n", argv[0]);
printf(" %s descomprimir <arquivo.lz77> <arquivo>\n", argv[0]);
printf(" %s testar\n\n", argv[0]);
printf("Exemplo:\n");
printf(" %s comprimir meuarquivo.txt meuarquivo.txt.lz77\n", argv[0]);
printf(" %s descomprimir meuarquivo.txt.lz77 meuarquivo_restaurado.txt\n", argv[0]);
return 1;
}
if (strcmp(argv[1], "testar") == 0) {
rodar_testes();
return 0;
}
if (strcmp(argv[1], "comprimir") == 0) {
if (argc < 4) {
printf("Uso: %s comprimir <entrada> <saida.lz77>\n", argv[0]);
return 1;
}
printf("Comprimindo '%s' → '%s'...\n", argv[2], argv[3]);
int tam_ent;
unsigned char *ent = ler_arquivo(argv[2], &tam_ent);
if (!ent) return 1;
int tam_sai;
unsigned char *sai = lz77_comprimir(ent, tam_ent, &tam_sai);
escrever_arquivo(argv[3], sai, tam_sai);
printf(" Original: %d bytes → Comprimido: %d bytes (%.1f%%)\n",
tam_ent, tam_sai, (1.0-(double)tam_sai/tam_ent)*100.0);
free(ent); free(sai);
return 0;
}
if (strcmp(argv[1], "descomprimir") == 0) {
if (argc < 4) {
printf("Uso: %s descomprimir <entrada.lz77> <saida>\n", argv[0]);
return 1;
}
printf("Descomprimindo '%s' → '%s'...\n", argv[2], argv[3]);
int tam_ent;
unsigned char *ent = ler_arquivo(argv[2], &tam_ent);
if (!ent) return 1;
int tam_sai;
unsigned char *sai = lz77_descomprimir(ent, tam_ent, &tam_sai);
if (!sai) return 1;
escrever_arquivo(argv[3], sai, tam_sai);
printf(" Comprimido: %d bytes → Restaurado: %d bytes\n", tam_ent, tam_sai);
free(ent); free(sai);
return 0;
}
printf("Comando desconhecido: '%s'\n", argv[1]);
return 1;
}Como compilar e rodar:
cd ~/lz77-complete-tes
gcc main.c -o lz77 -O2
# Rodar os 6 testes internos
./lz77 testar
# Comprimir qualquer arquivo
./lz77 comprimir meuarquivo.txt meuarquivo.txt.lz77
# Descomprimir de volta
./lz77 descomprimir meuarquivo.txt.lz77 meuarquivo_restaurado.txt
# Verificar que o arquivo restaurado é idêntico ao original
diff meuarquivo.txt meuarquivo_restaurado.txt
Resultados dos testes
Abaixo, temos alguns exemplos de resultados reais que foram testados e verificados por nós:
=== TESTES INTERNOS DO LZ77 COMPLETO ===
--- Teste 1: ABRACADABRA_ABRACADABRA ---
Estatísticas: 8 literais, 2 referências
Original: 23 bytes | Comprimido: 27 bytes | Compressão: -17.4%
Lossless: ✅ SIM
--- Teste 2: Padrão [10,20,30,40,50] × 200 (1000 bytes) ---
Estatísticas: 5 literais, 4 referências
Original: 1000 bytes | Comprimido: 30 bytes | Compressão: 97.0%
Lossless: ✅ SIM
--- Teste 3: 500 bytes pseudo-aleatórios (pior caso) ---
Estatísticas: 500 literais, 0 referências
Original: 500 bytes | Comprimido: 575 bytes | -15.0% (EXPANDIU — esperado!)
Lossless: ✅ SIM
--- Teste 4: Texto longo em português ---
Estatísticas: 100 literais, 17 referências
Original: 462 bytes | Comprimido: 176 bytes | Compressão: 61.9%
Lossless: ✅ SIM
--- Teste 5: 10000 bytes todos iguais (melhor caso) ---
Estatísticas: 1 literais, 39 referências
Original: 10000 bytes | Comprimido: 131 bytes | Compressão: 98.7%
Lossless: ✅ SIM
--- Teste 6: Ida e volta pelo disco ---
Original: 384 bytes → Comprimido: 221 bytes → Restaurado: 384 bytes
Compressão: 42.4% | Ida e volta: ✅ PERFEITOAlguns destaques:
Teste 1 expandiu (-17.4%) porque a string é curta demais: o header de 12 bytes + o overhead de 1 bit de flag por literal pesam mais que a economia das 2 referências. Em dados pequenos, qualquer compressor sofre com o custo fixo do header.
Teste 2 comprimiu 97% porque o padrão de 5 bytes se repete 200 vezes. O LZ77 encontra o padrão na primeira ocorrência e referencia tudo com pouquíssimas referências (4 referências pra 995 bytes de matches).
Teste 3 expandiu 15% (esperado!), porque dados aleatórios não têm padrão. Cada literal custa 9 bits em vez de 8 (o bit de flag extra). Isso confirma que sem redundância, não tem compressão.
Teste 5 é o melhor caso: 10.000 bytes idênticos comprimidos pra 131 bytes (98.7%). O LZ77 emite 1 literal seguido de 39 referências, cada uma copiando 258 bytes (o máximo) da posição anterior.
Incrível, não? 🤓
Por que o LZ77 não está no pipeline do JPEG?
Agora você pode estar se perguntando: se o LZ77 é tão poderoso, por que o JPEG não usa ele?
A resposta é que o JPEG já resolve o problema de outra forma. No pipeline do JPEG, a DCT + quantização transforma os dados de imagem em coeficientes com muitos zeros e valores repetitivos.
Esses dados já são altamente comprimíveis com RLE (pras sequências de zeros) + Huffman (pras frequências desiguais). Adicionar o LZ77 traria pouco ganho adicional e aumentaria a complexidade.
O LZ77 brilha quando os dados têm sequências longas que se repetem em posições distantes.
Em coeficientes DCT quantizados, as repetições tendem a ser curtas e locais (muitos zeros seguidos), o que é um tipo de coisa que o RLE já trata perfeitamente.
Já o PNG precisa do LZ77 porque ele é lossless, ou seja, não tem DCT nem quantização pra criar aquela avalanche de zeros. O PNG precisa comprimir os pixels "como estão" (depois dos filtros de predição), e o LZ77 + Huffman (DEFLATE) é a melhor ferramenta pra isso.
Compressores modernos: além do DEFLATE
Antes de fechar o artigo, quero te dar uma visão rápida dos algoritmos mais modernos que sucederam o DEFLATE. Não vamos nos aprofundar neles, mas é bom saber que existem:
Zstandard (zstd): Desenvolvido pelo Facebook em 2016 por Yann Collet. Usa LZ77 + uma técnica chamada ANS (Asymmetric Numeral Systems) em vez de Huffman.
Ele é significativamente mais rápido que o DEFLATE pra descomprimir e atinge taxas de compressão similares ou melhores. É usado no kernel do Linux, no Facebook/Meta, e está ganhando adoção rápida.
Brotli: Desenvolvido pelo Google em 2015. Usa LZ77 + Huffman + um dicionário estático pré-treinado com padrões comuns da web (tags HTML, código CSS, cabeçalhos HTTP).
Ele é especialmente bom pra comprimir conteúdo web. Muitos sites e CDNs já usam Brotli em vez de GZIP.
LZ4: Focado em velocidade acima de tudo. Comprime menos que o DEFLATE, mas descomprime a velocidades absurdas (vários GB/s).
Usado em sistemas de arquivos (ZFS), bancos de dados e jogos onde a velocidade de leitura é mais importante que o tamanho do arquivo.
LZMA (7-Zip): Usado no formato .7z. Usa uma variação do LZ77 com janela muito maior (até 4 GB!) e codificação aritmética.
Atinge taxas de compressão bem melhores que o DEFLATE, mas é mais lento pra comprimir. Bom pra arquivamento de longo prazo.
Todos esses algoritmos, sem exceção, são variações da mesma ideia fundamental: encontrar repetições (LZ77) + codificação de forma eficiente (Huffman/ANS/aritmética).
Se você entende o DEFLATE, entende a base de todos eles 😉
Resumo: fechando a Fase 2
Vamos recapitular tudo o que aprendemos neste artigo:
- LZ77 é um algoritmo de compressão lossless que substitui sequências repetidas por referências (distância, comprimento) a ocorrências anteriores.
- Ele usa uma janela deslizante pra limitar a busca por correspondências (no DEFLATE: janela de 32 KB).
- O truque de copiar de si mesmo (distância < comprimento) permite codificar padrões periódicos de forma muito eficiente.
- DEFLATE = LZ77 + Huffman: o LZ77 elimina repetições de sequências, e o Huffman comprime o resultado estatisticamente. Usado em ZIP, GZIP, PNG.
- O LZ77 não é usado no JPEG porque a DCT + quantização + RLE já resolvem o problema de forma mais adequada pra imagens lossy.
- Compressores modernos (zstd, Brotli, LZ4, LZMA) são variações do mesmo conceito fundamental, otimizadas pra diferentes trade-offs de velocidade e compressão.
E com isso, fechamos a Fase 2 — Fundamentos de Compressão! 🎉
Ao longo desses 4 artigos (artigos 4 a 7), construímos uma caixa de ferramentas sólida:
- Artigo 4: Entendemos o que é compressão, lossless vs lossy, redundância e entropia.
- Artigo 5: Aprendemos o RLE — compressão por repetições consecutivas.
- Artigo 6: Aprendemos o Huffman — compressão por códigos de tamanho variável.
- Artigo 7: Aprendemos o LZ77 e DEFLATE — compressão por referências ao passado.
No próximo artigo, entramos na Fase 3 — O Coração de um CODEC de Imagem, começando com ele: Dividindo a imagem em blocos (8×8, 16×16) e por que fazer isso?.
A partir de agora, tudo que aprendemos nas Fases 1 e 2 vai começar a se conectar.
Ou seja, a partir de agora nós iremos ver como a teoria se transforma na prática de um CODEC real. Prepare-se, porque a Fase 3 é onde as coisas ficam realmente interessantes 🚀

