


O que é compressão? Lossless vs Lossy, entropia e redundância
Olá leitor, seja muito bem vindo de volta a mais uma etapa da nossa jornada aqui no Portal da Micilini 😊
Este é o quarto artigo da nossa série de ~20, e marca o início de uma nova fase: a Fase 2 — Fundamentos de Compressão.
Nos 3 artigos anteriores (Fase 1 — Fundamentos Visuais), a gente construiu uma base sólida sobre como as cores funcionam, como o olho humano enxerga, o que é o RGB24, o YCbCr, e como o Chroma Subsampling já corta metade dos dados antes de qualquer truque sofisticado.
Mas o Chroma Subsampling sozinho não é suficiente, ele é apenas só o primeiro golpe.
Uma imagem Full HD que ocupa 5,93 MB em RGB24 cai pra ~2,97 MB depois do 4:2:0. Isso é bom, mas está longe dos ~185 KB que o JPEG consegue.
Então de onde vem o resto da compressão? Como é possível espremer uma imagem de quase 3 MB pra menos de 200 KB sem que o olho humano perceba a diferença?
A resposta está nos algoritmos de compressão. E antes de aprender qualquer algoritmo específico (RLE, Huffman, LZ77... que veremos nos próximos artigos), a gente precisa entender os conceitos fundamentais que fazem qualquer compressão funcionar.
Então pega seu café ☕, sente-se confortavelmente, e vamos entrar no mundo da compressão de dados!
O que é compressão, afinal?
Vamos começar do começo mesmo: o que significa "comprimir" dados?
Comprimir é o ato de pegar uma informação e representá-la usando menos dados do que a representação original, mantendo a possibilidade de recuperar a informação (total ou parcialmente) depois.
Parece simples, né? Mas pensa no que isso implica: você tem um arquivo de 1 MB e quer transformar ele em 200 KB. Isso significa que você precisa encontrar um jeito de dizer a mesma coisa (ou quase a mesma coisa) usando 5 vezes menos palavras.
Mas dai você pode estar se perguntando... isso é realmente possível? Como assim dizer a mesma coisa com menos dados? Não estamos violando alguma lei da física? 🤔
A resposta é: sim, é possível, e a razão é que a maioria dos dados que produzimos tem redundância. Ou seja, tem informação repetida ou previsível que pode ser eliminada sem perder o sentido.
Vou te dar um exemplo do dia a dia pra deixar isso mais concreto.
Imagine que você receba a seguinte mensagem de texto:
"Amanhã vou ao mercado. Amanhã vou comprar arroz. Amanhã vou comprar feijão. Amanhã vou comprar carne. Amanhã vou pagar com cartão."Essa mensagem tem 155 caracteres. Mas se você parar pra analisar, tem muita coisa repetida: "Amanhã vou" aparece 5 vezes, "comprar" aparece 3 vezes...
Um ser humano esperto reescreveria essa mensagem da seguinte forma:
"Amanhã vou ao mercado comprar arroz, feijão e carne. Pago no cartão."Agora temos 71 caracteres. Mesma informação, menos da metade do tamanho. Isso é o que eu chamo compressão 🤭
O que fizemos foi identificar a redundância (as repetições de "Amanhã vou", "comprar") e eliminar ela, mantendo a informação essencial.
Um computador faz exatamente a mesma coisa, só que de forma mecânica e usando algoritmos matemáticos em vez de intuição humana.
Redundância: a matéria-prima da compressão
Se compressão é o ato de reduzir dados, redundância é o que torna isso possível. Sem redundância, não tem o que comprimir.
Mas o que exatamente é redundância no contexto de dados? Existem 3 tipos principais, e entender cada um é fundamental pra entender como os CODECs funcionam:
Tipo 1 — Redundância Espacial (padrões que se repetem no espaço)
Esse tipo aparece quando pixels vizinhos têm valores parecidos. E adivinha? Na maioria das imagens do mundo real, isso acontece o tempo todo.
Pensa numa foto de um céu azul. São milhares de pixels com valores RGB quase idênticos (tipo 135, 180, 230... 136, 181, 231... 135, 179, 229...). Cada pixel é quase uma cópia do vizinho, com variações mínimas.
Em vez de armazenar cada pixel individualmente, seria muito mais eficiente dizer: "os próximos 500 pixels são azul-claro, com estas pequenas variações". Isso é explorar a redundância espacial.
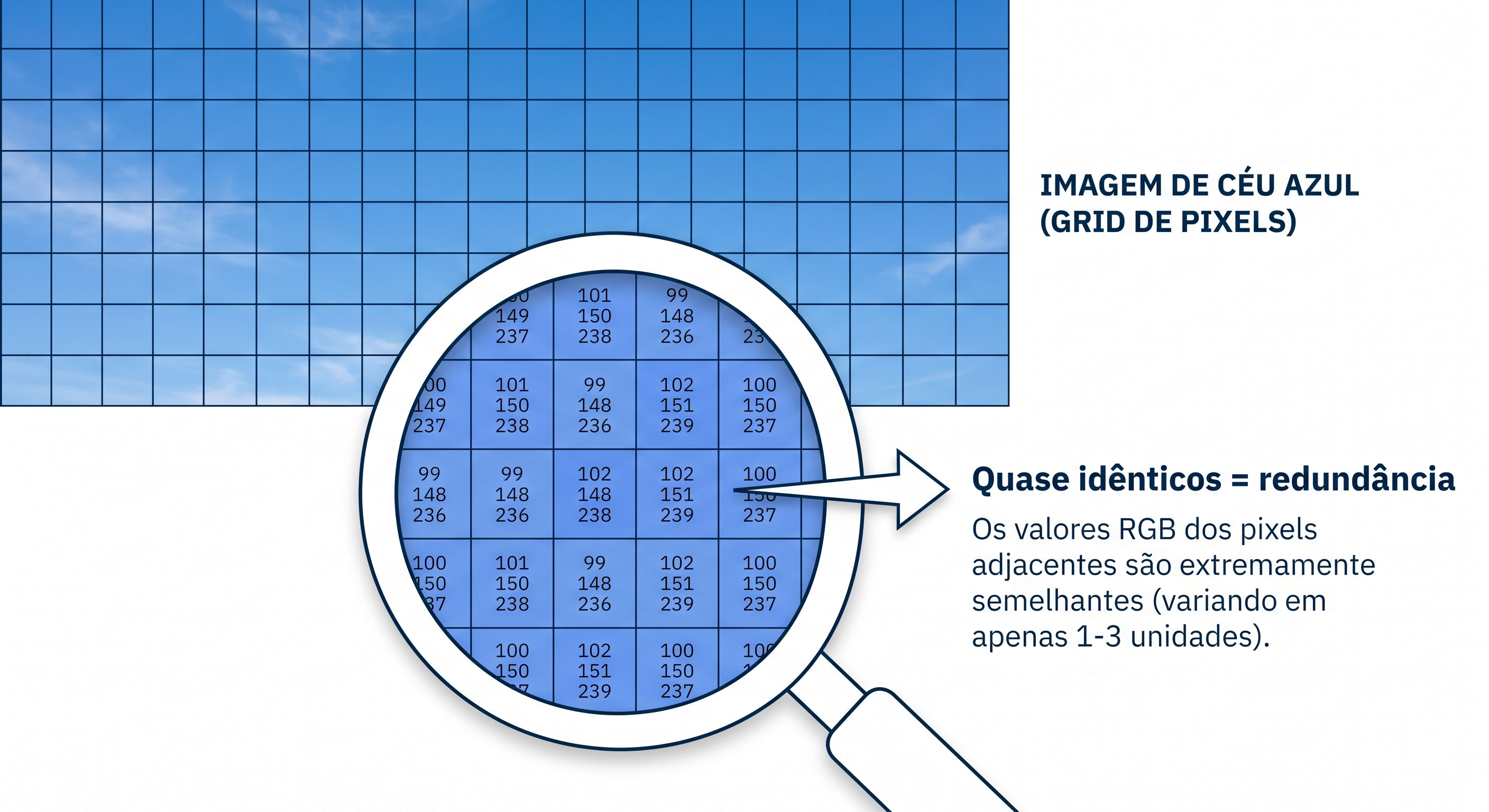
É como quando você vai contar pro seu amigo sobre uma parede branca. Você não diz: "o primeiro centímetro é branco, o segundo centímetro é branco, o terceiro centímetro é branco...". Você simplesmente diz: "a parede inteira é branca". Mesma informação, uma frase.
Tipo 2 — Redundância Temporal (padrões que se repetem no tempo)
Esse tipo é específico de vídeo, mas vale a pena mencionar porque quando chegarmos na Fase 5 da jornada (do CODEC de imagem ao CODEC de vídeo), ele vai ser essencial.
Pensa num vídeo de uma pessoa falando olhando pra câmera. De um frame pro seguinte, o que muda? O fundo é exatamente o mesmo, a roupa é a mesma, o cabelo quase não mexe. Só a boca e talvez os olhos mudam um pouquinho.
Em vez de armazenar cada frame completo (o que seria absurdamente caro), o CODEC de vídeo armazena o primeiro frame completo e depois, pros frames seguintes, armazena só o que mudou. Se 90% da imagem não mudou, só precisa gravar os 10% de diferença.
É como se você tivesse uma câmera de segurança filmando uma sala vazia. Seria um desperdício salvar 30 fotos por segundo de uma sala que não muda. Muito mais inteligente é salvar uma foto e depois só anotar: "nada mudou", "nada mudou", "ops, alguém entrou na sala, aqui está a diferença"...
Mas como eu disse, isso é papo pra Fase 5. Pro nosso CODEC de imagens, vamos focar nos outros dois tipos de redundância.
Tipo 3 — Redundância Estatística (padrões na frequência dos dados)
Esse é o tipo mais sutil e mais poderoso. Ele explora o fato de que nem todos os valores aparecem com a mesma frequência nos dados.
Imagine um texto em português. A letra "a" aparece com muito mais frequência do que a letra "z".
A letra "e" aparece mais que o "x". Se você usar o mesmo número de bits pra representar todas as letras (como a tabela ASCII faz, usando 8 bits pra cada caractere), você está "desperdiçando" bits nas letras comuns.
Uma ideia mais inteligente seria: usar poucos bits pra representar letras que aparecem muito (como "a", "e", "o") e mais bits pra representar letras raras (como "z", "x", "w"). No final, o total de bits usado seria menor do que se todas as letras tivessem o mesmo tamanho.
Essa é exatamente a ideia por trás da Codificação de Huffman, que vamos estudar em detalhes no artigo 6. Mas por enquanto, o importante é entender que essa desigualdade de frequências existe e pode ser explorada.
No caso de imagens, depois que o CODEC aplica a DCT e a quantização (que veremos na Fase 3), a maioria dos valores resultantes são zeros ou números muito pequenos. Valores grandes são raros. Essa desigualdade é a redundância estatística que permite comprimir ainda mais.
🧠 Resumindo os 3 tipos:
- Espacial: pixels vizinhos são parecidos → dá pra descrever regiões em vez de pixels individuais.
- Temporal: frames vizinhos são parecidos → dá pra armazenar só as diferenças (vídeo).
- Estatística: alguns valores aparecem mais que outros → dá pra usar menos bits pros valores comuns.
Lossless vs Lossy: as duas filosofias de compressão
Agora que você entende o que é redundância, vamos falar das duas grandes famílias de compressão que existem. Essa é provavelmente a distinção mais importante de toda a teoria de compressão.
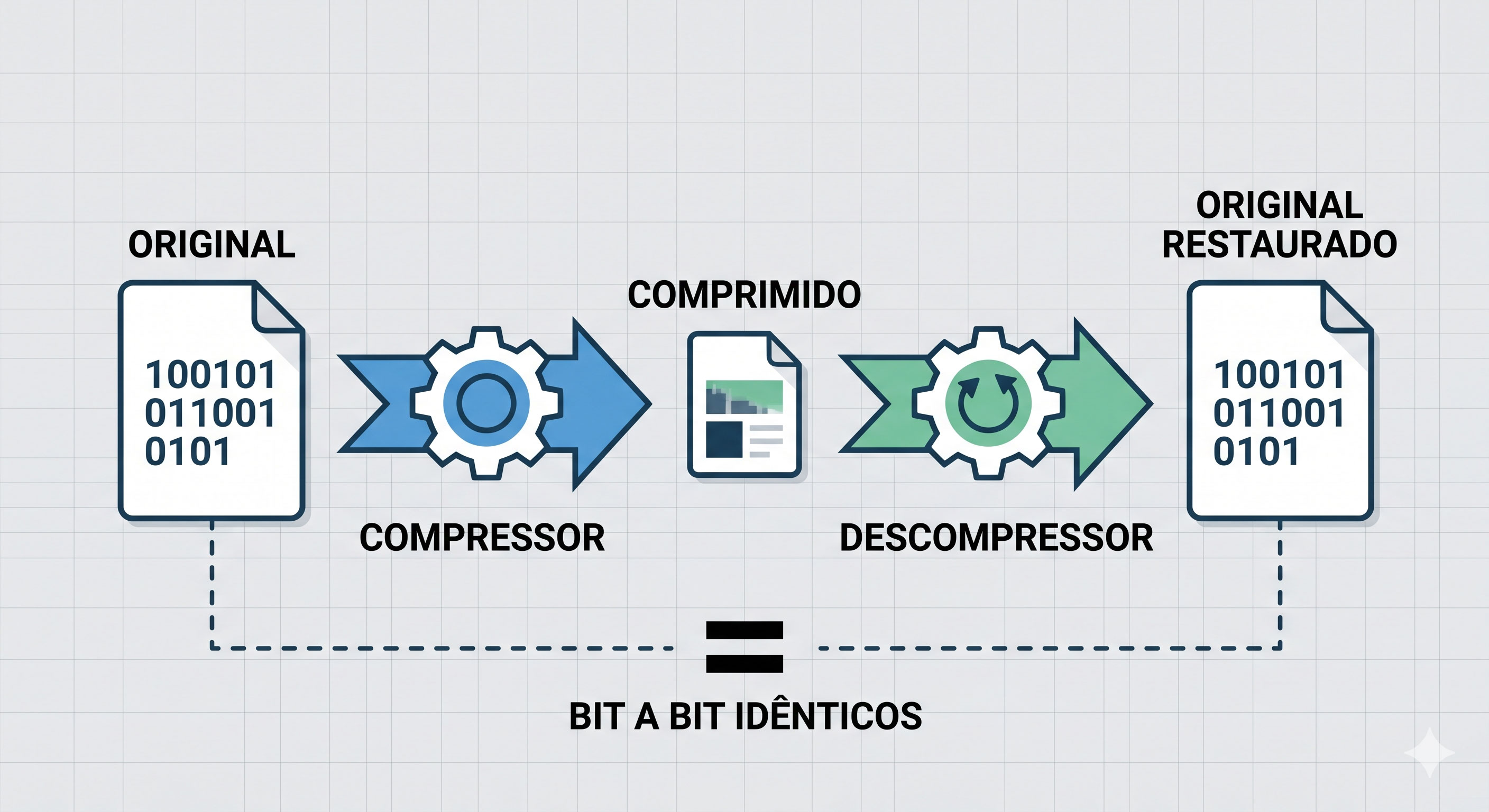
Compressão Lossless (sem perda):
Na compressão lossless, nenhum dado é perdido. Depois de comprimir e descomprimir, você tem exatamente os mesmos bytes que tinha antes. Bit por bit, idênticos.
É como aquela analogia da folha de papel A4 que fizemos no primeiro artigo1:
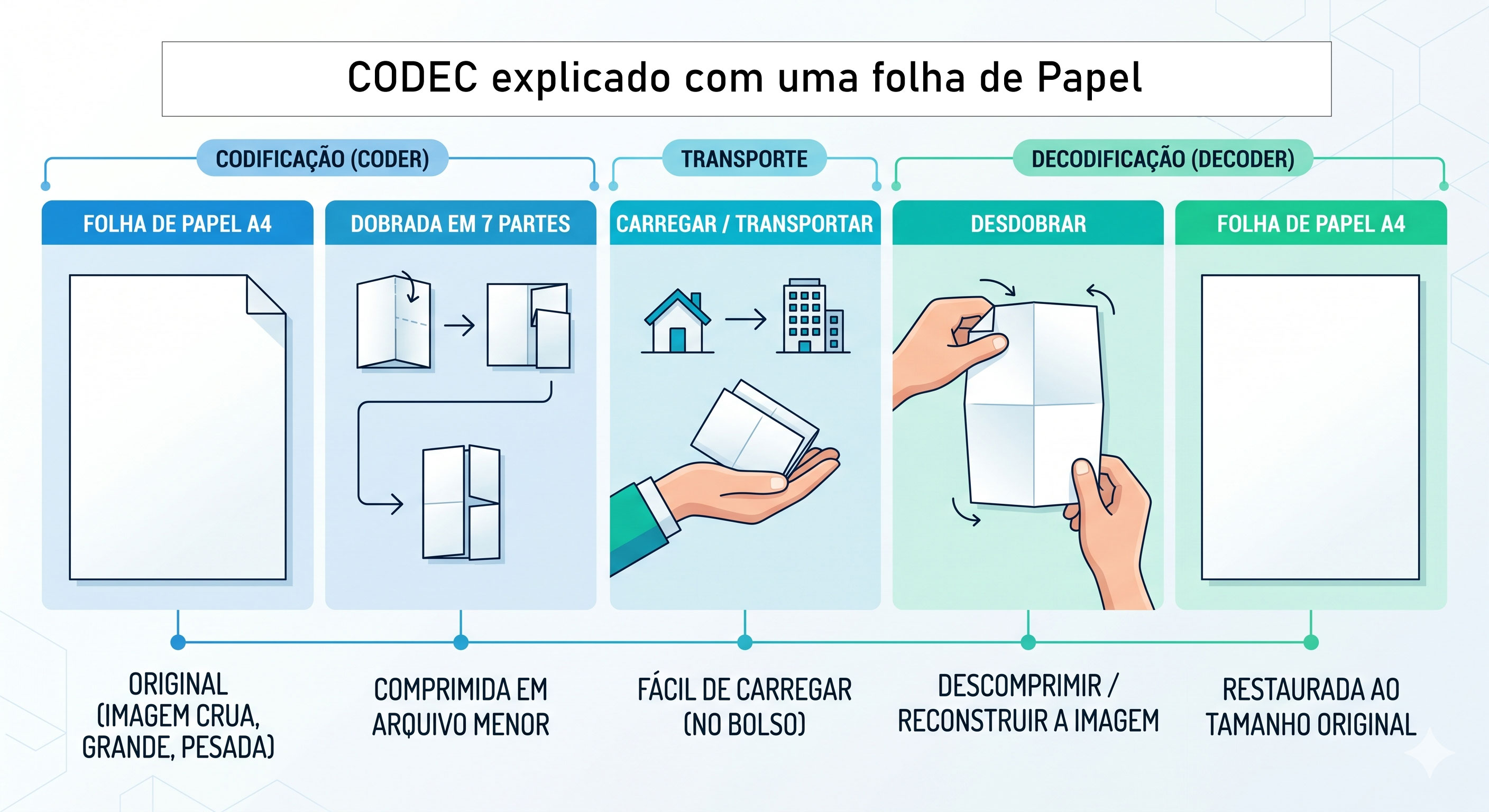
Você dobra a folha em 7 pedaços pra caber no bolso, e quando desdobra, a folha volta exatamente igual ao original (sem marcas de dobra).
No mundo real, compressão lossless é usada em:
- ZIP e RAR: quando você compacta um arquivo .zip, ao descompactar ele volta idêntico. Se fosse lossy, seus documentos Word e planilhas Excel poderiam sair corrompidos.
- PNG: o formato PNG usa compressão lossless. É por isso que ele é usado pra screenshots, logos e arte digital, onde cada pixel precisa estar exato.
- FLAC: formato de áudio lossless. Audiência que não aceita perder um único detalhe do som usa FLAC em vez de MP3.
- Código-fonte: imagine se o seu compilador recebesse um arquivo .c "comprimido com perda" e uma variável chamada
widthwdth
A vantagem do lossless é óbvia: qualidade perfeita, fidelidade total. A desvantagem é que a taxa de compressão é limitada. Dependendo dos dados, você consegue comprimir 30%, 50%, talvez 70%... mas dificilmente vai além disso.
Por quê? Porque existe um limite teórico de quanto você pode comprimir dados sem perder informação. Esse limite tem nome, e vamos falar dele daqui a pouco: ele é conhecido como entropia.
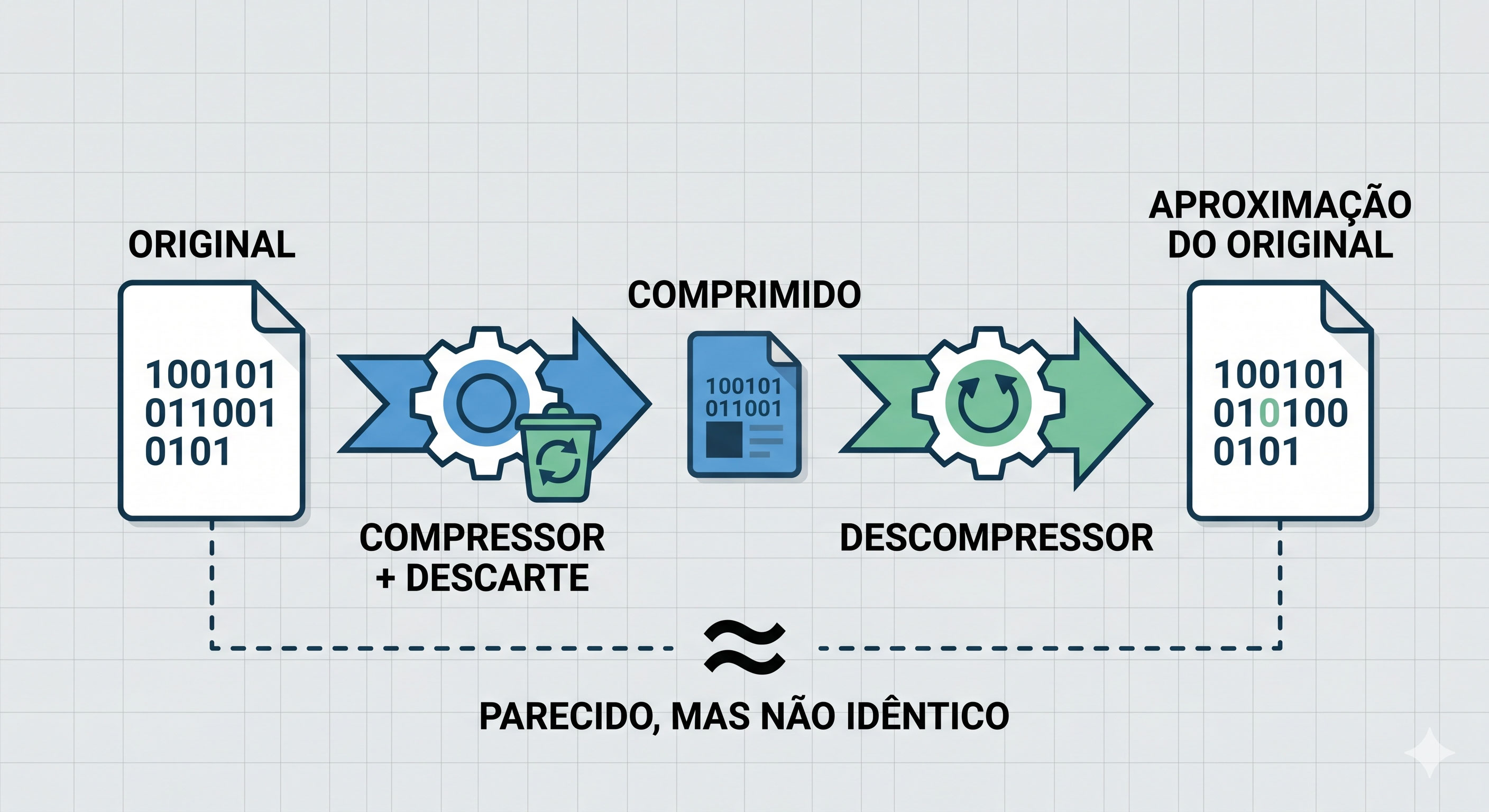
Compressão Lossy (com perda):
Na compressão lossy, parte dos dados é deliberadamente descartada durante a compressão. Depois de comprimir e descomprimir, o resultado é parecido com o original, mas não idêntico. Alguns detalhes foram perdidos no caminho, para sempre.
É como quando você tira uma xerox de uma xerox de uma xerox. Cada cópia perde um pouquinho de qualidade. As letras ficam mais borradas, as imagens ficam com menos contraste. A informação "essencial" está lá (você ainda consegue ler o texto), mas os detalhes finos desapareceram.
Mas peraí, por que alguém escolheria perder dados? Parece uma péssima ideia, né?
A razão é simples: a compressão lossy consegue taxas de compressão absurdamente maiores que a lossless. Enquanto a lossless comprime 30-70%, a lossy pode comprimir 90%, 95%, até 99% dos dados.
E aqui vem o pulo do gato: a perda é calculada e direcionada. O CODEC não joga fora qualquer dado aleatoriamente. Ele analisa o conteúdo e descarta especificamente as partes que o sistema sensorial humano (olho ou ouvido) dificilmente percebe.
Lembra do Chroma Subsampling que aprendemos no artigo anterior? Aquilo é compressão lossy! Estamos jogando fora 50% da informação de crominância e o olho quase não nota. O CODEC sabe que pode fazer isso porque conhece as limitações do olho humano.
No mundo real, compressão lossy é usada em:
- JPEG: o formato mais popular de fotos do mundo. Uma imagem que ocupa 6 MB em RGB24 cru pode cair pra 185 KB em JPEG com qualidade 80. Isso é uma redução de mais de 96%, e a foto continua bonita.
- MP3 e AAC: formatos de áudio lossy. Uma música que ocupa 50 MB em WAV (formato cru) cai pra ~5 MB em MP3 a 320kbps. O MP3 descarta frequências que o ouvido humano mal percebe (sons muito agudos, detalhes mascarados por sons mais fortes).
- H.264, H.265, AV1: CODECs de vídeo. Sem compressão lossy, um filme de 2 horas em 4K ocuparia centenas de gigabytes. Com H.265, cabe em ~5 GB num streaming da Netflix.
- WebP e AVIF: formatos modernos de imagem que usam técnicas lossy ainda mais avançadas que o JPEG.
E qual é a diferença visual entre os dois?
Pra você visualizar melhor, imagina que você tem uma foto de uma paisagem e aplica os dois tipos de compressão:
- Lossless (PNG): o arquivo fica menor (~60% do original), mas ao abrir, a imagem é pixel por pixel idêntica ao original. Se você comparar bit por bit, não encontra nenhuma diferença.
- Lossy (JPEG qualidade 50): o arquivo fica muito menor (~5% do original), mas ao dar um zoom pesado na imagem, você começa a ver uns quadradinhos borrados (artefatos de compressão), especialmente nas bordas entre cores diferentes e nas áreas com textura fina.
A pergunta que define qual tipo usar é simples:
➡️ Você precisa que o resultado seja idêntico ao original? Então vá de Lossless (ZIP, PNG, FLAC).
➡️ Você aceita uma qualidade "muito boa" em troca de um arquivo muito menor? Escolha então o Lossy (JPEG, MP3, H.264).
Pro nosso CODEC autoral, vamos usar compressão lossy, assim como o JPEG faz.
Mas vamos usar técnicas lossless também, porque na prática, os CODECs modernos combinam os dois: primeiro descartam dados de forma lossy (DCT + quantização), e depois comprimem o resultado de forma lossless (Huffman).
O espectro Lossless ↔ Lossy: não é preto e branco
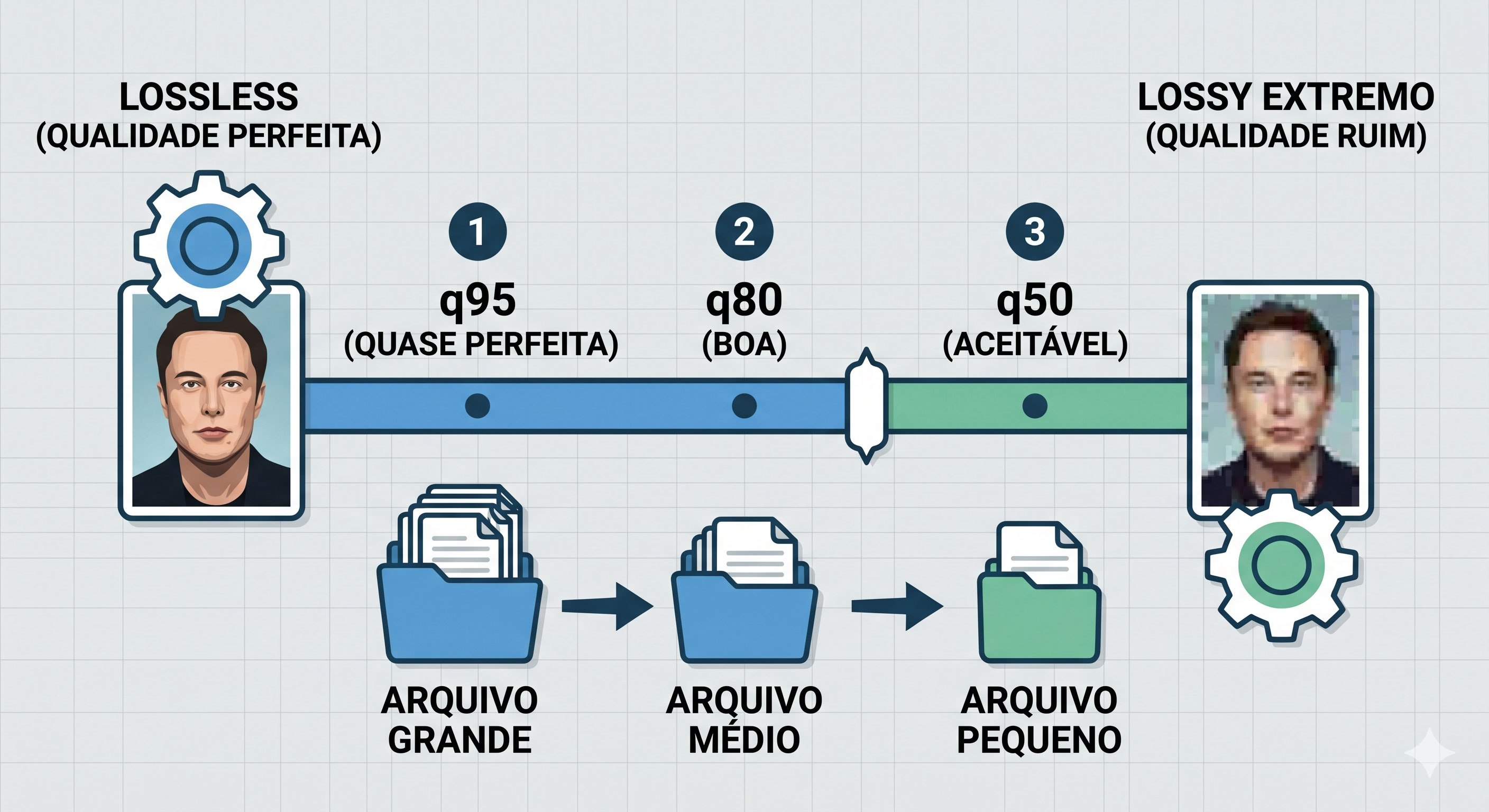
Uma coisa importante que muita gente não percebe: lossless e lossy não são dois mundos completamente separados. Eles formam um espectro contínuo.
No extremo lossless, você tem compressão limitada mas qualidade perfeita. No extremo lossy, você tem compressão máxima mas qualidade degradada. E no meio, existe um slider que você pode ajustar:
Qualidade 100% ←─────────────────────────────────────→ Tamanho mínimo
(Lossless) Lossy leve Lossy pesado (Lossy extremo)
PNG JPEG q95 JPEG q50 JPEG q5
~60% original ~15% orig ~5% orig ~1% orig
Perfeita Ótima Aceitável HorrívelE esse slider é exatamente o que você controla quando define o parâmetro de "qualidade" num CODEC.
Quando alguém salva um JPEG com "qualidade 80", está dizendo pro CODEC: "pode descartar até X% da informação, mas tenta manter um resultado visualmente bom".
O JPEG com qualidade 95 é quase lossless.
A diferença pro original é tão pequena que mesmo dando zoom pesado, muita gente não percebe. Mas com qualidade 5, a imagem vira uma sopa de quadradinhos.
💡 Curiosidade: O formato WebP do Google é interessante porque suporta tanto lossless quanto lossy no mesmo formato. Você pode salvar um WebP lossless (como PNG) ou lossy (como JPEG), dependendo do que precisa. O JPEG só suporta lossy, e o PNG só suporta lossless. E essa funcionalidade é uma das grandes vantagens do WebP.
Entropia: o limite teórico da compressão
Agora vamos falar do conceito mais "teórico" desse artigo, mas também um dos mais importantes: a entropia.
Não se assuste com o nome. Apesar de soar como algo de física quântica, a entropia na teoria da informação é um conceito bem mais simples do que parece.
A entropia foi definida por Claude Shannon em 1948, num paper que é considerado o nascimento da Teoria da Informação.
Shannon trabalhava nos Bell Labs (o laboratório de pesquisa da AT&T, a empresa de telefonia americana), e estava tentando resolver um problema prático:
Qual é a forma mais eficiente de transmitir informação por um canal de comunicação (tipo uma linha telefônica)?
O que ele descobriu mudou o mundo: ele definiu matematicamente o conceito de informação e provou que existe um limite mínimo de bits necessários pra representar uma mensagem. Esse limite é a entropia.
Mas calma, antes de falar de fórmulas, vamos entender a intuição por trás da entropia.
Entropia é a medida de "surpresa" ou "incerteza" de uma informação.
Quanto mais previsível uma mensagem é, menos informação ela carrega, e portanto menos bits são necessários pra representá-la.
Quanto mais imprevisível e surpreendente, mais informação ela carrega, e mais bits são necessários.
Parece abstrato? Relaxa, toma mais um gole de café, e vamos ver alguns exemplos concretos.
Exemplo 1 — Entropia baixa (mensagem previsível):
Imagine que todo dia, às 7h da manhã, seu amigo te manda uma mensagem. Todo santo dia ele manda exatamente a mesma coisa: "Bom dia".
Ele faz isso sem nenhuma exceção, durante 3 anos consecutivos rs
Quando o celular apita às 7h, qual é a sua "surpresa" ao ler a mensagem? Zero! Você já sabia o que ia ser. A mensagem é 100% previsível.
Em termos de teoria da informação, essa mensagem tem entropia zero (ou quase zero).
Ela não traz informação nova. Você poderia comprimir 3 anos de mensagens "Bom dia" numa única regra: "todo dia às 7h: Bom dia". Compressão de 99.99%.
Exemplo 2 — Entropia alta (mensagem imprevisível):
Agora imagine que todo dia, às 7h, seu amigo te manda uma mensagem completamente aleatória.
Um dia é "O gato comeu meu dever", no outro é "Comprei 47 melancias", no outro é "A capital do Nepal é Katmandu". Zero padrão, zero previsibilidade.
Quando o celular apita às 7h, você não faz ideia do que vai ler. Cada mensagem é uma surpresa total. Essa sequência tem entropia alta. Cada mensagem carrega o máximo de informação possível.
Comprimir isso é difícil, porque não tem padrão pra explorar. Cada mensagem é única e imprevisível.
Exemplo 3 — Entropia média (mensagem parcialmente previsível):
Na vida real, a maioria das informações está no meio.
Seu amigo manda mensagens em português, então você sabe que vai usar o alfabeto latino, que "q" geralmente é seguido de "u", que frases geralmente começam com maiúscula, que certas palavras são mais comuns que outras...
Existe alguma previsibilidade (redundância), mas não total. Dá pra comprimir, mas até um certo ponto.
🧠 A grande sacada de Shannon: Ele provou matematicamente que a entropia define o limite absoluto de compressão lossless. Nenhum algoritmo, por mais inteligente que seja, consegue comprimir dados abaixo da entropia deles.
Se a entropia de um conjunto de dados diz "você precisa de no mínimo 4.5 bits por símbolo pra representar isso", nenhum algoritmo vai conseguir fazer em 4 bits. É um limite da matemática, não da tecnologia.
Mas qualquer algoritmo pode chegar perto desse limite.
O Huffman chega bem perto. A codificação aritmética chega ainda mais perto. E o objetivo de todo algoritmo de compressão lossless é se aproximar o máximo possível da entropia.
A fórmula da entropia (sem pânico, agora, ok?!)
Pra quem tem curiosidade, aqui vai a fórmula que Shannon definiu. Se não curtir matemática, pode pular essa seção sem problemas, a intuição que já vimos é suficiente pro nosso CODEC.
A entropia H de uma fonte de informação é:
H = -Σ p(x) × log₂(p(x))Onde:
- Σ (sigma) significa "some pra todos os símbolos possíveis"
- p(x) é a probabilidade de cada símbolo x aparecer
- log₂ é o logaritmo na base 2 (porque estamos trabalhando com bits)
Vamos calcular com um exemplo simples.
Imagine que você tem um dado de 4 faces (um tetraedro), e cada face tem uma letra:
- Face A → aparece 50% das vezes (p = 0.5)
- Face B → aparece 25% das vezes (p = 0.25)
- Face C → aparece 12.5% das vezes (p = 0.125)
- Face D → aparece 12.5% das vezes (p = 0.125)
Colocando isso na formula, nós temos:
H = -(0.5 × log₂(0.5)) - (0.25 × log₂(0.25)) - (0.125 × log₂(0.125)) - (0.125 × log₂(0.125))
H = -(0.5 × (-1)) - (0.25 × (-2)) - (0.125 × (-3)) - (0.125 × (-3))
H = 0.5 + 0.5 + 0.375 + 0.375
H = 1.75 bits por símboloIsso significa que, na melhor compressão lossless possível, cada símbolo dessa fonte precisa de no mínimo 1.75 bits pra ser representado.
Se usássemos um código de tamanho fixo (2 bits pra cada símbolo, porque temos 4 símbolos), gastaríamos 2 bits por símbolo. Mas a entropia diz que dá pra fazer em 1.75 bits.
Isso é uma economia de 12.5%!
E como fazemos isso na prática? Usando códigos de tamanho variável: a letra A (que aparece mais) recebe um código curto (1 bit), e as letras raras recebem códigos mais longos (3 bits). Na média, gastamos menos bits por símbolo.
Essa é exatamente a ideia da Codificação de Huffman, que vamos implementar no artigo 6. A fórmula de Shannon nos diz qual é o alvo teórico, e o Huffman nos dá um algoritmo prático pra chegar perto dele.
Agora, a comparação: se todas as 4 faces tivessem a mesma probabilidade (25% cada), a entropia seria:
H = -(4 × 0.25 × log₂(0.25))
H = -(4 × 0.25 × (-2))
H = 2.0 bits por símboloEntropia máxima: 2 bits. Não dá pra comprimir nada, porque não tem padrão, não tem redundância. Cada símbolo é igualmente provável. Esse é o cenário de dados perfeitamente aleatórios.
🎯 Regra de ouro: Quanto mais desigual a distribuição de probabilidades (quanto mais "tendenciosa"), menor a entropia e maior o potencial de compressão. Quanto mais uniforme (quanto mais "aleatória"), maior a entropia e menor o potencial.
Agora chega de papo e vamos analisar alguns exemplos do mundo real 😉
Exemplo 1 — O semáforo da esquina
Imagina o semáforo perto da sua casa. Ele tem 3 cores, mas elas não aparecem em proporções iguais:
- 🟢 Verde → fica 50% do tempo (p = 0.5)
- 🔴 Vermelho → fica 35% do tempo (p = 0.35)
- 🟡 Amarelo → fica 15% do tempo (p = 0.15)
Se você fosse registrar o estado do semáforo a cada segundo durante o dia inteiro, quanto de espaço precisaria?
Com código fixo, como temos 3 cores, precisaríamos de 2 bits por registro (porque 1 bit dá só 2 combinações, e a gente precisa de pelo menos 3). Então cada segundo custa 2 bits.
Mas vamos calcular a entropia:
H = -(0.5 × log₂(0.5)) - (0.35 × log₂(0.35)) - (0.15 × log₂(0.15))
H = -(0.5 × (-1)) - (0.35 × (-1.515)) - (0.15 × (-2.737))
H = 0.5 + 0.530 + 0.411
H = 1.44 bits por registroA entropia diz que dá pra representar cada estado do semáforo usando apenas 1.44 bits em média, em vez de 2 bits. Isso é uma economia de 28%!
Como? Dando um código curtinho pro verde (que aparece metade do tempo) e códigos maiores pro amarelo (que aparece pouco):
Verde → 0 (1 bit) — aparece 50% do tempo
Vermelho → 10 (2 bits) — aparece 35% do tempo
Amarelo → 11 (2 bits) — aparece 15% do tempoNa média: 0.5×1 + 0.35×2 + 0.15×2 = 0.5 + 0.7 + 0.3 = 1.5 bits por registro. Bem perto dos 1.44 teóricos!
Exemplo 2 — As letras de uma frase
Imagina que alguém te manda uma mensagem que é só a palavra "BANANA" repetida 1000 vezes. Vamos olhar quais letras aparecem nessa mensagem:
- A → aparece 3 vezes a cada 6 letras = 50% (p = 0.5)
- N → aparece 2 vezes a cada 6 letras = 33.3% (p = 0.333)
- B → aparece 1 vez a cada 6 letras = 16.7% (p = 0.167)
São só 3 letras diferentes! Se usássemos ASCII (8 bits por letra), cada letra custaria 8 bits. Absurdo. Mesmo com código fixo de 2 bits (porque temos 3 símbolos), já seria um baita desperdício.
A entropia diz:
H = -(0.5 × log₂(0.5)) - (0.333 × log₂(0.333)) - (0.167 × log₂(0.167))
H = -(0.5 × (-1)) - (0.333 × (-1.585)) - (0.167 × (-2.585))
H = 0.5 + 0.528 + 0.431
H = 1.46 bits por letraDe 8 bits (ASCII) pra 1.46 bits por letra. Isso é uma redução de 82%! E faz sentido, porque a mensagem é super previsível (tem só 3 letras, e uma delas aparece metade do tempo).
Exemplo 3 — O tempo na sua cidade
Imagina que você mora numa cidade do Nordeste onde quase nunca chove. Você anota o tempo todo dia durante um ano:
- ☀️ Sol → 300 dias por ano = 82.2% (p = 0.822)
- ☁️ Nublado → 45 dias por ano = 12.3% (p = 0.123)
- 🌧️ Chuva → 20 dias por ano = 5.5% (p = 0.055)
Calculando a entropia:
H = -(0.822 × log₂(0.822)) - (0.123 × log₂(0.123)) - (0.055 × log₂(0.055))
H = -(0.822 × (-0.283)) - (0.123 × (-3.024)) - (0.055 × (-4.184))
H = 0.233 + 0.372 + 0.230
H = 0.835 bits por diaMenos de 1 bit por dia! Tipo de coisa que faz totla sentido, pois o tempo nessa cidade é tão previsível (sol, sol, sol, sol...) que quase não carrega informação.
Se alguém te perguntar "como tá o tempo aí?", você responde "sol" sem nem olhar pela janela, e vai acertar 82% das vezes.
Agora compara com São Paulo, onde o tempo é caótico:
- ☀️ Sol → 30% (p = 0.30)
- ☁️ Nublado → 30% (p = 0.30)
- 🌧️ Chuva → 25% (p = 0.25)
- ⛈️ Tempestade → 15% (p = 0.15)
H = -(0.30 × (-1.737)) - (0.30 × (-1.737)) - (0.25 × (-2.0)) - (0.15 × (-2.737))
H = 0.521 + 0.521 + 0.500 + 0.411
H = 1.95 bits por diaQuase 2 bits por dia. O tempo em SP carrega muito mais informação (mais surpresa, mais incerteza), então precisa de mais bits pra ser registrado. É mais difícil de comprimir porque é menos previsível.
Exemplo 4 — Os pixels de uma foto de céu
E agora o exemplo que mais importa pra gente: pixels de uma imagem.
Imagina que você pegou uma região de 100 pixels do céu azul de uma foto. Os valores do canal azul (B) desses pixels são:
230, 231, 230, 232, 230, 231, 230, 230, 231, 230,
232, 230, 231, 230, 230, 230, 231, 232, 230, 230...Contando as frequências:
- 230 → aparece 55% das vezes (p = 0.55)
- 231 → aparece 30% das vezes (p = 0.30)
- 232 → aparece 15% das vezes (p = 0.15)
Formula da Entropia:
H = -(0.55 × log₂(0.55)) - (0.30 × log₂(0.30)) - (0.15 × log₂(0.15))
H = -(0.55 × (-0.862)) - (0.30 × (-1.737)) - (0.15 × (-2.737))
H = 0.474 + 0.521 + 0.411
H = 1.41 bits por pixelCada pixel nessa região deveria ocupar 8 bits (porque o canal vai de 0 a 255). Mas a entropia diz que dá pra representar com apenas 1.41 bits. Isso é uma economia de 82%!
E por que a entropia é tão baixa? Porque o céu é absurdamente previsível: é tudo 230, 231, 232... quase o mesmo valor repetido.
Agora imagina uma região de 100 pixels de grama com folhas, sombras e texturas. Os valores do canal verde (G) seriam algo como: 87, 142, 65, 201, 33, 178, 95, 112... Muito mais variação, muito menos previsibilidade. A entropia seria alta (perto de 7 ou 8 bits por pixel), e a compressão seria bem menor.
É exatamente por isso que fotos de céu limpo comprimem muito melhor que fotos de floresta densa. A floresta tem mais "informação" (mais detalhes, mais variação), e portanto precisa de mais bits pra ser representada.
Entropia em imagens: onde a mágica acontece
Agora vamos conectar tudo isso com imagens, que é o que nos interessa para o nosso CODEC ✨
Uma imagem em RGB24 com valores aleatórios (ruído estático, tipo aquela "chuva" de TV antiga) tem entropia muito alta.
Cada pixel é imprevisível, não tem padrão, não tem redundância. Tentar comprimir ruído puro é quase impossível.
O arquivo comprimido pode até ficar maior que o original (porque o algoritmo gasta bits tentando encontrar padrões que não existem).
Já uma imagem do mundo real (uma foto de paisagem, um retrato, uma foto de comida) tem entropia bem mais baixa que ruído. Por quê?
Porque fotos reais têm muita redundância:
- O céu é uma região enorme de pixels quase iguais (redundância espacial alta)
- As sombras mudam gradualmente, sem saltos bruscos
- As cores de pele são um grupo restrito de valores (tons de bege/marrom)
- Os detalhes finos (textura de tecido, folhas de árvore) ocupam proporcionalmente pouca área da imagem

Mas aqui vem uma sacada importante: a entropia de uma imagem muda dependendo de como você representa ela.
Quando a imagem está em RGB24 puro, a entropia é relativamente alta, porque os 3 canais estão misturados e cada pixel tem 3 valores semi-independentes.
Mas depois que o CODEC aplica o pipeline de compressão (YCbCr → Chroma Subsampling → DCT → Quantização), os dados resultantes ficam com uma distribuição de probabilidades muito desigual: a grande maioria dos valores são zeros ou números pequenos, e valores grandes são raríssimos.
Isso significa que a entropia caiu drasticamente depois dessas transformações. E aí o algoritmo de compressão lossless final (Huffman) consegue espremer os dados pra muito perto do limite teórico.
É como se cada etapa do pipeline fosse preparando o terreno pro Huffman trabalhar.
O Chroma Subsampling remove redundância visual. A DCT reorganiza a informação. A quantização zera os valores irrelevantes. E o Huffman termina o serviço comprimindo a distribuição desigual resultante.
Cada peça do quebra-cabeça tem seu papel, e é por isso que elas são estudadas na ordem que estamos seguindo.
Compressão no dia a dia: exemplos que você já usa
Antes de seguir pra parte mais técnica, quero te mostrar como compressão está presente em praticamente tudo que você faz no dia a dia.
Muita gente não percebe, mas sem compressão, a internet como conhecemos simplesmente não existiria.
Quando você manda um áudio no WhatsApp:
Seu celular grava a sua voz em áudio digital bruto (PCM), que ocuparia uns 1.4 MB por segundo.
Um áudio de 30 segundos seria ~42 MB. Mas o WhatsApp aplica o CODEC de áudio Opus, que comprime isso pra mais ou menos ~250 KB.
Sem compressão, cada áudio de 30 segundos consumiria 42 MB da sua franquia de dados. Imagina sua internet 4G acabando depois de 10 áudios 😱
Quando você assiste uma live na Twitch:
Supondo que o seu streamer favorito está transmitindo vídeo a 1080p60fps. Em RGB24 cru, isso seria:
1920 × 1080 × 3 bytes × 60 frames = 373.248.000 bytes/segundo ≈ 356 MB/sIsso daria 1.28 TB por hora, então... Boa sorte fazendo stream com essa conexão de internet 😅
Com H.264, a mesma live é transmitida a mais ou menos ~6 Mbps (0.75 MB/s). Isso é uma compressão de 475 vezes! De 356 MB/s pra 0.75 MB/s.
Quando você salva uma foto no celular:
A câmera captura a imagem em formato RAW (parecido com RGB24, mas com mais bits). Uma foto 12MP em RAW ocupa ~24 MB.
O processador do celular aplica o CODEC JPEG (ou HEIF nos iPhones mais recentes), e a foto cai pra ~3 MB.
Se seu celular de 128 GB armazenasse fotos em RAW, caberiam ~5.300 fotos. Com JPEG, cabem ~42.000. A compressão multiplicou sua capacidade por 8.
Quando você faz um backup no Google Drive:
Os arquivos são comprimidos com algoritmos lossless (como DEFLATE/LZ77) antes de serem enviados. Isso reduz o tempo de upload e o espaço ocupado na nuvem.
Os limites da compressão e o famoso paradoxo do pombo 🕊️
Aqui vai um conceito divertido que ajuda a fixar por que a compressão tem limites.
Imagine que você invente um algoritmo milagroso de compressão que consiga pegar qualquer arquivo e reduzir ele em pelo menos 1 bit. Parece pouco, né? Só 1 bit a menos.
Mas pensa no que isso implica:
- Um arquivo de 8 bits poderia ser comprimido pra 7 bits
- Esse de 7 bits poderia ser comprimido pra 6 bits
- Esse de 6 pra 5...
- E assim por diante, até chegar em... 0 bits!
Ou seja, qualquer arquivo do universo poderia ser comprimido até desaparecer. Claramente isso é impossível 😂
Esse argumento é uma versão informal do Princípio da Casa dos Pombos (Pigeonhole Principle) aplicado à compressão. A ideia formal é:
Existem 2⁸ = 256 arquivos possíveis de 8 bits. Se eu comprimir todos pra 7 bits, tenho espaço pra apenas 2⁷ = 128 arquivos diferentes.
Mas tenho 256 arquivos pra mapear.
Pelo princípio dos pombos, pelo menos 2 arquivos diferentes teriam que ser comprimidos pro mesmo resultado de 7 bits.
E aí, na hora de descomprimir, como o algoritmo saberia qual dos dois originais restaurar?
Resultado: não existe algoritmo de compressão lossless que funcione pra todos os inputs.
Todo algoritmo que comprime bem certos tipos de dados necessariamente "expande" outros tipos.
Na prática, isso significa que:
- O ZIP comprime texto muito bem, mas mal consegue comprimir um JPEG (porque o JPEG já foi comprimido, não tem mais redundância pra explorar)
- Comprimir um PNG com ZIP quase não reduz o tamanho (PNG já usa DEFLATE internamente)
- Dados aleatórios (como um arquivo de bytes gerados por /dev/urandom) são incomprimíveis, ou seja, o arquivo comprimido pode ficar até maior que o original
🧠 Regra prática: Se um arquivo já foi comprimido por um bom algoritmo, tentar comprimir de novo não ajuda (e pode até piorar). É por isso que zipar um JPEG não reduz quase nada.
Se um dia você criar uma aplicação que faz compressão, lembre-se da regra prática acima.
Juntando tudo: como o CODEC combina Lossy + Lossless
Antes de fechar o artigo, quero te dar a visão panorâmica de como um CODEC real (como o JPEG, e como o nosso futuro N.148i) usa ambos os tipos de compressão em sequência.
O pipeline completo funciona assim:
Imagem RGB24 original (5.93 MB)
│
▼
[RGB → YCbCr] ← Reorganização (sem perda)
│
▼
[Chroma Subsampling] ← LOSSY (descarta crominância, -50%)
│ ~2.97 MB
▼
[DCT em blocos 8×8] ← Transformada (sem perda)
│
▼
[Quantização] ← LOSSY (zera coeficientes irrelevantes)
│ Entropia cai drasticamente
▼
[Huffman / Entropia] ← LOSSLESS (comprime a distribuição desigual)
│
▼
Arquivo JPEG final (~185 KB)Percebe como as etapas lossy (Chroma Subsampling e Quantização) vêm antes da etapa lossless (Huffman)?
Isso não é coincidência. As etapas lossy têm dois trabalhos:
- Descartar informação que o olho não percebe (redução direta de dados)
- Preparar os dados pra que a etapa lossless funcione melhor (redução de entropia)
A quantização, por exemplo, transforma muitos coeficientes pequenos em zeros. Isso cria uma distribuição de probabilidades extremamente desigual (muitos zeros, poucos valores grandes), que é exatamente o cenário onde o Huffman brilha.
É como se as etapas lossy fossem um time de limpeza que organiza e simplifica a bagunça, e o Huffman fosse o cara que empacota tudo na caixa final. Quanto mais organizada a bagunça está quando chega pro Huffman, mais compacta fica a caixa.
No nosso CODEC futuro, nós vamos implementar cada uma dessas etapas uma por uma, nos próximos artigos 😉
Resumo: os pilares da compressão
Vamos recapitular tudo o que aprendemos neste artigo:
1) Compressão é o ato de representar informação usando menos dados que a representação original.
2) Redundância é a matéria-prima da compressão. Existem 3 tipos: espacial (pixels vizinhos parecidos), temporal (frames vizinhos parecidos, pra vídeo), e estatística (alguns valores aparecem mais que outros).
3) Lossless (sem perda) preserva os dados originais bit a bit. Usado em ZIP, PNG, FLAC. Taxa de compressão limitada.
4) Lossy (com perda) descarta dados intencionalmente. Usado em JPEG, MP3, H.264. Taxa de compressão muito alta, mas qualidade não é perfeita.
5) Entropia é o limite teórico mínimo de bits necessários pra representar uma informação (definida por Claude Shannon em 1948). Nenhum algoritmo lossless consegue ir abaixo da entropia.
6) Entropia baixa (dados previsíveis, redundantes) = fácil de comprimir. Entropia alta (dados aleatórios, imprevisíveis) = difícil de comprimir.
7) O Princípio da Casa dos Pombos prova que não existe compressor universal: todo algoritmo que comprime bem certos dados necessariamente falha em outros.
8) CODECs reais combinam lossy + lossless: as etapas lossy descartam dados imperceptíveis E reduzem a entropia, e a etapa lossless final comprime o resultado pra perto do limite teórico.
No próximo artigo, vamos colocar a mão na massa e aprender a primeira técnica de compressão concreta: RLE (Run-Length Encoding).
Ela é uma das técnica mais simples e intuitivas que existem, que vai te mostrar na prática como a redundância é explorada pra reduzir dados.
A jornada continua, e a partir de agora cada artigo vai te dar uma ferramenta nova pra sua caixa de ferramentas de compressão 🚀

