


RLE (Run-Length Encoding): sua primeira técnica de compressão
Olá leitor, seja muito bem vindo de volta a mais uma etapa da nossa jornada aqui no Portal da Micilini 😊
Este é o quinto artigo da nossa série de ~20, e o segundo da Fase 2 — Fundamentos de Compressão.
No artigo anterior, a gente entendeu os conceitos fundamentais, onde vimos um pouco mais sobre o que é compressão, a diferença entre lossless e lossy, o que é redundância, e o que é entropia.
Porém, vimos tudo aquilo dentro de conceitos muito teóricos, com pouquíssimo código, sem nenhuma implementação.
Pois bem, acabou a moleza 😄
A partir de agora, vamos começar a colocar a mão na massa e aprender técnicas concretas de compressão.
E a primeira delas é a mais simples, mais intuitiva e mais fácil de entender que existe: o RLE (Run-Length Encoding), ou em português, Codificação por Comprimento de Sequência.
O RLE é tão simples que você provavelmente já usou a lógica dele na vida real sem saber.
E apesar de ser "básico", ele é usado de verdade em formatos reais como o BMP, o PCX, o fax (sim, aquela máquina de fax do escritório), e até como parte interna de CODECs mais complexos.
Então pega seu café ☕, sente-se confortavelmente, e vamos aprender a sua primeira técnica de compressão de dados!
A ideia de compressão de dados mais simples do mundo
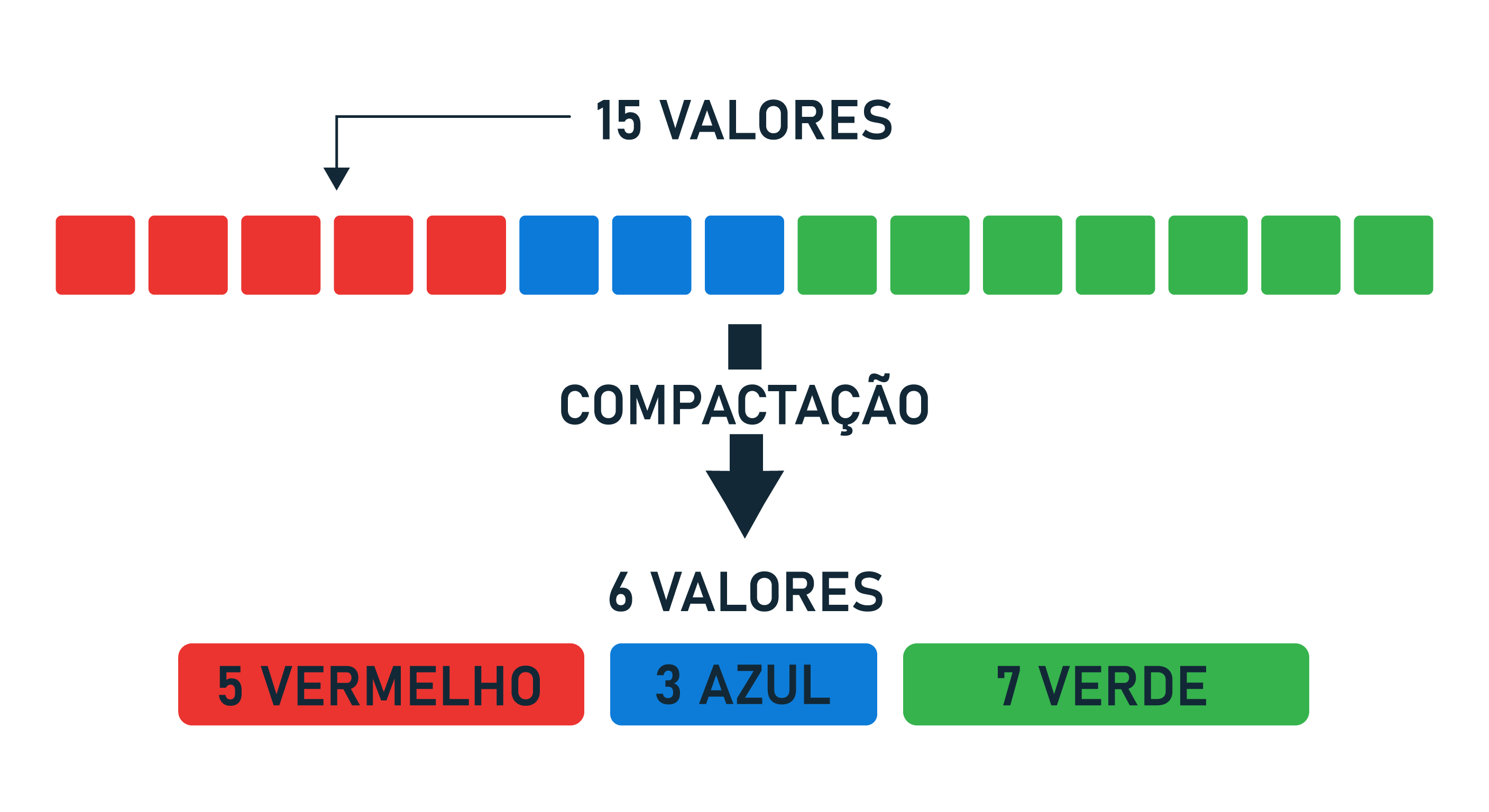
Imagina que eu te peça pra anotar a seguinte sequência de cores num papel:
vermelho, vermelho, vermelho, vermelho, vermelho, azul, azul, azul, verde, verde, verde, verde, verde, verde, verdeQuantas palavras você precisou escrever naquele papel?
Obviamente que 15, ou seja, uma pra cada item da sequência.
Agora, se eu te pedisse pra anotar a mesma informação de um jeito mais "esperto", o que você faria?
Provavelmente você poderia fazer algo assim:
5× vermelho, 3× azul, 7× verdeNo final, você teria 6 "palavras" (3 contagens + 3 cores) em vez de 15. Mesma informação, menos da metade do tamanho. E você consegue reconstruir a sequência original perfeitamente a partir dessa anotação.
Isso meus amigos é o que eu chamo de RLE 😁
A ideia é absurdamente simples: em vez de armazenar cada valor individualmente, você armazena quantas vezes ele se repete em sequência, seguido do valor em si.
O nome "Run-Length Encoding" vem exatamente dessa ideia, vejamos:
- Run = uma "corrida" de valores iguais consecutivos
- Length = o comprimento (quantas vezes) dessa corrida
- Encoding = a forma de codificar isso
Sendo assim, podemos dizer que o termo "5× vermelho", nada mais é do que um run de comprimento (length) onde o vermelho deve se repetir 5 vezes. Simples assim.
RLE em bytes: como funciona no computador?
É claro que o nosso computador n~~ao trabalha com "vermelho", "verde" ou "azul". No caso dele, ele trabalha com bytes de informação (valores de 0 a 255).
Imagine a seguinte sequência de bytes, representando, por exemplo, uma linha de pixels como na representação abaixo:
Dados originais: 45 45 45 45 45 45 120 120 120 200 200 200 200 200 200 200 200Contando: o valor 45 aparece 6 vezes seguidas, depois 120 aparece 3 vezes, depois 200 aparece 8 vezes.
No total são 17 bytes de dados originais.
Com RLE, codificamos assim:
Dados comprimidos: [6, 45] [3, 120] [8, 200]Cada par é: (contagem, valor). São 6 bytes no total (3 pares × 2 bytes por par).
Olhando assim, fizemos uma redução de 17 bytes para 6 bytes, o que equivale a 65% de redução!
E a compressão é lossless: dá pra reconstruir a sequência original perfeitamente a partir dos dados comprimidos.
Se quiséssemos reconstruir, poderíamos ler cada par e "expandir" da seguinte forma:
[6, 45] → escreve 45 seis vezes: 45 45 45 45 45 45
[3, 120] → escreve 120 três vezes: 120 120 120
[8, 200] → escreve 200 oito vezes: 200 200 200 200 200 200 200 200
E no final juntar tudo em um só: 45 45 45 45 45 45 120 120 120 200 200 200 200 200 200 200 200
Resultado: temos a sequência original, exatamente como era. Sem perda nenhuma.
Quando o RLE brilha (e quando ele falha miseravelmente)?
Agora, antes de você sair achando que o RLE é o melhor algoritmo do mundo, preciso te contar um segredo: ele tem um calcanhar de Aquiles enorme.
O RLE só funciona bem quando existem muitas repetições consecutivas.
Quando os dados têm "runs" longos (muitos valores iguais em sequência), o RLE comprime demais. Mas quando os dados são variados, sem repetição... COSTUMA DAR RUIM 🥴
Vamos ver um exemplo do pior caso:
Dados originais: 10 20 30 40 50 60 70 808 bytes, todos diferentes. Nenhuma repetição. Se aplicarmos a estratégia de RLE nele, teríamos o seguinte:
Dados "comprimidos": [1, 10] [1, 20] [1, 30] [1, 40] [1, 50] [1, 60] [1, 70] [1, 80]Opa.... temos agora 16 bytes! O arquivo "comprimido" ficou o dobro do original! 😱
Isso acontece porque cada valor individual vira um par (1, valor), gastando 2 bytes onde antes gastava 1. O RLE está literalmente adicionando informação em vez de remover.
É como aquela piada: "Doutor, dói quando eu faço isso." — "Então não faça isso."
Se não tem repetição, o RLE não ajuda, pelo contrário, ele só atrapalha.
Pra ficar bem claro, vamos comparar os cenários diferentes.
Melhor caso (muita repetição):
Original: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 (20 bytes)
RLE: [20, 0] (2 bytes)
Compressão: 90%! 🎉Caso médio (alguma repetição):
Original: 5 5 5 3 3 7 7 7 7 2 (10 bytes)
RLE: [3, 5] [2, 3] [4, 7] [1, 2] (8 bytes)
Compressão: 20% 👍Pior caso (zero repetição):
Original: 1 2 3 4 5 6 7 8 9 10 (10 bytes)
RLE: [1,1] [1,2] [1,3] [1,4] [1,5] [1,6]... (20 bytes)
Compressão: -100% (DOBROU!) 💀🎯 Regra de ouro do RLE: Ele é ótimo pra dados com muita redundância espacial (valores consecutivos iguais). É péssimo pra dados variados e "ruidosos".
Onde o RLE é usado na vida real?
Neste caso, apesar da sua simplicidade (e limitação), o RLE é usado de verdade em vários contextos:
1. Máquinas de Fax
Você sabia que a máquina de fax usa RLE?
Quando você manda um fax, a máquina escaneia a página linha por linha, transformando cada pixel em preto ou branco (1 bit por pixel).
Como a maioria das linhas de um documento tem muitos pixels brancos seguidos (as margens, os espaços entre palavras, as linhas em branco), o RLE comprime isso brutalmente.
Uma linha de 1728 pixels onde os primeiros 200 são brancos, depois 50 pretos (uma palavra), depois 300 brancos, depois 80 pretos (outra palavra)... vira o seguinte:
[200, branco] [50, preto] [300, branco] [80, preto]...Em vez de transmitir 1728 bits, transmite muito menos.
É por isso que faxes de documentos de texto são rápidos, mas faxes de fotos (que não têm grandes áreas uniformes) demoram uma eternidade.
2. Formato BMP (Bitmap)
O formato de imagem BMP, aquele que o Windows usa desde os anos 90, tem uma opção de compressão RLE embutida (BMP-RLE4 e BMP-RLE8).
Quando a imagem tem grandes áreas de cor uniforme (como ícones, logos simples, ou diagramas), o RLE comprime razoavelmente bem.
Mas pra fotos? Terrível. É por isso que arquivos BMP de fotos são enormes.
3. Dentro de outros CODECs (como o JPEG!)
E aqui vai uma informação que vai conectar este artigo com o futuro da nossa jornada: o RLE é usado dentro do JPEG!
Calma, não diretamente nos pixels. Depois que o JPEG aplica a DCT e a quantização (que veremos na Fase 3), a maioria dos coeficientes resultantes são zeros.
Muitos zeros consecutivos. O JPEG usa uma variação do RLE pra codificar essas sequências de zeros antes de passar pro Huffman.
Ou seja, o RLE que estamos aprendendo aqui não é só um exercício didático.
Ele vai ser efetivamente usado no nosso CODEC quando chegarmos na etapa de serialização dos coeficientes DCT (artigo 11) 😍
4. Telas de loading e splash screens de jogos antigos
Nos jogos de SNES e Mega Drive, as telas de título e loading eram frequentemente imagens com grandes áreas de cor uniforme (fundo preto, logo colorido).
Essas imagens eram comprimidas com RLE pra caber nos cartuchos de memória limitada. O decompressor era tão simples que rodava em poucos ciclos de CPU, o que para aquela época era o ideal para o hardware fraco.
Implementando o RLE em C
Agora vamos ao que interessa: implementar o RLE do zero em C.
Para isso, nós vamos criar um encoder (que comprime) e um decoder (que descomprime), e em seguida testar com dados reais.
Para isso, crie uma nova pasta chamada de rle-c, e lá dentro, crie por enquanto, 3 arquivos em branco:
encoder.cdecoder.cmain.c
O Encoder (Compressor):
O encoder que vamos construir agora, percorre os dados de entrada, identifica sequências de bytes iguais consecutivos (runs), e escreve pares (contagem, valor) na saída.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// ============================================================
// RLE ENCODER — Comprime dados usando Run-Length Encoding
// ============================================================
//
// Recebe:
// - input[] → array de bytes originais
// - input_size → quantidade de bytes na entrada
// - output[] → array onde os dados comprimidos serão escritos
// (deve ter espaço suficiente: no pior caso, 2× input_size)
//
// Retorna:
// - O tamanho dos dados comprimidos (em bytes)
//
// Formato de saída:
// Cada "run" é codificado como 2 bytes: [contagem] [valor]
// A contagem máxima por run é 255 (porque cabe em 1 byte).
// Se um valor se repete mais de 255 vezes, quebramos em múltiplos runs.
int rle_encode(unsigned char *input, int input_size, unsigned char *output) {
int out_pos = 0; // posição atual no array de saída
int i = 0; // posição atual no array de entrada
while (i < input_size) {
// Pega o valor atual
unsigned char valor = input[i];
// Conta quantas vezes esse valor se repete consecutivamente
int contagem = 1;
// Avança enquanto o próximo byte for igual ao atual
// E enquanto a contagem não estourar 255 (máximo que cabe em 1 byte)
while (i + contagem < input_size
&& input[i + contagem] == valor
&& contagem < 255) {
contagem++;
}
// Escreve o par (contagem, valor) na saída
output[out_pos] = (unsigned char) contagem;
output[out_pos + 1] = valor;
out_pos += 2;
// Avança a posição de leitura pelo tamanho da run que acabamos de processar
i += contagem;
}
return out_pos; // retorna o tamanho total dos dados comprimidos
}O Decoder (Descompressor):
O decoder faz o caminho inverso: lê pares (contagem, valor) e expande de volta pra sequência original.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// ============================================================
// PROTÓTIPOS DAS FUNÇÕES
// ============================================================
//
// Como o encoder está no arquivo encoder.c e o decoder está no
// arquivo decoder.c, o main.c precisa saber que essas funções existem.
//
// Essas duas linhas abaixo são chamadas de "protótipos de função".
// Elas dizem ao compilador:
// - existe uma função chamada rle_encode
// - existe uma função chamada rle_decode
//
// A implementação real dessas funções está em outros arquivos.
int rle_encode(unsigned char *input, int input_size, unsigned char *output);
int rle_decode(unsigned char *input, int input_size, unsigned char *output);
// ============================================================
// MAIN — Testa o encoder e o decoder com diferentes cenários
// ============================================================
int main() {
printf("=== RLE (Run-Length Encoding) ===\n\n");
// ----- Teste 1: Melhor caso (muita repetição) -----
printf("--- Teste 1: Melhor caso (muita repetição) ---\n");
unsigned char teste1[] = {
45, 45, 45, 45, 45, 45, // 6× valor 45
120, 120, 120, // 3× valor 120
200, 200, 200, 200, 200, 200, 200, 200 // 8× valor 200
};
int tamanho1 = sizeof(teste1);
// Buffer pro resultado comprimido (no pior caso: 2× o tamanho original)
unsigned char comprimido1[100];
int tam_comprimido1 = rle_encode(teste1, tamanho1, comprimido1);
printf("Original: %d bytes → ", tamanho1);
for (int i = 0; i < tamanho1; i++) printf("%d ", teste1[i]);
printf("\n");
printf("Comprimido: %d bytes → ", tam_comprimido1);
for (int i = 0; i < tam_comprimido1; i += 2)
printf("[%d×%d] ", comprimido1[i], comprimido1[i + 1]);
printf("\n");
printf("Compressão: %.1f%%\n",
(1.0 - (double)tam_comprimido1 / tamanho1) * 100.0);
// Descomprime pra verificar se volta ao original
unsigned char descomprimido1[100];
int tam_descomprimido1 = rle_decode(comprimido1, tam_comprimido1, descomprimido1);
// Verifica se é idêntico ao original (lossless!)
int ok1 = (tam_descomprimido1 == tamanho1)
&& (memcmp(teste1, descomprimido1, tamanho1) == 0);
printf("Lossless: %s\n\n", ok1 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
// ----- Teste 2: Pior caso (nenhuma repetição) -----
printf("--- Teste 2: Pior caso (nenhuma repetição) ---\n");
unsigned char teste2[] = {10, 20, 30, 40, 50, 60, 70, 80};
int tamanho2 = sizeof(teste2);
unsigned char comprimido2[100];
int tam_comprimido2 = rle_encode(teste2, tamanho2, comprimido2);
printf("Original: %d bytes → ", tamanho2);
for (int i = 0; i < tamanho2; i++) printf("%d ", teste2[i]);
printf("\n");
printf("Comprimido: %d bytes → ", tam_comprimido2);
for (int i = 0; i < tam_comprimido2; i += 2)
printf("[%d×%d] ", comprimido2[i], comprimido2[i + 1]);
printf("\n");
printf("Compressão: %.1f%% %s\n",
(1.0 - (double)tam_comprimido2 / tamanho2) * 100.0,
tam_comprimido2 > tamanho2 ? "(EXPANDIU!)" : "");
unsigned char descomprimido2[100];
int tam_descomprimido2 = rle_decode(comprimido2, tam_comprimido2, descomprimido2);
int ok2 = (tam_descomprimido2 == tamanho2)
&& (memcmp(teste2, descomprimido2, tamanho2) == 0);
printf("Lossless: %s\n\n", ok2 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
// ----- Teste 3: Caso realista (uma "linha de pixels" com áreas uniformes) -----
printf("--- Teste 3: Caso realista (linha de pixels) ---\n");
// Simula uma linha de 30 pixels onde:
// - os primeiros 10 são "céu" (valor 180)
// - os próximos 5 são "montanha" (valor 80)
// - os últimos 15 são "grama" (valor 100)
unsigned char teste3[30];
for (int i = 0; i < 10; i++) teste3[i] = 180; // céu
for (int i = 10; i < 15; i++) teste3[i] = 80; // montanha
for (int i = 15; i < 30; i++) teste3[i] = 100; // grama
int tamanho3 = 30;
unsigned char comprimido3[100];
int tam_comprimido3 = rle_encode(teste3, tamanho3, comprimido3);
printf("Original: %d bytes (10 céu + 5 montanha + 15 grama)\n", tamanho3);
printf("Comprimido: %d bytes → ", tam_comprimido3);
for (int i = 0; i < tam_comprimido3; i += 2)
printf("[%d×%d] ", comprimido3[i], comprimido3[i + 1]);
printf("\n");
printf("Compressão: %.1f%%\n",
(1.0 - (double)tam_comprimido3 / tamanho3) * 100.0);
unsigned char descomprimido3[100];
int tam_descomprimido3 = rle_decode(comprimido3, tam_comprimido3, descomprimido3);
int ok3 = (tam_descomprimido3 == tamanho3)
&& (memcmp(teste3, descomprimido3, tamanho3) == 0);
printf("Lossless: %s\n\n", ok3 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
// ----- Teste 4: Caso extremo (255+ repetições) -----
printf("--- Teste 4: Caso extremo (300 repetições) ---\n");
unsigned char teste4[300];
memset(teste4, 77, 300); // 300 bytes com valor 77
int tamanho4 = 300;
unsigned char comprimido4[100];
int tam_comprimido4 = rle_encode(teste4, tamanho4, comprimido4);
printf("Original: %d bytes (tudo valor 77)\n", tamanho4);
printf("Comprimido: %d bytes → ", tam_comprimido4);
for (int i = 0; i < tam_comprimido4; i += 2)
printf("[%d×%d] ", comprimido4[i], comprimido4[i + 1]);
printf("\n");
printf("Compressão: %.1f%%\n",
(1.0 - (double)tam_comprimido4 / tamanho4) * 100.0);
unsigned char descomprimido4[600];
int tam_descomprimido4 = rle_decode(comprimido4, tam_comprimido4, descomprimido4);
int ok4 = (tam_descomprimido4 == tamanho4)
&& (memcmp(teste4, descomprimido4, tamanho4) == 0);
printf("Lossless: %s\n", ok4 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
return 0;
}O programa principal (testando tudo):
// ============================================================
// MAIN — Testa o encoder e o decoder com diferentes cenários
// ============================================================
int main() {
printf("=== RLE (Run-Length Encoding) ===\n\n");
// ----- Teste 1: Melhor caso (muita repetição) -----
printf("--- Teste 1: Melhor caso (muita repetição) ---\n");
unsigned char teste1[] = {
45, 45, 45, 45, 45, 45, // 6× valor 45
120, 120, 120, // 3× valor 120
200, 200, 200, 200, 200, 200, 200, 200 // 8× valor 200
};
int tamanho1 = sizeof(teste1);
// Buffer pro resultado comprimido (no pior caso: 2× o tamanho original)
unsigned char comprimido1[100];
int tam_comprimido1 = rle_encode(teste1, tamanho1, comprimido1);
printf("Original: %d bytes → ", tamanho1);
for (int i = 0; i < tamanho1; i++) printf("%d ", teste1[i]);
printf("\n");
printf("Comprimido: %d bytes → ", tam_comprimido1);
for (int i = 0; i < tam_comprimido1; i += 2)
printf("[%d×%d] ", comprimido1[i], comprimido1[i+1]);
printf("\n");
printf("Compressão: %.1f%%\n",
(1.0 - (double)tam_comprimido1 / tamanho1) * 100.0);
// Descomprime pra verificar se volta ao original
unsigned char descomprimido1[100];
int tam_descomprimido1 = rle_decode(comprimido1, tam_comprimido1, descomprimido1);
// Verifica se é idêntico ao original (lossless!)
int ok1 = (tam_descomprimido1 == tamanho1)
&& (memcmp(teste1, descomprimido1, tamanho1) == 0);
printf("Lossless: %s\n\n", ok1 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
// ----- Teste 2: Pior caso (nenhuma repetição) -----
printf("--- Teste 2: Pior caso (nenhuma repetição) ---\n");
unsigned char teste2[] = {10, 20, 30, 40, 50, 60, 70, 80};
int tamanho2 = sizeof(teste2);
unsigned char comprimido2[100];
int tam_comprimido2 = rle_encode(teste2, tamanho2, comprimido2);
printf("Original: %d bytes → ", tamanho2);
for (int i = 0; i < tamanho2; i++) printf("%d ", teste2[i]);
printf("\n");
printf("Comprimido: %d bytes → ", tam_comprimido2);
for (int i = 0; i < tam_comprimido2; i += 2)
printf("[%d×%d] ", comprimido2[i], comprimido2[i+1]);
printf("\n");
printf("Compressão: %.1f%% %s\n",
(1.0 - (double)tam_comprimido2 / tamanho2) * 100.0,
tam_comprimido2 > tamanho2 ? "(EXPANDIU!)" : "");
unsigned char descomprimido2[100];
int tam_descomprimido2 = rle_decode(comprimido2, tam_comprimido2, descomprimido2);
int ok2 = (tam_descomprimido2 == tamanho2)
&& (memcmp(teste2, descomprimido2, tamanho2) == 0);
printf("Lossless: %s\n\n", ok2 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
// ----- Teste 3: Caso realista (uma "linha de pixels" com áreas uniformes) -----
printf("--- Teste 3: Caso realista (linha de pixels) ---\n");
// Simula uma linha de 30 pixels onde:
// - os primeiros 10 são "céu" (valor 180)
// - os próximos 5 são "montanha" (valor 80)
// - os últimos 15 são "grama" (valor 100)
unsigned char teste3[30];
for (int i = 0; i < 10; i++) teste3[i] = 180; // céu
for (int i = 10; i < 15; i++) teste3[i] = 80; // montanha
for (int i = 15; i < 30; i++) teste3[i] = 100; // grama
int tamanho3 = 30;
unsigned char comprimido3[100];
int tam_comprimido3 = rle_encode(teste3, tamanho3, comprimido3);
printf("Original: %d bytes (10 céu + 5 montanha + 15 grama)\n", tamanho3);
printf("Comprimido: %d bytes → ", tam_comprimido3);
for (int i = 0; i < tam_comprimido3; i += 2)
printf("[%d×%d] ", comprimido3[i], comprimido3[i+1]);
printf("\n");
printf("Compressão: %.1f%%\n",
(1.0 - (double)tam_comprimido3 / tamanho3) * 100.0);
unsigned char descomprimido3[100];
int tam_descomprimido3 = rle_decode(comprimido3, tam_comprimido3, descomprimido3);
int ok3 = (tam_descomprimido3 == tamanho3)
&& (memcmp(teste3, descomprimido3, tamanho3) == 0);
printf("Lossless: %s\n\n", ok3 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
// ----- Teste 4: Caso extremo (255+ repetições) -----
printf("--- Teste 4: Caso extremo (300 repetições) ---\n");
unsigned char teste4[300];
memset(teste4, 77, 300); // 300 bytes com valor 77
int tamanho4 = 300;
unsigned char comprimido4[100];
int tam_comprimido4 = rle_encode(teste4, tamanho4, comprimido4);
printf("Original: %d bytes (tudo valor 77)\n", tamanho4);
printf("Comprimido: %d bytes → ", tam_comprimido4);
for (int i = 0; i < tam_comprimido4; i += 2)
printf("[%d×%d] ", comprimido4[i], comprimido4[i+1]);
printf("\n");
printf("Compressão: %.1f%%\n",
(1.0 - (double)tam_comprimido4 / tamanho4) * 100.0);
unsigned char descomprimido4[600];
int tam_descomprimido4 = rle_decode(comprimido4, tam_comprimido4, descomprimido4);
int ok4 = (tam_descomprimido4 == tamanho4)
&& (memcmp(teste4, descomprimido4, tamanho4) == 0);
printf("Lossless: %s\n", ok4 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
return 0;
}Pra compilar e rodar esse app, basta fazer isso no seu terminal:
cd ~/rle-c
gcc main.c encoder.c decoder.c -o rle
./rleA saída esperada será:
=== RLE (Run-Length Encoding) ===
--- Teste 1: Melhor caso (muita repetição) ---
Original: 17 bytes → 45 45 45 45 45 45 120 120 120 200 200 200 200 200 200 200 200
Comprimido: 6 bytes → [6×45] [3×120] [8×200]
Compressão: 64.7%
Lossless: SIM (idêntico ao original)
--- Teste 2: Pior caso (nenhuma repetição) ---
Original: 8 bytes → 10 20 30 40 50 60 70 80
Comprimido: 16 bytes → [1×10] [1×20] [1×30] [1×40] [1×50] [1×60] [1×70] [1×80]
Compressão: -100.0% (EXPANDIU!)
Lossless: SIM (idêntico ao original)
--- Teste 3: Caso realista (linha de pixels) ---
Original: 30 bytes (10 céu + 5 montanha + 15 grama)
Comprimido: 6 bytes → [10×180] [5×80] [15×100]
Compressão: 80.0%
Lossless: SIM (idêntico ao original)
--- Teste 4: Caso extremo (300 repetições) ---
Original: 300 bytes (tudo valor 77)
Comprimido: 4 bytes → [255×77] [45×77]
Compressão: 98.7%
Lossless: SIM (idêntico ao original)Repare no Teste 4: como a contagem máxima por run é 255 (limite de 1 byte), as 300 repetições são divididas em dois runs: [255×77] e [45×77]. O encoder faz isso automaticamente graças ao && contagem < 255 no loop.
Aplicando RLE numa imagem real
Agora vamos fazer algo mais interessante: aplicar o RLE numa imagem RGB24 real e ver como ele se sai.
Vou te adiantar: ele vai se sair mal em fotos, porque fotos têm muita variação pixel a pixel. Mas vai se sair bem em imagens sintéticas com áreas uniformes.,
Mas antes, tem um detalhe importante que preciso te explicar.
Por que separar os canais R, G e B antes de aplicar o RLE?
Lembra que no formato RGB24, os bytes são armazenados entrelaçados: R, G, B, R, G, B, R, G, B...
Se você aplicar o RLE direto nessa sequência entrelaçada, ele vai encontrar pouquíssimas repetições, mesmo numa imagem de cor sólida! Mas Por quê?
Imagine uma linha de 3 pixels vermelhos puros (255, 0, 0):
Entrelaçado: 255 0 0 255 0 0 255 0 0O RLE olha pra isso e vê: 255 aparece 1 vez, depois 0 aparece 2 vezes, depois 255 aparece 1 vez, depois 0 aparece 2 vezes... Os canais se alternam e quebram as runs!
Agora, se você separar os canais primeiro, da seguinte forma:
Canal R: 255 255 255 → RLE: [3, 255]
Canal G: 0 0 0 → RLE: [3, 0]
Canal B: 0 0 0 → RLE: [3, 0]Temos agora, um conjunto de Runs enormes e perfeitas! Cada canal vira uma sequência de valores do mesmo tipo, e as repetições ficam evidentes.
É por isso que na prática, os CODECs reais sempre separam os canais antes de aplicar qualquer compressão. E é exatamente isso que vamos fazer aqui.
Pra esse teste, vamos criar duas imagens de 100×100 pixels:
- Imagem 1: bandeira com 3 faixas horizontais de cor sólida (ótima pro RLE)
- Imagem 2: degradê suave (péssima pro RLE)
Segue abaixo o código do seu main.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// ============================================================
// RLE ENCODER — Comprime dados usando Run-Length Encoding
// ============================================================
//
// Recebe:
// - input[] → array de bytes originais
// - input_size → quantidade de bytes na entrada
// - output[] → array onde os dados comprimidos serão escritos
// (deve ter espaço suficiente: no pior caso, 2× input_size)
//
// Retorna:
// - O tamanho dos dados comprimidos (em bytes)
//
// Formato de saída:
// Cada "run" é codificado como 2 bytes: [contagem] [valor]
// A contagem máxima por run é 255 (porque cabe em 1 byte).
// Se um valor se repete mais de 255 vezes, quebramos em múltiplos runs.
int rle_encode(unsigned char *input, int input_size, unsigned char *output) {
int out_pos = 0; // posição atual no array de saída
int i = 0; // posição atual no array de entrada
while (i < input_size) {
// Pega o valor atual
unsigned char valor = input[i];
// Conta quantas vezes esse valor se repete consecutivamente
int contagem = 1;
// Avança enquanto o próximo byte for igual ao atual
// E enquanto a contagem não estourar 255 (máximo que cabe em 1 byte)
while (i + contagem < input_size
&& input[i + contagem] == valor
&& contagem < 255) {
contagem++;
}
// Escreve o par (contagem, valor) na saída
output[out_pos] = (unsigned char) contagem;
output[out_pos + 1] = valor;
out_pos += 2;
// Avança a posição de leitura pelo tamanho da run que acabamos de processar
i += contagem;
}
return out_pos; // retorna o tamanho total dos dados comprimidos
}
// ============================================================
// RLE DECODER — Descomprime dados codificados com RLE
// ============================================================
//
// Recebe:
// - input[] → array de bytes comprimidos (pares contagem+valor)
// - input_size → tamanho dos dados comprimidos
// - output[] → array onde os dados descomprimidos serão escritos
//
// Retorna:
// - O tamanho dos dados descomprimidos (em bytes)
int rle_decode(unsigned char *input, int input_size, unsigned char *output) {
int out_pos = 0; // posição atual no array de saída
int i = 0; // posição atual no array de entrada
// Percorre os dados comprimidos de 2 em 2 bytes (cada par = 1 run)
while (i < input_size) {
unsigned char contagem = input[i]; // primeiro byte: quantas vezes
unsigned char valor = input[i + 1]; // segundo byte: qual valor
// Escreve o valor "contagem" vezes na saída
for (int j = 0; j < contagem; j++) {
output[out_pos] = valor;
out_pos++;
}
i += 2; // avança pro próximo par
}
return out_pos; // retorna o tamanho total dos dados descomprimidos
}
// ============================================================
// MAIN — Testa o RLE em duas imagens RGB24
// ============================================================
int main() {
int width = 100, height = 100;
int total_pixels = width * height; // 10.000 pixels
int total_bytes = total_pixels * 3; // 30.000 bytes (RGB24)
// ===== IMAGEM 1: Bandeira com faixas sólidas =====
unsigned char *bandeira = (unsigned char *) malloc(total_bytes);
for (int j = 0; j < height; j++) {
for (int i = 0; i < width; i++) {
int idx = (j * width + i) * 3;
if (j < 33) {
// Faixa superior: verde (0, 180, 50)
bandeira[idx] = 0;
bandeira[idx+1] = 180;
bandeira[idx+2] = 50;
} else if (j < 66) {
// Faixa do meio: amarelo (255, 220, 0)
bandeira[idx] = 255;
bandeira[idx+1] = 220;
bandeira[idx+2] = 0;
} else {
// Faixa inferior: azul (0, 50, 200)
bandeira[idx] = 0;
bandeira[idx+1] = 50;
bandeira[idx+2] = 200;
}
}
}
// Separa os canais R, G, B da bandeira
// (pra evitar o problema do entrelaçamento)
unsigned char *r1 = (unsigned char *) malloc(total_pixels);
unsigned char *g1 = (unsigned char *) malloc(total_pixels);
unsigned char *b1 = (unsigned char *) malloc(total_pixels);
for (int i = 0; i < total_pixels; i++) {
r1[i] = bandeira[i * 3]; // canal vermelho
g1[i] = bandeira[i * 3 + 1]; // canal verde
b1[i] = bandeira[i * 3 + 2]; // canal azul
}
// Comprime cada canal separadamente com RLE
unsigned char *comp_r1 = (unsigned char *) malloc(total_pixels * 2);
unsigned char *comp_g1 = (unsigned char *) malloc(total_pixels * 2);
unsigned char *comp_b1 = (unsigned char *) malloc(total_pixels * 2);
int tam_r1 = rle_encode(r1, total_pixels, comp_r1);
int tam_g1 = rle_encode(g1, total_pixels, comp_g1);
int tam_b1 = rle_encode(b1, total_pixels, comp_b1);
int tam_comp1 = tam_r1 + tam_g1 + tam_b1; // soma dos 3 canais comprimidos
// Salva a imagem original pra visualização
FILE *f = fopen("bandeira.rgb", "wb");
fwrite(bandeira, 1, total_bytes, f);
fclose(f);
// ===== IMAGEM 2: Degradê (variação contínua) =====
unsigned char *degrade = (unsigned char *) malloc(total_bytes);
for (int j = 0; j < height; j++) {
for (int i = 0; i < width; i++) {
int idx = (j * width + i) * 3;
degrade[idx] = (unsigned char)((i * 255) / (width - 1)); // R varia
degrade[idx+1] = (unsigned char)((j * 255) / (height - 1)); // G varia
degrade[idx+2] = 128; // B fixo
}
}
// Separa os canais R, G, B do degradê
unsigned char *r2 = (unsigned char *) malloc(total_pixels);
unsigned char *g2 = (unsigned char *) malloc(total_pixels);
unsigned char *b2 = (unsigned char *) malloc(total_pixels);
for (int i = 0; i < total_pixels; i++) {
r2[i] = degrade[i * 3];
g2[i] = degrade[i * 3 + 1];
b2[i] = degrade[i * 3 + 2];
}
// Comprime cada canal separadamente com RLE
unsigned char *comp_r2 = (unsigned char *) malloc(total_pixels * 2);
unsigned char *comp_g2 = (unsigned char *) malloc(total_pixels * 2);
unsigned char *comp_b2 = (unsigned char *) malloc(total_pixels * 2);
int tam_r2 = rle_encode(r2, total_pixels, comp_r2);
int tam_g2 = rle_encode(g2, total_pixels, comp_g2);
int tam_b2 = rle_encode(b2, total_pixels, comp_b2);
int tam_comp2 = tam_r2 + tam_g2 + tam_b2;
// Salva a imagem original pra visualização
f = fopen("degrade.rgb", "wb");
fwrite(degrade, 1, total_bytes, f);
fclose(f);
// ===== RESULTADOS =====
printf("=== RLE em Imagens RGB24 (canais separados) ===\n\n");
printf("--- Imagem 1: Bandeira (faixas sólidas) ---\n");
printf("Original: %d bytes (%.1f KB)\n", total_bytes, total_bytes / 1024.0);
printf("Comprimido: %d bytes (%.2f KB)\n", tam_comp1, tam_comp1 / 1024.0);
printf(" Canal R: %d bytes\n", tam_r1);
printf(" Canal G: %d bytes\n", tam_g1);
printf(" Canal B: %d bytes\n", tam_b1);
printf("Compressão: %.1f%%\n\n",
(1.0 - (double)tam_comp1 / total_bytes) * 100.0);
printf("--- Imagem 2: Degradê (variação contínua) ---\n");
printf("Original: %d bytes (%.1f KB)\n", total_bytes, total_bytes / 1024.0);
printf("Comprimido: %d bytes (%.1f KB)\n", tam_comp2, tam_comp2 / 1024.0);
printf(" Canal R: %d bytes\n", tam_r2);
printf(" Canal G: %d bytes\n", tam_g2);
printf(" Canal B: %d bytes\n", tam_b2);
printf("Compressão: %.1f%%\n\n",
(1.0 - (double)tam_comp2 / total_bytes) * 100.0);
printf("Para visualizar as imagens:\n");
printf(" ffplay -f rawvideo -pixel_format rgb24 -video_size 100x100 bandeira.rgb\n");
printf(" ffplay -f rawvideo -pixel_format rgb24 -video_size 100x100 degrade.rgb\n");
// Verificação lossless: descomprime e compara com o original
unsigned char *dec_r1 = (unsigned char *) malloc(total_pixels);
unsigned char *dec_g1 = (unsigned char *) malloc(total_pixels);
unsigned char *dec_b1 = (unsigned char *) malloc(total_pixels);
rle_decode(comp_r1, tam_r1, dec_r1);
rle_decode(comp_g1, tam_g1, dec_g1);
rle_decode(comp_b1, tam_b1, dec_b1);
int ok = (memcmp(r1, dec_r1, total_pixels) == 0)
&& (memcmp(g1, dec_g1, total_pixels) == 0)
&& (memcmp(b1, dec_b1, total_pixels) == 0);
printf("\nVerificação lossless (bandeira): %s\n",
ok ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
// Limpeza
free(bandeira); free(degrade);
free(r1); free(g1); free(b1);
free(r2); free(g2); free(b2);
free(comp_r1); free(comp_g1); free(comp_b1);
free(comp_r2); free(comp_g2); free(comp_b2);
free(dec_r1); free(dec_g1); free(dec_b1);
return 0;
}Pra compilar e rodar:
mkdir -p ~/rle-imagens-c
cd ~/rle-imagens-c
# Crie o arquivo main.c com o código acima
gcc main.c -o rle_imagens
./rle_imagensA saída esperada será algo assim:
=== RLE em Imagens RGB24 (canais separados) ===
--- Imagem 1: Bandeira (faixas sólidas) ---
Original: 30000 bytes (29.3 KB)
Comprimido: 240 bytes (0.23 KB)
Canal R: 80 bytes
Canal G: 80 bytes
Canal B: 80 bytes
Compressão: 99.2%
--- Imagem 2: Degradê (variação contínua) ---
Original: 30000 bytes (29.3 KB)
Comprimido: 20280 bytes (19.8 KB)
Canal R: 10100 bytes
Canal G: 10100 bytes
Canal B: 80 bytes
Compressão: 32.4%
Verificação lossless (bandeira): SIM (idêntico ao original)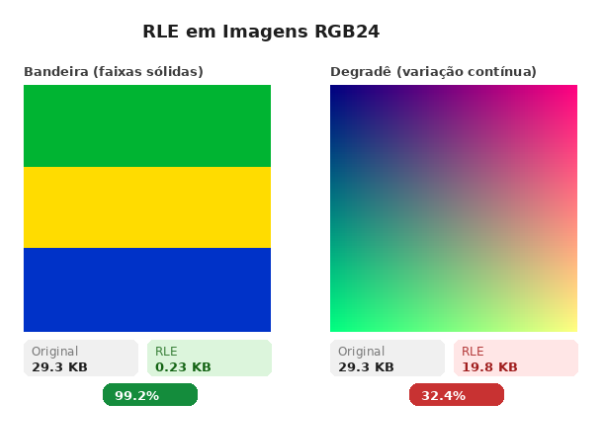
Percebe a diferença brutal?
A bandeira (3 faixas de cor sólida) comprimiu de ~30.000 bytes pra apenas ~240 bytes!
Ou seja, incríveis 99.2% de compressão!
Isso porque cada faixa inteira é um único run gigante de bytes repetidos. Repare também que os 3 canais (R, G, B) comprimiram de forma igual (80 bytes cada), porque a imagem é simétrica em termos de repetição.
O degradê (cada pixel é ligeiramente diferente do vizinho) conseguiu apenas 32.4% de compressão. Os canais R e G quase não comprimiram (10.100 bytes cada pra 10.000 originais), porque os valores variam a cada pixel. Só o canal B se salvou (80 bytes), já que ele é fixo em 128 pra toda a imagem.
E tem um detalhe interessante no degradê: repare que o canal B comprimiu exatamente igual ao da bandeira (80 bytes).
Faz sentido! Em ambas as imagens, o canal B tem runs longas de valores iguais, em uma por ter faixas sólidas, e na outra porque fixamos B = 128 pra todos os pixels.
Observação importante: No caso de imagens reais (fotos), a diferença é ainda mais difícil de perceber, porque fotos naturais têm transições de cor suaves. Onde você vai notar diferença é em bordas nítidas entre cores saturadas diferentes, como texto vermelho sobre fundo branco, por exemplo.
Por que o RLE sozinho não serve pro nosso CODEC?
Agora que você viu o RLE em ação, talvez esteja pensando: "Se o RLE é tão ruim pra fotos, por que estamos aprendendo ele?"
A resposta tem duas partes distintas!
Parte 1 — Voce precisa entender esse princípio
O RLE é o algoritmo de compressão mais simples que existe. Ele te ensina os conceitos fundamentais que todo algoritmo de compressão usa:
- Identificar padrões (runs de valores iguais)
- Substituir por uma representação menor (par contagem+valor)
- Garantir que o processo é reversível (lossless)
Esses conceitos aparecem em todos os outros algoritmos, só que de formas mais sofisticadas.
Parte 2 — Ele é usado dentro do JPEG
Como mencionei antes, o JPEG usa uma variação do RLE pra codificar sequências de zeros nos coeficientes DCT quantizados. Depois da quantização, a maioria dos coeficientes de alta frequência vira zero.
Quando o JPEG faz o Zig-Zag Scan (artigo 11), ele encontra longas sequências de zeros consecutivos que são perfeitamente comprimíveis com RLE.
Isso significa que o RLE não será o compressor principal do nosso CODEC, mas sim, uma peça super importante dentro de um pipeline bem maior.
É como aprender a cortar ingredientes antes de aprender a cozinhar. Cortar não é o prato final, mas sem saber cortar, você não faz nada 😅
Variações do RLE que existem por aí
Antes de encerrar, quero te apresentar algumas variações do RLE que foram criadas pra resolver o problema do "pior caso" (quando não tem repetição).
Variação 1 — RLE com flag de escape
Em vez de sempre usar pares (contagem, valor), você usa um byte especial (flag) pra indicar que uma run vem a seguir. Bytes que não são precedidos pelo flag são armazenados "crus" (sem overhead).
Por exemplo, podemos usar o 0xFF como flag da seguinte forma:
Dados: 10 20 30 40 40 40 40 40 50 60
RLE flag: 10 20 30 0xFF 5 40 50 60Os valores 10, 20, 30, 50 e 60 (que não se repetem) são armazenados direto, sem overhead. Só quando aparece uma repetição (40×5), o flag 0xFF indica que um par (contagem, valor) vem a seguir.
Isso resolve o problema do pior caso: dados sem repetição ocupam praticamente o mesmo espaço que o original (talvez 1-2 bytes a mais pro flag ocasional, em vez de dobrar o tamanho).
A desvantagem é que se o valor 0xFF aparecer naturalmente nos dados, precisa de um tratamento especial (escapar o escape, tipo 0xFF 0xFF pra representar um 0xFF literal).
Variação 2 — PackBits (usado no TIFF e no formato Macintosh)
O PackBits usa um byte de controle que pode ser positivo ou negativo:
- Controle positivo (1 a 127): os próximos N+1 bytes são dados literais (sem repetição)
- Controle negativo (-1 a -127): o próximo byte se repete |N|+1 vezes
Vejamos um pequeno exemplo:
Dados: 10 20 30 40 40 40 40 40
PackBits: [2] 10 20 30 [-4] 40O [2] diz "os próximos 3 bytes são literais". O [-4] diz "o próximo byte se repete 5 vezes".
Isso combina o melhor dos dois mundos: dados variados são armazenados sem overhead, e runs são comprimidos normalmente.
Variação 3 — RLE nos coeficientes DCT (usado no JPEG)
No JPEG, o RLE é aplicado especificamente na sequência de coeficientes AC depois do Zig-Zag Scan. O formato é: (número_de_zeros_antes, tamanho_do_próximo_coeficiente).
Isso codifica eficientemente as longas cadeias de zeros que aparecem depois da quantização.
Vamos ver isso em detalhes no artigo 11 (Zig-Zag Scan), mas fica o spoiler de que o RLE que aprendemos aqui é a base 😛
Conectando com a entropia
Pra fechar com chave de ouro, vamos conectar o RLE com o conceito de entropia que aprendemos no artigo anterior.
Lembra que a entropia mede o "conteúdo de informação" dos dados? E que dados com entropia baixa comprimem bem?
Pois então, o RLE é um algoritmo que explora especificamente um tipo de padrão: repetições consecutivas. Ele é eficiente quando esse padrão domina os dados (entropia baixa pra esse tipo de padrão), e ineficiente quando esse padrão não existe.
O Huffman (próximo artigo) explora outro tipo de padrão: frequências desiguais de símbolos. Ele é eficiente quando certos valores aparecem muito mais que outros.
O LZ77 (artigo 7) explora ainda outro tipo: sequências que se repetem em posições diferentes (não necessariamente consecutivas).
Cada algoritmo de compressão é como uma ferramenta especializada em identificar e explorar um tipo específico de redundância.
E os CODECs reais combinam várias dessas ferramentas em sequência pra espremer o máximo de cada tipo de redundância que existe nos dados.
No nosso futuro CODEC, o pipeline de implementação de compressão vai ser algo como isso:
- Chroma Subsampling → remove redundância visual (lossy)
- DCT → reorganiza dados pra concentrar energia
- Quantização → zera valores irrelevantes, cria muitos zeros (lossy)
- RLE → comprime as sequências de zeros consecutivos (lossless)
- Huffman → comprime a distribuição desigual resultante (lossless)
Cada ferramenta faz o que sabe fazer de melhor, e o resultado final é muito mais poderoso do que qualquer uma delas sozinha.
Resumo: sua primeira ferramenta de compressão
Vamos recapitular tudo o que aprendemos neste artigo:
- RLE (Run-Length Encoding) substitui sequências de valores iguais consecutivos por pares (contagem, valor).
- É uma compressão lossless: os dados originais podem ser reconstruídos perfeitamente.
- Funciona muito bem quando os dados têm muitas repetições consecutivas (imagens com áreas uniformes, documentos de fax, sequências de zeros).
- Funciona muito mal (e pode até expandir os dados) quando não há repetições consecutivas (fotos reais, dados variados).
- O RLE é usado em formatos reais como BMP, PCX, fax, e como parte interna do JPEG (pra codificar zeros nos coeficientes DCT).
- Existem variações (flag de escape, PackBits, RLE em coeficientes DCT) que minimizam o problema do pior caso.
- No nosso CODEC, o RLE será uma peça do pipeline maior, trabalhando depois da quantização pra comprimir sequências de zeros.
No próximo artigo, vamos aprender a segunda técnica de compressão: Codificação de Huffman, uma técnica muito mais poderosa que o RLE, que explora a redundância estatística (frequências desiguais dos valores) pra criar códigos de tamanho variável.
Se o RLE foi o "cortar ingredientes", o Huffman é o "cozinhar de verdade". Prepare-se, porque vai ser denso, mas muito recompensador 🚀

