


Codificação de Huffman: comprimindo com árvores binárias
Olá leitor, seja muito bem vindo de volta a mais uma etapa da nossa jornada aqui no Portal da Micilini 😊
Este é o sexto artigo da nossa série de ~20, e o terceiro da Fase 2 — Fundamentos de Compressão.
No artigo anterior, aprendemos o RLE (Run-Length Encoding), a técnica de compressão mais simples que existe. Vimos que ele funciona muito bem quando os dados têm repetições consecutivas, mas falha miseravelmente quando não tem.
Agora vamos subir um pouco de nível.
A técnica que vamos aprender hoje é uma das mais importantes de toda a ciência da computação: a Codificação de Huffman. Ela foi inventada em 1952 por David Huffman, quando ele era apenas um estudante de mestrado no MIT (Massachusetts Institute of Technology), com apenas 27 anos de idade.
E aqui vai uma história que você precisa saber sobre ele:
O professor de Huffman, Robert Fano, deu aos alunos uma tarefa: encontrar a forma mais eficiente de codificar símbolos com códigos binários de tamanho variável. Fano trabalhava nesse problema havia anos junto com Claude Shannon (sim, o mesmo Shannon da entropia que vimos no artigo 4), e os dois tinham uma solução que era boa, mas ótima.
Huffman, em vez de escrever um trabalho teórico sobre a solução de Shannon-Fano, decidiu resolver o problema de verdade. E conseguiu.
Ele descobriu um algoritmo que sempre produz a codificação ótima, superando a solução do próprio professor.
O resultado foi publicado num paper de apenas 4 páginas, e até hoje, mais de 70 anos depois, o algoritmo de Huffman é usado em praticamente todo formato de compressão que existe, seja ele JPEG, PNG, ZIP, GZIP, MP3, DEFLATE...
E sim, como você já deve estar pensando, a codificação de huffman, vai ser uma peça fundamental do nosso futuro CODEC 😉
Então pega seu café ☕ (hoje talvez dois cafés ☕☕), sente-se confortavelmente, e vamos mergulhar fundo na Codificação de Huffman!
O problema: por que todos os símbolos precisam ter o mesmo tamanho?
Antes de entender a solução do Huffman, vamos entender o problema que ele resolve.
No mundo dos computadores, tudo é representado em binário (0s e 1s). Quando o computador armazena texto, por exemplo, ele usa a tabela ASCII, onde cada caractere recebe um código de 8 bits (1 byte):
A = 01000001 (8 bits)
B = 01000010 (8 bits)
C = 01000011 (8 bits)
Z = 01011010 (8 bits)Percebe que todos os caracteres usam exatamente 8 bits? O "A" (que aparece o tempo todo em textos) usa 8 bits. O "Z" (que quase nunca aparece) também usa 8 bits.
Isso é como se o correio cobrasse o mesmo valor pra enviar uma carta pro vizinho do lado e pra enviar uma carta pro Japão. Não faz sentido! Destinos mais comuns (mais frequentes) deveriam ser mais baratos.
A mesma lógica vale pra codificação de dados: símbolos que aparecem com mais frequência deveriam usar menos bits, e símbolos raros podem usar mais bits. Na média, isso reduziria o total de bits necessários.
Esse é exatamente o insight que o Huffman teve.
Lembra do artigo 4 (entropia), quando calculamos que uma fonte com 4 símbolos de probabilidades desiguais (50%, 25%, 12.5%, 12.5%) tinha entropia de 1.75 bits por símbolo, mas um código fixo usaria 2 bits por símbolo?
Então... o Huffman descobriu como construir códigos que chegam o mais perto possível dessa entropia teórica.
A ideia central: códigos de tamanho variável
A ideia é simples na superfície: dar códigos curtos pra símbolos frequentes e códigos longos pra símbolos raros.
Para entendermos melhor, vamos voltar ao exemplo do artigo 4. Onde lá temos um exemplo de 4 símbolos (A, B, C, D) com estas frequências:
A → aparece 50% das vezes
B → aparece 25% das vezes
C → aparece 12.5% das vezes
D → aparece 12.5% das vezesCom código fixo (2 bits pra todos), nós temos:
A = 00 (2 bits)
B = 01 (2 bits)
C = 10 (2 bits)
D = 11 (2 bits)Temos uma média: 2.0 bits por símbolo em todas as vezes!
Com código de Huffman (tamanho variável), poderíamos representar isso da seguinte forma:
A = 0 (1 bit) ← aparece mais, código mais curto
B = 10 (2 bits)
C = 110 (3 bits) ← aparece menos, código mais longo
D = 111 (3 bits) ← aparece menos, código mais longoCom isso, teremos a seguinte média: 0.50×1 + 0.25×2 + 0.125×3 + 0.125×3 = 0.5 + 0.5 + 0.375 + 0.375 = 1.75 bits por símbolo.
De 2.0 pra 1.75. Uma economia de 12.5%. E esse é exatamente o valor da entropia que calculamos! O Huffman atingiu o limite teórico! 😯
Mas espere aí... antes do código de Huffman, tinhamos 8 bits no total (2 bits, + 2 bits + 2 bits + 2 bits), e agora, temos 9 bits (1 bit + 2 bits + 3 bits + 3 bits). Ou seja, o número de bits ficou maior, será que isso não influencia em alguma coisa? Tipo deixar o arquivo mais pesado?
Inicialmente pode parecer que sim, mas na na verdade não ficou com 1 bit a mais, e vou te explicar por quê 😉
Quando a gente fala que os códigos são 010110111
Pensa assim: no código fixo de 2 bits, todos os 4 símbolos custam 2 bits. Se você codificar 1000 símbolos, gasta 2000 bits sempre, independente de qual símbolo aparece mais.
No Huffman, o A (que aparece 50% das vezes) custa só 1 bit. Então em 1000 símbolos o seguinte:
500 vezes A × 1 bit = 500 bits
250 vezes B × 2 bits = 500 bits
125 vezes C × 3 bits = 375 bits
125 vezes D × 3 bits = 375 bits
Total: 1750 bitsCom código fixo (sem Huffman) teríamos 2000 bits, agora com o código de Huffman, temos 1750 bits. Uma economia de 250 bits.
O "truque" é que o código mais longo (3 bits pro C e D) é usado raramente, então ele quase não pesa no total. E o código mais curto (1 bit pro A) é usado metade do tempo, então ele puxa a média pra baixo com muita força.
Pensa assim... É como se você tivesse dois planos de internet: um cobra R$100 fixo por mês, outro cobra R$5 por GB usado. Se você usa pouco, o plano variável sai mais barato, mesmo que o preço por GB do plano variável seja tecnicamente mais caro pra quem usa muito.
A soma bruta dos tamanhos (9 vs 8) é irrelevante. O que define a eficiência é: quanto cada código pesa na prática, dado com que frequência ele é usado. E essa média ponderada (1.75 bits) é menor que o fixo (2.0 bits).
Entretanto antes de continuarmos, tem um problema sério com códigos de tamanho variável que precisa ser resolvido...
O problema da ambiguidade: como saber onde um código termina?
Imagine que você recebe a seguinte sequência de bits:
01001110Se os códigos fossem de tamanho fixo (2 bits cada), a decodificação discorreria de forma muito mais fácil, como por exemplo:
01 | 00 | 11 | 10 → B A D CSem ambiguidade. Cada bloco de 2 bits é um símbolo.
Mas com códigos de tamanho variável, como saber onde cada código começa e termina? A sequência 01001110
0 | 10 | 0 | 111 | 0 → A B A D A (5 símbolos)
0 | 10 | 0 | 11 | 10 → Ops, "11" não é código válido...
0 | 100 | 1110 → "100" não existe...Se os códigos forem escolhidos de qualquer jeito, a decodificação fica ambígua. Você simplesmente não sabe onde um código termina e o próximo começa.
No caso do Huffman, ele resolveu isso com uma propriedade chamada de código de prefixo (prefix code).
🧠 Regra de prefixo: Nenhum código pode ser o início (prefixo) de outro código.
Dito isso, vamos verificar mais uma vez nossos códigos de Huffman:
A = 0
B = 10
C = 110
D = 111
- O código de A é
00111 - O código de B é
10101111 - O código de C é
110110 - O código de D é
111111
A regra de prefixo é respeitada! E isso garante que a decodificação é sempre única: você lê bit por bit, e no instante que reconhece um código válido, sabe que é aquele símbolo e passa pro próximo.
Sabendo disso, vamos decodificar 01001110
Lê "0" → É código de A! → A
Lê "1" → Não é nenhum código ainda, continua...
Lê "10" → É código de B! → B
Lê "0" → É código de A! → A
Lê "1" → Continua...
Lê "11" → Continua...
Lê "110" → É código de C! → C
Resultado: A B A CZero ambiguidade! A regra de prefixo garante que a cada momento existe no máximo uma interpretação possível.
Mas dai você pode estar se perguntando... como o Huffman garante que os códigos sempre respeitam essa regra?
Simples, ele constrói os códigos usando uma árvore binária.
A Árvore de Huffman: a mágica por trás dos códigos
Agora vem a parte central do algoritmo. Em vez de inventar os códigos "a dedo", o Huffman definiu um processo sistemático que sempre produz os códigos ótimos. Esse processo constrói uma árvore binária de baixo pra cima.
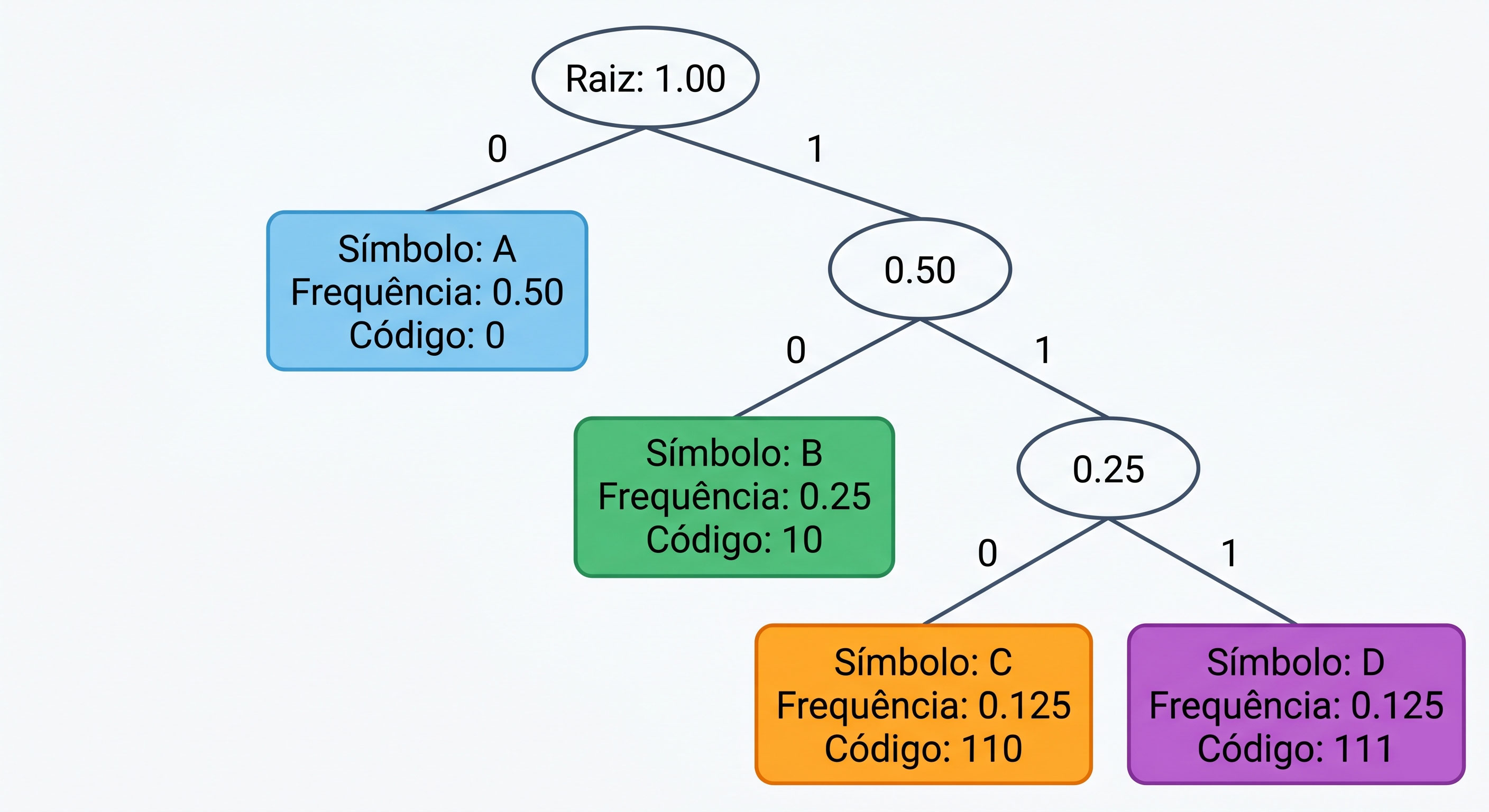
Vamos construir a árvore passo a passo, usando nosso exemplo com 4 símbolos:
A: frequência 50% (0.50)
B: frequência 25% (0.25)
C: frequência 12.5% (0.125)
D: frequência 12.5% (0.125)Com isso em mente, é só seguir o passo a passo abaixo 🤭
Passo 1 — Comece com cada símbolo como uma "folha" individual:
[A: 0.50] [B: 0.25] [C: 0.125] [D: 0.125]Cada símbolo é um nó solto, como árvores de 1 folha. Como podemos ver acima, cada representação retangular daquela ([A: 0.50]) é um elemento único, como se fosse uma espécie de dicionário de palavras e simbolos.
Passo 2 — Pegue os dois nós com as MENORES frequências e junte-os:
Olhando o exemplo acima, qual são os nós menores?
Os menores são C (0.125) e D (0.125). Em seguida, criamos um nó pai contendo a frequência de ambos, por exemplo: 0.125 + 0.125 = 0.25:
[A: 0.50] [B: 0.25] [CD: 0.25]
/ \
[C: 0.125] [D: 0.125]A partir de agora nós temos 3 nós: A (0.50), B (0.25) e CD (0.25).
Passo 3 — Repita: pegue os dois menores e junte:
Os menores são B (0.25) e CD (0.25). Criamos um nó pai com frequência = 0.25 + 0.25 = 0.50:
[A: 0.50] [BCD: 0.50]
/ \
[B: 0.25] [CD: 0.25]
/ \
[C: 0.125] [D: 0.125]Agora temos 2 nós: A (0.50) e BCD (0.50).
Passo 4 — Repita uma última vez:
Os dois restantes são A (0.50) e BCD (0.50). E eles precisam ser juntados:
[RAIZ: 1.00]
/ \
[A: 0.50] [BCD: 0.50]
/ \
[B: 0.25] [CD: 0.25]
/ \
[C: 0.125] [D: 0.125]Pronto! A árvore está completa. A raiz tem frequência 1.00 (que é a soma de todas as frequências, fazendo bastante sentido).
Passo 5 — Atribua os bits: esquerda = 0, direita = 1:
Agora, pra cada galho da árvore, atribuímos 0 pro ramo da esquerda e 1 pro ramo da direita, por exemplo:
[RAIZ]
0 / \ 1
[A] [BCD]
0 / \ 1
[B] [CD]
0 / \ 1
[C] [D]Onde o código de cada símbolo é o caminho da raiz até a folha:
A: esquerda → 0
B: direita, esquerda → 10
C: direita, direita, esquerda → 110
D: direita, direita, direita → 111E aí estão os mesmos códigos que vimos antes! A árvore de Huffman garante automaticamente que a regra de prefixo é respeitada (porque cada símbolo é uma folha, e nenhum caminho até uma folha é prefixo de outro).
Construindo a árvore com um exemplo maior
Pra fixar o algoritmo, vamos construir uma árvore de Huffman com um exemplo mais realista: comprimindo a frase "ABRACADABRA".
Primeiro, contamos a frequência de cada letra:
A → 5 vezes (45.5%)
B → 2 vezes (18.2%)
R → 2 vezes (18.2%)
C → 1 vez (9.1%)
D → 1 vez (9.1%)Total: 11 caracteres, 5 símbolos distintos.
Passo 1 — Criando nossas folhas individuais:
[A: 5] [B: 2] [R: 2] [C: 1] [D: 1]Passo 2 — Junte os dois menores (C:1 e D:1):
[A: 5] [B: 2] [R: 2] [CD: 2]
/ \
[C: 1] [D: 1]Passo 3 — Junte os dois menores (B:2 e R:2):
[A: 5] [BR: 4] [CD: 2]
/ \
[B: 2] [R: 2]Agora temos: A (5), BR (4), CD (2).
Passo 4 — Junte os dois menores (CD:2 e BR:4):
[A: 5] [BRCD: 6]
/ \
[BR: 4] [CD: 2]
/ \ / \
[B: 2] [R: 2] [C: 1] [D: 1]Agora temos: A (5) e BRCD (6).
Passo 5 — Junte os dois últimos:
[RAIZ: 11]
/ \
[A: 5] [BRCD: 6]
/ \
[BR: 4] [CD: 2]
/ \ / \
[B: 2] [R: 2] [C: 1] [D: 1]Atribuindo os bits (esquerda = 0, direita = 1):, teremos:
A: 0 (1 bit)
B: 100 (3 bits)
R: 101 (3 bits)
C: 110 (3 bits)
D: 111 (3 bits)Agora vamos codificar "ABRACADABRA":
A B R A C A D A B R A
0 100 101 0 110 0 111 0 100 101 0
Juntando: 0 100 101 0 110 0 111 0 100 101 0
Total: 23 bitsAgora vamos fazer a mesma codificação, só que usando código fixo. Com 5 símbolos, precisaríamos de 3 bits cada (porque 2 bits = 4 combinações, não bastam pra 5 símbolos), sendo assim:
11 caracteres × 3 bits = 33 bitsSe fizermos uma comparação direta com o Huffman, temos 23 bits, o que representa uma economia de 30.3%!
E com ASCII (8 bits por caractere): 11 × 8 = 88 bits. O Huffman reduziu pra 23 bits. Economia de 73.9%!
Mas peraí, o Huffman é aplicado em palavras, letras, ou o quê?
Essa é uma dúvida que surge naturalmente depois de ver o exemplo do "ABRACADABRA".
A gente usou letras, construiu a árvore com letras, codificou letras... então é natural pensar: "quando eu for comprimir um texto como 'Olá Mundo', o Huffman é aplicado palavra por palavra? Letra por letra? Cada frase separada?"
A resposta é: nenhuma dessas opções, pelo menos não no contexto do nosso CODEC.
O Huffman não trabalha com "palavras" nem com "letras".
Ele trabalha com bytes crus (valores de 0 a 255). O exemplo do "ABRACADABRA" foi puramente didático, porque é muito mais fácil visualizar uma árvore com as letras A, B, R, C, D do que com números como 0, 12, -3, 187.
No nosso CODEC de imagem, o que o Huffman vai receber não são letras nem palavras. São números.
Quando a imagem passar pelo pipeline completo (YCbCr → Chroma Subsampling → DCT → Quantização → Zig-Zag Scan), o resultado será uma sequência gigante de números, algo assim mais ou menos assim:
12, 0, 0, 0, -3, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0...O Huffman vai olhar pra essa sequência inteira (não pedaço por pedaço, não bloco por bloco) e contar a frequência de cada valor: "o zero apareceu 80% das vezes, o 1 apareceu 5%, o -3 apareceu 2%..." e assim por diante.
A partir dessas frequências, ele constrói uma única árvore e codifica a sequência inteira de uma vez.
O zero (que aparece 80% das vezes) ganha um código curtíssimo (tipo 112 ou o -3 ganham códigos mais longos (tipo 0011010
E se fosse um compressor de texto, como é o caso do ZIP?
A lógica seria exatamente a mesma. A frase "Eu gostaria de saber de um animal que começa com a letra A" seria tratada como uma sequência de bytes:
'E', 'u', ' ', 'g', 'o', 's', 't', 'a', 'r', 'i', 'a', ' ', 'd', 'e', ' ', 's', 'a', 'b', 'e', 'r'...O Huffman contaria a frequência de cada byte na mensagem inteira: o espaço ' ''a''e''z'
E geraria os códigos com base nessas frequências globais. O espaço e as letras 'a''e''U'
Tudo em uma sequência contínua, nunca palavra por palavra.
E dai, você pode estar se perguntando... Por que não separar por palavras ou por blocos?
Porque fragmentar os dados perderia a vantagem estatística. O Huffman funciona melhor quanto mais dados ele tem pra analisar, porque a distribuição de frequências fica mais estável e representativa.
Imagina que você quer descobrir qual é a letra mais comum do português. Se você analisar só a palavra "zzz", vai concluir que é o Z. Mas se analisar um livro inteiro, vai descobrir que é o A. Quanto maior a amostra, mais confiável é a estatística, e melhores são os códigos que o Huffman gera.
Se fragmentássemos a mensagem em palavras e aplicássemos Huffman em cada uma separadamente, cada "mini-árvore" teria poucos símbolos, poucos dados pra trabalhar, e o overhead de armazenar múltiplas árvores (uma pra cada palavra) anularia qualquer ganho de compressão.
🧠 Resumindo: O Huffman sempre recebe uma sequência contínua de bytes e constrói uma única árvore baseada nas frequências globais. No caso de texto, os bytes são caracteres ASCII.
No caso do nosso CODEC, os bytes são coeficientes DCT quantizados. A lógica é a mesma, só muda o que os números representam.
Implementando o Huffman em C
Agora vamos ao código. A implementação do Huffman tem 3 partes principais:
- Contar frequências dos símbolos
- Construir a árvore de Huffman
- Gerar os códigos a partir da árvore
- Codificar os dados usando os códigos
- Decodificar os dados usando a árvore
Dito isso vamos construir tudo passo a passo 😊
Primeiro de tudo, você vai precisar criar uma nova pasta chamada de huffman-c, e dentro dela, um arquivo chamado main.c, com a seguinte lógica:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// ============================================================
// ESTRUTURAS DE DADOS
// ============================================================
// Cada nó da árvore de Huffman pode ser uma FOLHA (com um símbolo)
// ou um NÓ INTERNO (com dois filhos).
typedef struct NoHuffman {
unsigned char simbolo; // O byte que este nó representa (só pra folhas)
int frequencia; // Quantas vezes esse símbolo aparece
struct NoHuffman *esquerda; // Filho esquerdo (bit 0)
struct NoHuffman *direita; // Filho direito (bit 1)
} NoHuffman;
// Estrutura pra armazenar o código binário de cada símbolo
// (como string de '0's e '1's pra facilitar a visualização)
typedef struct {
char bits[256]; // O código em si (ex: "110")
int tamanho; // Quantos bits tem o código
} CodigoHuffman;
// ============================================================
// FUNÇÕES AUXILIARES
// ============================================================
// Cria um novo nó folha (com símbolo)
NoHuffman *criar_folha(unsigned char simbolo, int frequencia) {
NoHuffman *no = (NoHuffman *) malloc(sizeof(NoHuffman));
no->simbolo = simbolo;
no->frequencia = frequencia;
no->esquerda = NULL;
no->direita = NULL;
return no;
}
// Cria um novo nó interno (com dois filhos)
NoHuffman *criar_no_interno(NoHuffman *esq, NoHuffman *dir) {
NoHuffman *no = (NoHuffman *) malloc(sizeof(NoHuffman));
no->simbolo = 0; // Nós internos não têm símbolo
no->frequencia = esq->frequencia + dir->frequencia;
no->esquerda = esq;
no->direita = dir;
return no;
}
// Verifica se um nó é folha (não tem filhos)
int eh_folha(NoHuffman *no) {
return (no->esquerda == NULL && no->direita == NULL);
}
// Libera toda a memória da árvore recursivamente
void liberar_arvore(NoHuffman *no) {
if (no == NULL) return;
liberar_arvore(no->esquerda);
liberar_arvore(no->direita);
free(no);
}
// ============================================================
// PASSO 1: CONTAR FREQUÊNCIAS
// ============================================================
//
// Percorre todos os bytes de entrada e conta quantas vezes
// cada valor (0 a 255) aparece.
void contar_frequencias(unsigned char *dados, int tamanho, int *freq) {
// Inicializa todas as frequências com zero
for (int i = 0; i < 256; i++) {
freq[i] = 0;
}
// Conta cada byte
for (int i = 0; i < tamanho; i++) {
freq[dados[i]]++;
}
}
// ============================================================
// PASSO 2: CONSTRUIR A ÁRVORE DE HUFFMAN
// ============================================================
//
// Usa o algoritmo clássico:
// 1. Cria uma folha pra cada símbolo com freq > 0
// 2. Repetidamente pega os 2 nós com menor frequência
// e junta num nó pai
// 3. Para quando sobra 1 nó (a raiz)
//
// NOTA: pra simplificar, estou usando um array como
// "fila de prioridade" ingênua. Em produção, usaria
// uma min-heap, mas pra fins didáticos o array é mais
// fácil de entender.
NoHuffman *construir_arvore(int *freq) {
// Array de ponteiros pros nós (nossa "fila de prioridade" simples)
NoHuffman *nos[256];
int num_nos = 0;
// Cria uma folha pra cada símbolo que aparece pelo menos 1 vez
for (int i = 0; i < 256; i++) {
if (freq[i] > 0) {
nos[num_nos] = criar_folha((unsigned char) i, freq[i]);
num_nos++;
}
}
// Caso especial: se só tem 1 símbolo, cria um nó pai artificial
// (uma árvore precisa de pelo menos 2 folhas pra gerar códigos)
if (num_nos == 1) {
NoHuffman *filho = nos[0];
NoHuffman *raiz = criar_no_interno(filho, criar_folha(0, 0));
return raiz;
}
// Repetidamente junta os 2 nós de menor frequência
while (num_nos > 1) {
// Encontra o nó com MENOR frequência
int idx_min1 = 0;
for (int i = 1; i < num_nos; i++) {
if (nos[i]->frequencia < nos[idx_min1]->frequencia) {
idx_min1 = i;
}
}
// Remove o menor do array (troca com o último e diminui o tamanho)
NoHuffman *min1 = nos[idx_min1];
nos[idx_min1] = nos[num_nos - 1];
num_nos--;
// Encontra o SEGUNDO menor
int idx_min2 = 0;
for (int i = 1; i < num_nos; i++) {
if (nos[i]->frequencia < nos[idx_min2]->frequencia) {
idx_min2 = i;
}
}
// Remove o segundo menor
NoHuffman *min2 = nos[idx_min2];
nos[idx_min2] = nos[num_nos - 1];
num_nos--;
// Cria um nó pai que junta os dois
NoHuffman *pai = criar_no_interno(min1, min2);
// Adiciona o pai de volta no array
nos[num_nos] = pai;
num_nos++;
}
// Sobrou 1 nó: é a raiz da árvore
return nos[0];
}
// ============================================================
// PASSO 3: GERAR OS CÓDIGOS A PARTIR DA ÁRVORE
// ============================================================
//
// Percorre a árvore recursivamente. Cada vez que desce
// pra esquerda, adiciona '0' ao código. Cada vez que
// desce pra direita, adiciona '1'. Quando chega numa
// folha, o caminho percorrido é o código daquele símbolo.
void gerar_codigos(NoHuffman *no, char *caminho, int profundidade,
CodigoHuffman *tabela) {
if (no == NULL) return;
// Se é folha, salva o código na tabela
if (eh_folha(no)) {
caminho[profundidade] = '\0'; // termina a string
strcpy(tabela[no->simbolo].bits, caminho);
tabela[no->simbolo].tamanho = profundidade;
return;
}
// Desce pra esquerda (bit 0)
caminho[profundidade] = '0';
gerar_codigos(no->esquerda, caminho, profundidade + 1, tabela);
// Desce pra direita (bit 1)
caminho[profundidade] = '1';
gerar_codigos(no->direita, caminho, profundidade + 1, tabela);
}
// ============================================================
// PASSO 4: CODIFICAR (comprimir)
// ============================================================
//
// Substitui cada byte de entrada pelo seu código de Huffman.
// O resultado é uma sequência de bits empacotados em bytes.
int huffman_encode(unsigned char *entrada, int tamanho_entrada,
unsigned char *saida, CodigoHuffman *tabela) {
int bit_pos = 0; // posição atual em bits no array de saída
// Inicializa a saída com zeros
// (o tamanho máximo possível é difícil de prever, mas
// nunca será maior que o dobro da entrada)
memset(saida, 0, tamanho_entrada * 2);
for (int i = 0; i < tamanho_entrada; i++) {
unsigned char simbolo = entrada[i];
CodigoHuffman *codigo = &tabela[simbolo];
// Escreve cada bit do código na saída
for (int j = 0; j < codigo->tamanho; j++) {
if (codigo->bits[j] == '1') {
// Liga o bit na posição correta
// byte_idx = em qual byte estamos
// bit_idx = qual bit dentro desse byte (7=mais significativo)
int byte_idx = bit_pos / 8;
int bit_idx = 7 - (bit_pos % 8);
saida[byte_idx] |= (1 << bit_idx);
}
bit_pos++;
}
}
// Retorna o tamanho em bytes (arredondando pra cima)
return (bit_pos + 7) / 8;
}
// ============================================================
// PASSO 5: DECODIFICAR (descomprimir)
// ============================================================
//
// Percorre a sequência de bits e navega pela árvore:
// - bit 0 → vai pra esquerda
// - bit 1 → vai pra direita
// - chegou numa folha → emite o símbolo e volta pra raiz
int huffman_decode(unsigned char *entrada, int total_bits,
NoHuffman *raiz, unsigned char *saida) {
int out_pos = 0;
NoHuffman *atual = raiz;
for (int bit_pos = 0; bit_pos < total_bits; bit_pos++) {
// Lê o bit na posição bit_pos
int byte_idx = bit_pos / 8;
int bit_idx = 7 - (bit_pos % 8);
int bit = (entrada[byte_idx] >> bit_idx) & 1;
// Navega pela árvore
if (bit == 0) {
atual = atual->esquerda;
} else {
atual = atual->direita;
}
// Se chegou numa folha, emite o símbolo
if (eh_folha(atual)) {
saida[out_pos] = atual->simbolo;
out_pos++;
atual = raiz; // volta pra raiz pra decodificar o próximo
}
}
return out_pos;
}
// ============================================================
// MAIN — Testa tudo com exemplos concretos
// ============================================================
int main() {
printf("=== Codificação de Huffman ===\n\n");
// ----- Teste 1: ABRACADABRA -----
printf("--- Teste 1: ABRACADABRA ---\n\n");
char *texto1 = "ABRACADABRA";
int tamanho1 = strlen(texto1);
// Passo 1: Contar frequências
int freq1[256];
contar_frequencias((unsigned char *)texto1, tamanho1, freq1);
printf("Frequências:\n");
for (int i = 0; i < 256; i++) {
if (freq1[i] > 0) {
printf(" '%c' → %d vezes (%.1f%%)\n",
(char)i, freq1[i], (freq1[i] * 100.0) / tamanho1);
}
}
printf("\n");
// Passo 2: Construir a árvore
NoHuffman *raiz1 = construir_arvore(freq1);
// Passo 3: Gerar os códigos
CodigoHuffman tabela1[256];
memset(tabela1, 0, sizeof(tabela1));
char caminho1[256];
gerar_codigos(raiz1, caminho1, 0, tabela1);
printf("Códigos de Huffman:\n");
for (int i = 0; i < 256; i++) {
if (tabela1[i].tamanho > 0) {
printf(" '%c' → %s (%d bits)\n",
(char)i, tabela1[i].bits, tabela1[i].tamanho);
}
}
printf("\n");
// Passo 4: Codificar
unsigned char saida1[100];
int tam_codificado1 = huffman_encode(
(unsigned char *)texto1, tamanho1, saida1, tabela1);
// Calcula total de bits usado
int total_bits1 = 0;
for (int i = 0; i < tamanho1; i++) {
total_bits1 += tabela1[(unsigned char)texto1[i]].tamanho;
}
printf("Original: \"%s\" (%d caracteres × 8 bits = %d bits)\n",
texto1, tamanho1, tamanho1 * 8);
printf("Huffman: %d bits (%d bytes)\n", total_bits1, tam_codificado1);
printf("Compressão: %.1f%% (vs ASCII 8-bit)\n\n",
(1.0 - (double)total_bits1 / (tamanho1 * 8)) * 100.0);
// Passo 5: Decodificar e verificar
unsigned char decodificado1[100];
int tam_decodificado1 = huffman_decode(saida1, total_bits1, raiz1, decodificado1);
decodificado1[tam_decodificado1] = '\0';
int ok1 = (tam_decodificado1 == tamanho1)
&& (memcmp(texto1, decodificado1, tamanho1) == 0);
printf("Decodificado: \"%s\"\n", decodificado1);
printf("Lossless: %s\n\n",
ok1 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
liberar_arvore(raiz1);
// ----- Teste 2: Texto com distribuição mais desigual -----
printf("--- Teste 2: Texto com muita repetição ---\n\n");
char *texto2 = "AAAAAAAAAAAAAAAAABBBBCCD";
int tamanho2 = strlen(texto2);
int freq2[256];
contar_frequencias((unsigned char *)texto2, tamanho2, freq2);
printf("Frequências:\n");
for (int i = 0; i < 256; i++) {
if (freq2[i] > 0) {
printf(" '%c' → %d vezes (%.1f%%)\n",
(char)i, freq2[i], (freq2[i] * 100.0) / tamanho2);
}
}
printf("\n");
NoHuffman *raiz2 = construir_arvore(freq2);
CodigoHuffman tabela2[256];
memset(tabela2, 0, sizeof(tabela2));
char caminho2[256];
gerar_codigos(raiz2, caminho2, 0, tabela2);
printf("Códigos de Huffman:\n");
for (int i = 0; i < 256; i++) {
if (tabela2[i].tamanho > 0) {
printf(" '%c' → %s (%d bits)\n",
(char)i, tabela2[i].bits, tabela2[i].tamanho);
}
}
printf("\n");
unsigned char saida2[100];
int tam_codificado2 = huffman_encode(
(unsigned char *)texto2, tamanho2, saida2, tabela2);
int total_bits2 = 0;
for (int i = 0; i < tamanho2; i++) {
total_bits2 += tabela2[(unsigned char)texto2[i]].tamanho;
}
printf("Original: \"%s\" (%d chars × 8 bits = %d bits)\n",
texto2, tamanho2, tamanho2 * 8);
printf("Huffman: %d bits (%d bytes)\n", total_bits2, tam_codificado2);
printf("Compressão: %.1f%% (vs ASCII 8-bit)\n\n",
(1.0 - (double)total_bits2 / (tamanho2 * 8)) * 100.0);
unsigned char decodificado2[100];
int tam_decodificado2 = huffman_decode(saida2, total_bits2, raiz2, decodificado2);
decodificado2[tam_decodificado2] = '\0';
int ok2 = (tam_decodificado2 == tamanho2)
&& (memcmp(texto2, decodificado2, tamanho2) == 0);
printf("Decodificado: \"%s\"\n", decodificado2);
printf("Lossless: %s\n\n",
ok2 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
liberar_arvore(raiz2);
// ----- Teste 3: Simulando dados de imagem (canal Y pós-quantização) -----
printf("--- Teste 3: Simulando coeficientes DCT quantizados ---\n\n");
// Depois da DCT + quantização, a maioria dos valores são 0,
// com alguns valores pequenos e raros valores grandes.
// Vamos simular isso:
unsigned char dados3[100];
// 60 zeros (simula coeficientes zerados pela quantização)
memset(dados3, 0, 60);
// 20 valores pequenos (1, 2, 3)
for (int i = 60; i < 70; i++) dados3[i] = 1;
for (int i = 70; i < 78; i++) dados3[i] = 2;
for (int i = 78; i < 80; i++) dados3[i] = 3;
// 15 valores médios
for (int i = 80; i < 90; i++) dados3[i] = 10;
for (int i = 90; i < 95; i++) dados3[i] = 20;
// 5 valores grandes (raros)
dados3[95] = 100; dados3[96] = 150;
dados3[97] = 200; dados3[98] = 220; dados3[99] = 255;
int tamanho3 = 100;
int freq3[256];
contar_frequencias(dados3, tamanho3, freq3);
NoHuffman *raiz3 = construir_arvore(freq3);
CodigoHuffman tabela3[256];
memset(tabela3, 0, sizeof(tabela3));
char caminho3[256];
gerar_codigos(raiz3, caminho3, 0, tabela3);
printf("Frequências dos valores mais comuns:\n");
printf(" 0 → %d vezes (60%%)\n", freq3[0]);
printf(" 1 → %d vezes (10%%)\n", freq3[1]);
printf(" 2 → %d vezes (8%%)\n", freq3[2]);
printf(" ... valores raros: 3%% a 1%% cada\n\n");
printf("Códigos de Huffman (seleção):\n");
printf(" 0 → %s (%d bits) ← mais comum, código mais curto!\n",
tabela3[0].bits, tabela3[0].tamanho);
printf(" 1 → %s (%d bits)\n", tabela3[1].bits, tabela3[1].tamanho);
printf(" 2 → %s (%d bits)\n", tabela3[2].bits, tabela3[2].tamanho);
printf(" 255 → %s (%d bits) ← mais raro, código mais longo\n\n",
tabela3[255].bits, tabela3[255].tamanho);
unsigned char saida3[200];
int tam_codificado3 = huffman_encode(dados3, tamanho3, saida3, tabela3);
int total_bits3 = 0;
for (int i = 0; i < tamanho3; i++) {
total_bits3 += tabela3[dados3[i]].tamanho;
}
printf("Original: %d bytes (= %d bits com tamanho fixo de 8 bits)\n",
tamanho3, tamanho3 * 8);
printf("Huffman: %d bits (%d bytes)\n", total_bits3, tam_codificado3);
printf("Compressão: %.1f%%\n\n",
(1.0 - (double)total_bits3 / (tamanho3 * 8)) * 100.0);
// Verificação lossless
unsigned char decodificado3[200];
int tam_decodificado3 = huffman_decode(saida3, total_bits3, raiz3, decodificado3);
int ok3 = (tam_decodificado3 == tamanho3)
&& (memcmp(dados3, decodificado3, tamanho3) == 0);
printf("Lossless: %s\n\n",
ok3 ? "SIM (idêntico ao original)" : "NÃO (ERRO!)");
liberar_arvore(raiz3);
// ----- Resumo -----
printf("=== Resumo ===\n");
printf("Teste 1 (ABRACADABRA): %d bits → %d bits (%.1f%% economia)\n",
tamanho1*8, total_bits1, (1.0-(double)total_bits1/(tamanho1*8))*100.0);
printf("Teste 2 (muita repetição): %d bits → %d bits (%.1f%% economia)\n",
tamanho2*8, total_bits2, (1.0-(double)total_bits2/(tamanho2*8))*100.0);
printf("Teste 3 (coeficientes DCT): %d bits → %d bits (%.1f%% economia)\n",
tamanho3*8, total_bits3, (1.0-(double)total_bits3/(tamanho3*8))*100.0);
return 0;
}Para compilar esse projeto na sua máquina, basta rodar:
cd ~/huffman-c
gcc main.c -o huffman
./huffmanO programa roda os 3 testes e mostra todo o processo: frequências, códigos gerados, tamanho original vs comprimido, e verificação lossless.
O Teste 3 é o mais relevante pra nossa jornada, porque simula exatamente o tipo de dados que o Huffman vai receber no pipeline do JPEG: coeficientes DCT quantizados, onde a maioria é zero.
O Huffman dá um código curtíssimo pro zero (que aparece 60% das vezes) e códigos longos pros valores raros. O resultado é uma compressão pesada.
Huffman vs RLE: quando usar cada um?
Agora que você conhece as duas técnicas, vamos fazer algumas comparações diretas.
No caso do RLE ele explora repetições consecutivas. É eficiente quando o mesmo valor se repete muitas vezes seguidas (runs longos), mas falha quando os valores variam a cada posição.
Já o Huffman explora frequências desiguais. Ele é eficiente quando certos valores aparecem muito mais que outros, independentemente de estarem consecutivos ou não. Funciona mesmo que os dados não tenham nenhuma repetição consecutiva.
Imagine a sequência: 0 1 0 2 0 0 3 0 1 0 0 0 2 0 0 0 0 1
O RLE não comprime quase nada aqui, porque os runs de zero são curtos (máximo de 4) e intercalados com outros valores.
Mas o Huffman olha e vê: "o zero aparece 11 vezes em 18 (61%), o 1 aparece 3 vezes (17%), o 2 aparece 2 vezes (11%), o 3 aparece 1 vez (6%)".
Ou seja, é uma distribuição super desigual. O Huffman comprime bem, dando 1 bit pro zero e 2-3 bits pros outros.
E quando os dois são usados juntos?
No JPEG (e no nosso), a sequência vai ser:
- Primeiro o RLE comprime as sequências de zeros consecutivos (codificando "7 zeros seguidos, depois um 3, depois 12 zeros seguidos, depois um 1...")
- Depois o Huffman comprime o resultado do RLE, porque os pares (contagem, valor) do RLE têm distribuição desigual.
Cada técnica faz o que sabe fazer de melhor, e juntas elas comprimem mais do que qualquer uma sozinha.
Uma nota sobre Huffman vs Codificação Aritmética
Antes de encerrar, preciso mencionar que o Huffman tem uma limitação: ele só consegue atribuir um número inteiro de bits a cada símbolo.
Se a entropia diz que um símbolo deveria usar 1.3 bits, o Huffman tem que escolher entre 1 ou 2 bits. Isso significa que ele nem sempre atinge exatamente o limite da entropia.
Existe uma técnica mais avançada chamada Codificação Aritmética que resolve esse problema.
Ela consegue atribuir efetivamente frações de bits a cada símbolo, chegando mais perto do limite teórico. É usada no JPEG 2000, no H.265/HEVC, no AV1, e em CODECs modernos em geral.
Uma variação mais recente chamada ANS (Asymmetric Numeral Systems) combina a eficiência da codificação aritmética com a velocidade do Huffman. É usada no Zstandard (zstd), no formato de compressão do Facebook.
Pro nosso CODEC, vamos usar Huffman, que é mais simples de implementar e já dá resultados excelentes.
Mas fica o conhecimento de que existe algo ainda mais eficiente caso você queira evoluir o codec no futuro (e vamos fazer isso após os ~20 artigos 🤭)
O que o JPEG faz de diferente no Huffman
Um detalhe importante pra quando chegarmos na Fase 4: o JPEG não transmite a árvore de Huffman junto com a imagem. Em vez disso, ele usa tabelas de Huffman padrão definidas na especificação do formato.
Isso significa que o encoder JPEG não precisa construir uma árvore customizada pra cada imagem. Ele usa tabelas pré-calculadas que funcionam "razoavelmente bem" pra maioria das fotos.
A vantagem é que o decoder não precisa receber a árvore (economizando bytes no header). A desvantagem é que a compressão não é tão boa quanto seria com uma árvore customizada pra cada imagem específica.
O JPEG permite usar tabelas customizadas (modo "otimizado"), e muitos encoders JPEG modernos (como o mozjpeg) fazem exatamente isso: constroem uma árvore ótima pra cada imagem e incluem ela no arquivo. O resultado é uma compressão 5-10% melhor.
Pro nosso N.148i, vamos implementar as duas opções: tabelas padrão (pra simplicidade) e tabelas customizadas (pra compressão máxima), mas isso é assunto pro artigo 13 (Fase 4).
Resumo: comprimindo com inteligência
Vamos recapitular tudo o que aprendemos neste artigo:
- Codificação de Huffman cria códigos de tamanho variável: símbolos frequentes recebem códigos curtos, símbolos raros recebem códigos longos.
- Foi inventada por David Huffman em 1952, superando a solução do próprio professor (Shannon-Fano).
- Os códigos respeitam a regra de prefixo: nenhum código é o início de outro, garantindo decodificação sem ambiguidade.
- O algoritmo constrói uma árvore binária de baixo pra cima, juntando os dois nós de menor frequência a cada passo.
- O Huffman atinge compressão próxima do limite teórico (entropia de Shannon), mas limitado a números inteiros de bits por símbolo.
- É uma compressão lossless: os dados originais são perfeitamente reconstruídos a partir da árvore + bits comprimidos.
- No pipeline do JPEG/N.148i, o Huffman é a última etapa: comprime os coeficientes DCT quantizados (que têm distribuição muito desigual, com muitos zeros).
- Huffman + RLE juntos são mais poderosos que cada um sozinho: o RLE trata as repetições consecutivas, e o Huffman trata as frequências desiguais.
No próximo artigo, vamos fechar a Fase 2 com LZ77 e DEFLATE: os algoritmos que estão por trás do PNG e do ZIP. Eles exploram um terceiro tipo de redundância: sequências que se repetem em posições diferentes dos dados (não necessariamente consecutivas).
Com isso, teremos as 3 ferramentas fundamentais de compressão na caixa (RLE, Huffman, LZ77), e estaremos prontos pra entrar na Fase 3, onde vamos aprender a DCT, a quantização e o coração de um CODEC de imagem 🚀

