

O que são ORMs? E quais as vantagens de se utilizar em seus projetos?
Antigamente (e até hoje), nós, meros desenvolvedores, criávamos nosso banco de dados, e após isso, conectávamos a lógica da nossa aplicação diretamente na nossa tabela do banco de dados.
Essa comunicação acontecia de forma direta, ou seja, a aplicação chamava o banco de dados por meio de uma query SQL, que por sua vez, respondia com os dados da resposta.
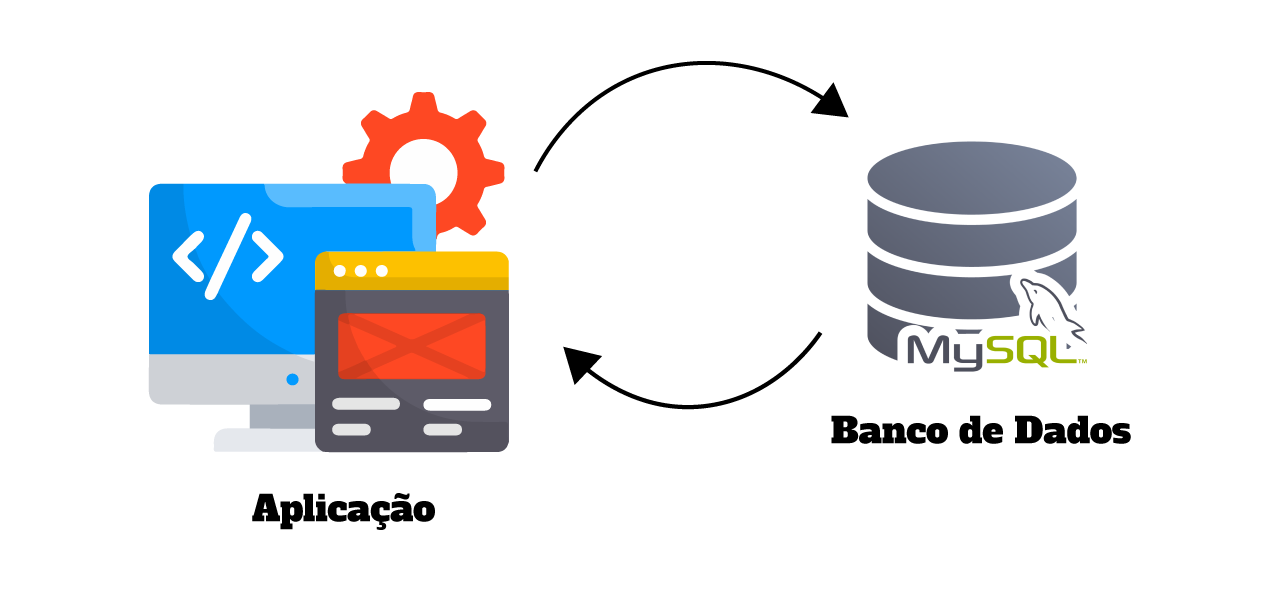
Eu começo dizendo, que não há nenhum problema em fazer isso nos dias atuais, pois ainda existem muitos sistemas que operam dessa forma, então fique tranquilo enquanto a isso 😁
Hoje, eu quero apresentar a você (leitor), uma nova maneira (um pouco mais moderna) de se comunicar com a sua base de dados, e que vem tendo uma grande adoção por parte dos desenvolvedores, o ORM!
Prontos para iniciar a leitura?
O que é um ORM?
Um ORM (Object-Relational Mapping) é uma técnica de programação que permite aos desenvolvedores interagir com bancos de dados relacionais utilizando objetos da linguagem de programação, sem a necessidade de escrever consultas SQL de forma direta.
Basicamente, será por meio de um ORM que você será capaz de traduzir a lógica do banco de dados, em códigos no formato Javascript, só que um pouco mais simples.
Ainda não entendeu? Então vamos lá 😊
Você sabe o que é programação orientada a objetos, não sabe?
Quando estamos trabalhando com OOP (Object Oriented Programming -- Programação Orientada a Objetos), temos um sistema mais modular, organizado e de fácil manutenção.
Onde fazemos o uso de classes, métodos e propriedades, com o intuito de encapsular comportamentos e dados, promover a reutilização de código e facilitar a abstração de conceitos complexos em unidades menores e mais gerenciáveis.
Isso permite que o código seja estruturado de forma que cada classe represente um objeto ou conceito do mundo real, e seus métodos definam as ações que esses objetos podem executar, enquanto as propriedades armazenam seus estados.
Até aí tudo bem, certo? 🙃
Quando estamos usando OOP em conjunto com um banco de dados relacional (MySQL, PostGres e entre outros), nós costumamos separar a comunicação dentro de Models (do MVC) ou quem sabe dentro de services (arquivos utilitários), que serão responsáveis por fazer essa ponte, entra a aplicação e o banco de dados.
Só que, se você for parar para pensar, o paradigma de orientação a objetos (OOP) funciona de uma maneira muito diferente do paradigma relacional usado pelos bancos de dados.
Enquanto na OOP estamos lidando com objetos que possuem identidade, comportamento, e que podem estar relacionados por meio de herança e polimorfismo.
No banco de dados relacional, nós estamos lidando com tabelas, colunas e linhas, que têm uma estrutura bem definida, e relacionamentos baseados em chaves estrangeiras.
Até aí, tudo parece tranquilo, mas essa diferença de paradigmas gera um problema que chamamos de impedância objeto-relacional.
Esse termo se refere à dificuldade de mapear de forma direta e eficiente, as estruturas complexas e hierárquicas da OOP em um modelo relacional, que é um pouco mais plano e estruturado em tabelas.
Ou seja, a impedância objeto-relacional é o desafio de integrar dois mundos que funcionam de maneiras diferentes: o mundo dos objetos, onde temos encapsulamento, identidade por referência, herança e polimorfismo, e o mundo relacional, onde temos chaves primárias, colunas fixas e relacionamentos entre tabelas.
E para resolver essa questão, um grupo de desenvolvedores em uma época desconhecida, parou e pensou no seguinte cenário:
"Enquanto estamos aqui batendo cabeça para integrar esses dois mundos neste projeto, porque não criamos uma forma de representar uma tabela do banco de dados dentro de um objeto, e interagir com ela como se fosse um? Evitando escrever querys SQL de forma direta?".
E foi aí que nasceu o primeiro ORM do mundo, cujo nome é Active Record, criado por Dave Thomas e Andy Hunt como parte do framework Ruby on Rails.
E é obvio, que o conceito de um ORM é totalmente gerenciado por uma biblioteca ou framework, capaz de mapear tudo isso pra gente 😋
Ou melhor dizendo... esconder a lógica de comunicação direta com o banco, e deixar que nós, desenvolvedores, nos preocupemos apenas com a relação dos objetos (que representam colunas de uma tabela).
Principais aspectos da impedância objeto-relacional
Antes de continuarmos, é necessário que você que você entenda o conceito por trás da impedância objeto-relacional, e o porque é tão difícil conectar esses dois mundos 😢
Em OOP, os dados são representados por objetos que possuem atributos e métodos. Os objetos podem ser hierarquicamente relacionados por herança.
No modelo relacional, os dados são organizados em tabelas, que têm linhas (registros) e colunas (campos), e as relações são feitas por chaves estrangeiras, sem suporte direto a hierarquias ou objetos complexos.
Em OOP, as classes podem herdar propriedades e comportamentos de outras classes.
No modelo relacional, não há um conceito nativo de herança, o que pode dificultar o mapeamento de hierarquias de classes em uma estrutura de tabelas.
Em OOP, a identidade de um objeto é baseada na sua instância, o que significa que dois objetos podem ter os mesmos valores, mas ainda assim serem entidades diferentes.
No modelo relacional, a identidade de um registro é baseada nos valores de suas colunas, particularmente em chaves primárias.
Em OOP, o estado de um objeto pode ser modificado diretamente através de seus métodos, com forte ênfase em encapsulamento e controle de acesso aos dados.
No modelo relacional, a manipulação de dados é feita por meio de consultas SQL, que operam diretamente sobre as tabelas, sem o conceito de encapsulamento.
Apesar de ser tranquilo (dependendo da complexidade do projeto) passarmos por cima dessa impedância, os ORMs surgiram para tentar mitigar esse problema central, oferecendo uma camada de abstração que mapeia objetos para tabelas existentes em um banco de dados.
No entanto, essa solução não elimina completamente as diferenças, e pode gerar desafios de desempenho e complexidade dependendo do caso.
Concluindo, podemos dizer que os ORMs são fruto dos processos de arquitetura limpa, uma vez que o CONCEITO PRINCIPAL seguem o mesmo princípio de separação de responsabilidade, onde facilita a criação de sistemas mais organizados e modulares.
Através dos ORMs, podemos manter a lógica de negócio da aplicação separada da camada de persistência de dados, evitando que o código da aplicação precise lidar diretamente com consultas SQL, e manipular dados de forma orientada a objetos.
Basicamente, um ORM funciona dessa forma:
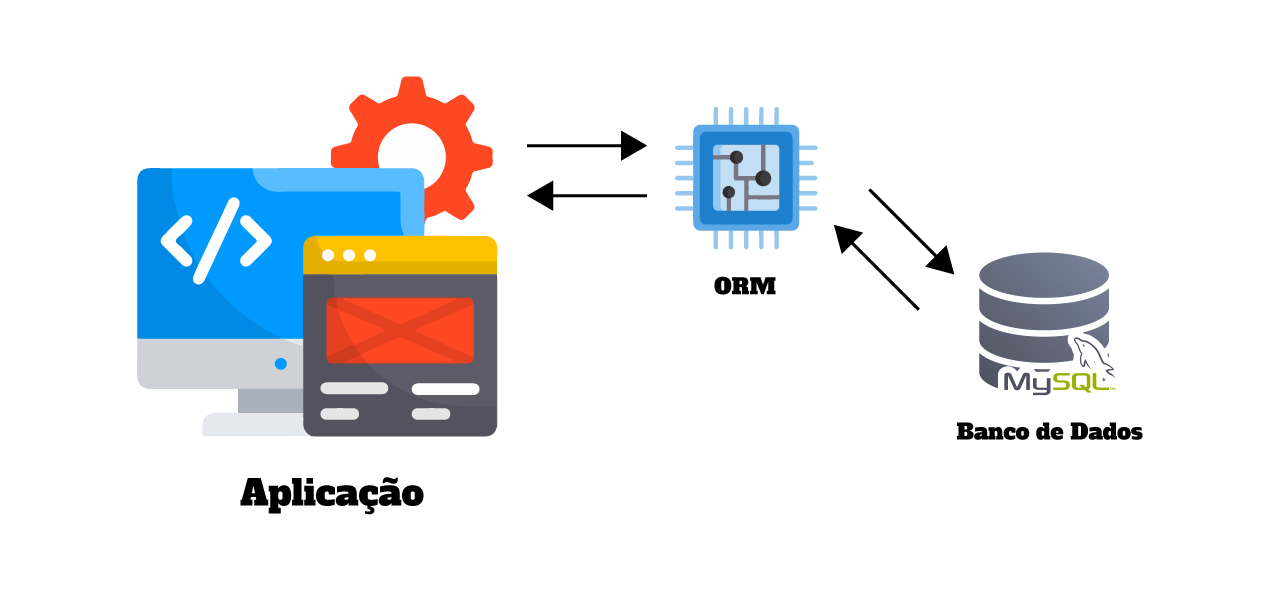
Padrões de ORM
Independentemente da sua linguagem de programação favorita, o conceito de um ORM já estão tão difundido na comunidade de desenvolvimento, que atualmente, para cada linguagem já existe uma biblioteca ou framework de ORM 😅
Apesar disso, atualmente temos dois modelos padrão de um ORM, e que seguem a mesma lógica independente da linguagem de programação que você esteja usando, são eles:
- Data Mapper
- Active Record
Veremos o comportamento de cada um deles nos próximos tópicos 🙂
Data Mapper
O padrão Data Mapper é um padrão arquitetural usado em aplicações que lidam com bancos de dados.
Ele é responsável por separar a lógica de negócios da lógica de acesso a dados, permitindo que os objetos da aplicação (no caso da OOP) permaneçam independentes da estrutura e operações do banco de dados.
Vamos observar um exemplo de como o Data Mapper funciona:
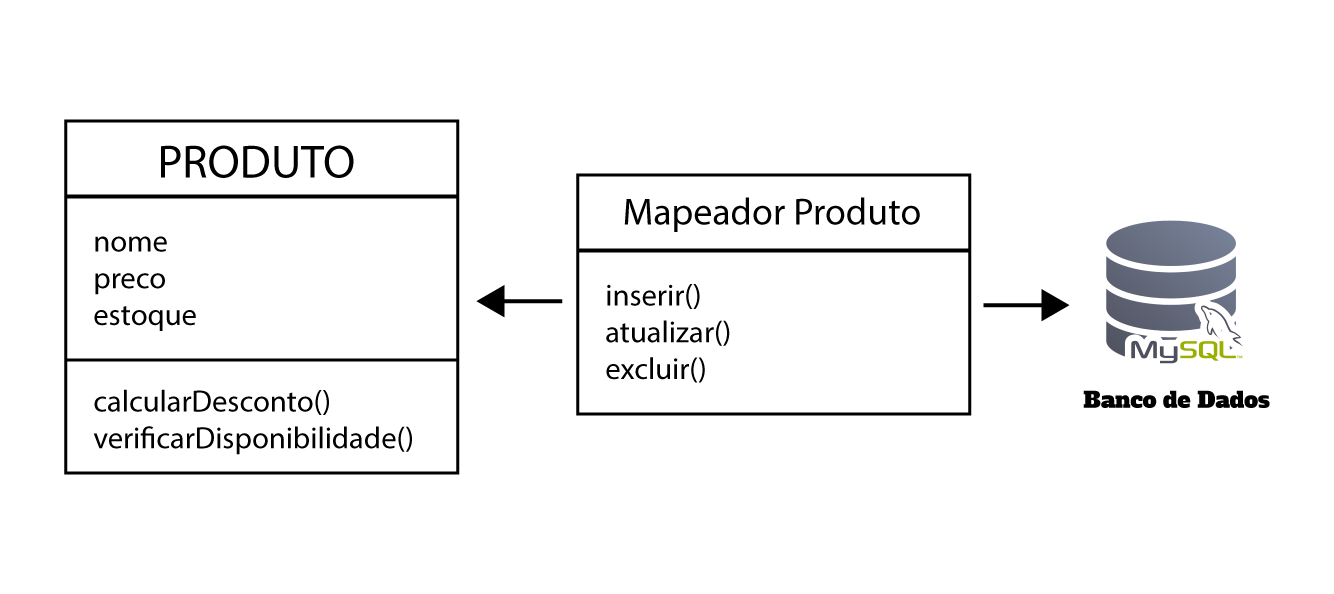
Começando pelo bloco onde está escrito "PRODUTO", entenda que ele representa uma classe dentro da sua aplicação. Onde essa classe conta com os atributos:
nomeprecoestoque
Junto com dois métodos principais:
calcularDesconto()verificarDisponibilidade()
Se eu fosse representar isso na linguagem Javascript, teríamos uma classe representada dessa maneira:
class Produto {
constructor(nome, preco, estoque) {
this.nome = nome;
this.preco = preco;
this.estoque = estoque;
}
// Método para calcular desconto
calcularDesconto(percentual) {
//Lógica aqui...
}
// Método para verificar se o produto está disponível
verificarDisponibilidade() {
//Lógica aqui...
}
}Em seguida, no segundo bloco onde está escrito "Mapeador Produto", ele nada mais é do que uma outra classe, que é responsável por encapsular a lógica de persistência de dados (inserção, atualização, exclusão, leitura) para a entidade Produto.
Se eu fosse representar isso no Javascript, teríamos algo como:
class MapeadorProduto {
constructor(databaseConnection) {
this.db = databaseConnection; // Uma conexão com o banco de dados, por exemplo
}
// Método para inserir um produto no banco de dados
async inserir(produto) {
const query = `INSERT INTO produtos (nome, preco, estoque) VALUES (?, ?, ?)`;
const values = [produto.nome, produto.preco, produto.estoque];
try {
const [result] = await this.db.execute(query, values);
console.log("Produto inserido com sucesso:", result.insertId);
return result;
} catch (error) {
console.error("Erro ao inserir o produto:", error);
throw error;
}
}
// Método para atualizar um produto existente
async atualizar(produto, id) {
const query = `UPDATE produtos SET nome = ?, preco = ?, estoque = ? WHERE id = ?`;
const values = [produto.nome, produto.preco, produto.estoque, id];
try {
const [result] = await this.db.execute(query, values);
console.log(`Produto ${id} atualizado com sucesso.`);
return result;
} catch (error) {
console.error(`Erro ao atualizar o produto ${id}:`, error);
throw error;
}
}
// Método para excluir um produto do banco de dados
async excluir(id) {
const query = `DELETE FROM produtos WHERE id = ?`;
try {
const [result] = await this.db.execute(query, [id]);
console.log(`Produto ${id} excluído com sucesso.`);
return result;
} catch (error) {
console.error(`Erro ao excluir o produto ${id}:`, error);
throw error;
}
}
// Método para buscar um produto por ID
async buscarPorId(id) {
const query = `SELECT * FROM produtos WHERE id = ?`;
try {
const [rows] = await this.db.execute(query, [id]);
if (rows.length > 0) {
return rows[0]; // Retorna o produto encontrado
} else {
throw new Error(`Produto com ID ${id} não encontrado.`);
}
} catch (error) {
console.error(`Erro ao buscar o produto ${id}:`, error);
throw error;
}
}
}Basicamente, a classe MapeadorProduto é responsável por realizar as operações CRUD (Create, Read, Update, Delete) para a entidade Produto.
Ela recebe uma databaseConnection (pode ser uma instância de mysql2, pg, ou outro driver de banco de dados) e usa essa conexão para executar consultas SQL.
Os métodos inserir, atualizar, excluir, e buscarPorId cuidam da comunicação com o banco de dados, ao mesmo tempo que a classe Produto não precisa saber como isso é feito.
Por fim, temos a representação do nosso banco de dados com MySQL, que representa o banco em sí.
É claro que quando utilizamos frameworks ou bibliotecas de ORM com o padrão Data Mapper, nós não precisamos implementar a lógica completa (junto com as consultas SQL), pois isso já é feito pela propria biblioteca/framework por de baixo dos panos.
Um exemplo famoso de implementação do padrão Data Mapper é o Doctrine no PHP, usado em frameworks como Laravel (quando opta-se por não usar Eloquent) e Symfony.
No NodeJS, temos o TypeORM e Prisma que também implementam o padrão Data Mapper, proporcionando flexibilidade para definir como os dados da aplicação são mapeados, e persistidos em bancos de dados relacionais.
🟢 Vantagens:
- A lógica de negócios e a lógica de persistência são separadas, o que pode melhorar a modularidade e a testabilidade.
- Oferece mais flexibilidade para manipular a persistência de dados sem afetar a lógica de negócios.
- Facilita a manutenção e a evolução do código em sistemas complexos.
🔴 Desvantagens:
- Pode exigir mais código e configuração do que o Active Record, pois você terá que definir explicitamente a lógica de persistência.
- Pode ter uma curva de aprendizado mais acentuada para desenvolvedores que estão acostumados com Active Record.
Active Record
O padrão Active Record é um padrão de design que simplifica a interação com o banco de dados, encapsulando os dados e comportamentos em uma única classe.
Sendo muito popular em frameworks de desenvolvimento web, como Ruby on Rails e Laravel.
Vamos observar um exemplo de como o Active Record funciona:
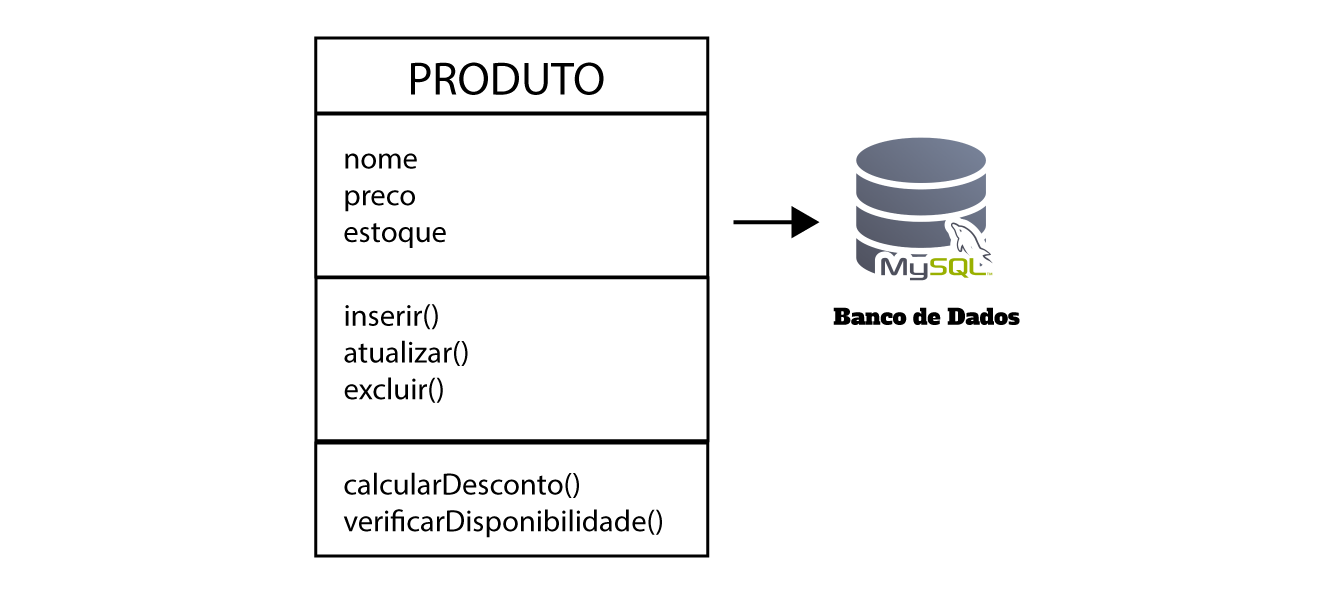
No bloco onde está escrito "PRODUTO", ele é uma classe do seu projeto, que conta os os atributos nome, preco, estoque, junto com os métodos calcularDesconto() e verificarDisponibilidade().
A única diferença, é que ele já implementa dentro da mesma classe, os métodos de comunicação com o banco de dados (inserir, atualizar e excluir).
Se eu fosse representar isso no Javascript, teriamos algo como:
const produto = new Produto();
produto.nome = "SAMSUNG S25";
produto.preco = 9999;
produto.estoque = 10900;
produto.save();//Representação de um método capaz de fazer um insert, por exemplo...🟢 Vantagens:
- Fácil de entender e configurar, especialmente para desenvolvedores iniciantes.
- Reduz a quantidade de código necessário para realizar operações de banco de dados.
- O modelo e a lógica de acesso a dados são colocados juntos, o que pode tornar o código mais intuitivo.
🔴 Desvantagens:
- A lógica de negócios e a lógica de acesso a dados estão fortemente acopladas, o que pode levar a dificuldades na manutenção e testes em aplicações mais complexas.
- Pode ser mais difícil de gerenciar e manter em sistemas grandes e complexos onde a separação de responsabilidades é importante.
Quando usar o Data Mapper e quando usar o Active Record?
Com relação ao Data Mapper, ele é mais adequado para aplicações complexas e grandes, onde a separação clara entre a lógica de negócios e a persistência, são necessários para uma manutenção mais fácil, e também para realizar testes mais eficazes.
Já com relação ao Active Record, é ideal para aplicações simples e rápidas, onde a simplicidade e a rapidez de desenvolvimento são mais importantes do que a complexidade, e a separação clara de responsabilidades.
Quais são os principais ORMs do mercado?
Ruby:
Active Record: Integrado ao Ruby on Rails.
Sequel: ORM independente para Ruby.
Python:
SQLAlchemy: Um dos ORMs mais populares, oferece tanto um ORM como um construtor de SQL.
Django ORM: Integrado ao Django, fornece um ORM para interagir com o banco de dados.
PHP:
Eloquent: ORM integrado ao Laravel.
Doctrine ORM: Um ORM poderoso e flexível para PHP.
Propel: Outro ORM popular para PHP.
Java:
Hibernate: Um dos ORMs mais conhecidos para Java.
JPA (Java Persistence API): Uma especificação de ORM, implementada por Hibernate, EclipseLink, e outros.
JavaScript/TypeScript:
Sequelize: ORM para Node.js que suporta várias bases de dados SQL.
TypeORM: ORM para TypeScript e JavaScript, suporta SQL e NoSQL.
Mongoose: ORM para MongoDB, específico para Node.js.
C#:
Entity Framework: ORM integrado ao .NET Framework e .NET Core.
NHibernate: Uma alternativa ao Entity Framework para .NET.
Swift:
Core Data: Framework de persistência de dados da Apple para aplicações iOS e macOS.
Kotlin:
Exposed: ORM para Kotlin que oferece um DSL para SQL e uma camada de mapeamento objeto-relacional.
Room: Parte da biblioteca Android Jetpack, oferece abstração sobre SQLite para Kotlin/Java no Android.
Scala:
Slick: ORM para Scala que fornece uma API funcional para interagir com bancos de dados relacionais.
Go:
GORM: ORM popular para Go que oferece uma interface de mapeamento objeto-relacional.
Ent: ORM para Go, com foco em criar e gerenciar esquemas de banco de dados de forma declarativa.
Rust:
Diesel: ORM para Rust que oferece segurança e performance em operações de banco de dados.
SeaORM: ORM assíncrono e orientado a dados para Rust, com suporte a várias bases de dados
Conclusão
Fazer o uso de um ORM é uma ótima maneira de seguir um dos conceitos da arquitetura limpa, que é a separação de responsabilidades.
Além disso, a maioria dos projetos empresariais estão adotando bibliotecas e frameworks de ORM em seus projetos, logo, se você quer entrar no mercado de trabalho, vai ter que aprender sobre o uso dos ORMs também 😅
Mas não entenda mal, os ORMs não vieram para substituir as estratégias mais antigas de se comunicar com uma base de dados. Elas continuam existindo, e não há problema algum em adotar tais técnicas em seus projetos.
Mas tenha em mente que tais técnicas estão sendo cada vez mais substituídas por ORMs 😉

