


Concorrência em Go - Parte 1
Quando falamos a palavra concorrência, qual é a primeira coisa que vem na sua mente? 🙃
Posso dizer com absoluta certeza, que a primeira coisa que costumamos imaginar são duas pessoas em uma competição, disputando algo para ver quem vai se sair melhor, estou certo?

E para te falar a verdade, o próprio significado de concorrência no universo do GoLang, não se distancia muito do que vem a ser uma competição/disputa não 😋
Essa história toda de concorrência começou quando a bastante tempo atrás - logo no início do desenvolvimento da linguagem Go -, quando os processadores da época, que até então continham apenas um único núcleo, estavam sendo deixados para trás com o advento dos processadores multicore - uma vez que os processadores de um único núcleo estavam chegando no seu limite de processamento.
Você ainda lembra do primeiro processador Core 2 Duo da Intel?
Nossa, ele foi uma febre na época que lançou, todos queriam ele, seja para jogos, para programação ou processamento de imagens e vídeos. No mundo da computação não se falava nada além desses processadores.
Pois bem, naquela época, existiam pouquíssimas linguagens de programação que sabiam lidar muito bem com processadores multi-core, e advinha qual linguagem era? 😅
Isso mesmo, o GoLang!
Mas aí você pode estar se perguntando... e aonde o significado de competição/disputa entra nessa história toda?
Simples, processadores multi-core estão dividindo tarefas em núcleos diferentes, de modo a executar e entregar suas tasks de forma mais rápida.
Pense num grupo de pessoas que estão dispostas a atender todas as suas vontades de forma hábil, inicialmente você pode imaginar que elas estão competindo entre si - e no fundo no fundo, pode ser que elas estejam mesmo -, porém o que eles não sabem, é que elas estão a favor de algo muito maior, A SUA FELICIDADE!
Eu sei, soou meio cliche demais 😆. Mas é basicamente assim que as coisas funcionam no universo da concorrência em Go.
Agora chega de introdução teórica, e vamos nos aprofundar mais no assunto desta lição 😉
Concorrência vs Paralelismo
Diferente do que estamos acostumados a ver em outras linguagens de programação, o GoLang trouxe uma abordagem bem diferentes e bastante inovadora quando o quesito é lidar com múltiplos núcleos do processador.
Quando falamos sobre concorrência, alguns de nós chegamos a pensar que ela é um sinônimo de paralelismo, mas não, isso está completamente errado, pois nem de longe a concorrência é a mesma coisa que paralelismo.
Fazendo o uso de palavras um pouco mais técnicas e rebuscadas:
A concorrência é um conceito de design que serve para lidar com a estrutura de todo o seu programa, o que permite que ele lide com múltiplas tarefas de forma eficaz.
Isso significa que esse conceito de design pode funcionar sem a necessidade de um sistema multicore, pois não depende de múltiplos processadores para sua execução, sendo plenamente funcional em um processador single-core.
Ou seja, concorrência é só um conceito que é frequentemente usada para melhorar a capacidade de resposta de um programa, seja ele sendo executado em um single-core ou em um multi-core.
Já quando falamos sobre paralelismo, estamos nos referindo a um outro conceito de execução de múltiplas tarefas que estão sendo executadas simultaneamente, em núcleos de uma mesma CPU, ou em processadores separados que estão interligados entre si.
O conceito de paralelismo é usado principalmente para melhorar o desempenho e o rendimento de tarefas computacionalmente intensivas, e até mesmo exaustivas para o computador 🤓
Para ilustrar tudo o que eu disse acima, vamos rever uma ilustração existente na primeira lição desta jornada:
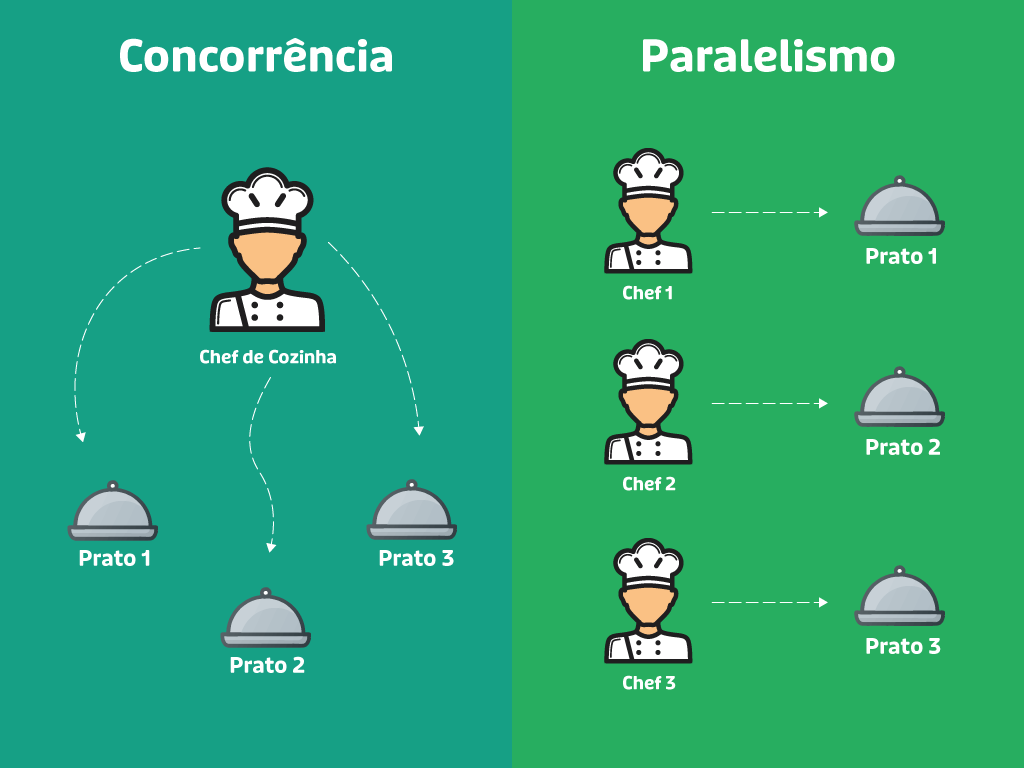
No exemplo acima, temos como concorrência um chef de cozinha, gerenciando várias pratos diferentes ao mesmo tempo, dando atenção a cada uma deles conforme necessário.
E paralelismo, é como ter vários chefs de cozinha, cada um cuidando de um prato ao mesmo tempo, ou seja, focando apenas no seu próprio prato.
É importante ressaltar que o paralelismo é mais custoso do que a própria concorrência, pois existe um certo trabalho adicional para dividir tarefas para múltiplos núcleos/processados, onde posteriormente é necessário sincronizar tudo o que foi processado.
Sendo assim, podem haver casos em que você defina múltiplos processadores para uma determinada tarefa, e no final, essa mesma tarefa ser executada de forma mais lenta do que se fosse feito de outra forma.
Motivo? Houve um Overhead (sobrecarga de controle) adicional, mas via de regra (na maior parte das vezes) ela tende a ficar mais rápida.
Tudo isso que foi dito acima, é feito por meio de um escalonador, mas afinal, você sabe o que ele faz, e para que ele serve? 🧐
O que é um Escalonador?
O escalonador de CPU é um componente do sistema operacional responsável por gerenciar a execução de múltiplas tarefas (processos ou threads) nos núcleos do processador, garantindo assim um uso eficiente dos recursos disponíveis daquele sistema.
E sim, ele é como se fosse um pequeno programinha, ou melhor dizendo... um gestor capaz de direcionar tarefas diferentes para cada um dos membros da sua própria equipe.

Em sistemas multi-core, o escalonador divide as tarefas seguindo alguns desses princípios abaixo:
Passo 1) Identificação de tarefas prontas para execução: o escalonador verifica em primeiro lugar, quais processos ou threads estão prontos para serem executados e os coloca em uma fila de pronto.
Fila de Pronto (ou ready queue em inglês) refere-se a à fila onde os processos ou threads ficam aguardando a CPU para serem executados. Esses processos já estão prontos, ou seja, não estão bloqueados, apenas aguardando sua vez no processador.
Passo 2) Atribuição a um núcleo disponível: em seguida, o sistema pode fazer o uso de diferentes estratégias para distribuir as tarefas entre os núcleos disponíveis, tais como:
- Balanceamento de carga: tem o objetivo de evitar que um núcleo fique sobrecarregado enquanto outros ficam ociosos.
- Afinidade de CPU: mantém threads de um mesmo processo no mesmo núcleo para melhorar a eficiência.
Passo 3) Alternância entre processos (Context Switching): Quando um determinando processo precisa aguardar a chegada de algum recurso (acesso a rede, disco, arquivos etc.), o escalonador pausa a execução e aloca outro processo para usar a CPU em questão.
Passo 4) Preempção (se necessário): Se um processo consome muitos recursos ou ultrapassa seu tempo de CPU, o escalonador pode interromper tal processo, e dar prioridade a outro. É como se ele pensasse: "Nossa, fulano tá demorando muito para fazer essa tarefa... deixa eu repassar para outros que estão disponíveis".
Agora que você já sabe o que é um escalonador, e como ele funciona, vamos dar uma olhada nos principais algoritmos responsáveis por definir a ordem das tarefas (escalonamento):
🔥 Round Robin: Cada tarefa recebe um tempo fixo (quantum) na CPU antes de ser substituída.
🔥 Shortest Job Next (SJN): Dá prioridade às tarefas mais curtas.
🔥 Escalonamento por Prioridade: Processos mais importantes têm maior prioridade.
🔥 Multilevel Queue Scheduling: Divide processos em múltiplas filas (ex.: tempo real, interativo, em lote).
🔥 Completely Fair Scheduler (CFS): Utilizado no Linux, tenta garantir um tempo de CPU justo para todos os processos.
Incrível, não acha? 😊
Mas será que precisamos saber disso tudo para trabalhar com concorrência em Go?
Não! Para trabalhar com concorrência, você não precisa entender profundamente como o escalonador de CPU funciona, pois o próprio runtime do Go gerencia isso para você (de forma automática).
Neste caso, o Go usa um escalonador próprio que roda sobre o sistema operacional e distribui as goroutines automaticamente entre os threads do sistema. Ou seja, você pode simplesmente criar goroutines e deixar o Go cuidar da distribuição entre os núcleos do processador.
E falando sobre goroutines, que tal entendermos um pouco sobre o seu funcionamento? 😌
Conhecendo goroutines
No coração do conceito de concorrência em Go, nos temos uma funcionalidade conhecida como goroutines.
Uma goroutine é uma função executada de forma concorrente pelo runtime do Go. Ela é muito mais leve que uma thread do sistema operacional, e pode ser criada adicionando um simples go antes de chamar uma de suas funções:
go minhaFuncao()A verdade é que o Go gerencia as goroutines com seu próprio escalonador embutido, distribuindo-as dinamicamente entre os núcleos da CPU sem precisar criar múltiplas threads pesadas do sistema operacional.
Sendo assim, podemos observar algumas características:
✅ Goroutines são leves e eficientes: uma única thread do SO pode rodar milhares de goroutines.
✅ Goroutines são gerenciadas pelo runtime do Go: sendo assim, o desenvolvedor não precisa se preocupar com alocação de threads.
✅ Goroutines compartilham memória de forma segura com Channels: evitam problemas de concorrência.
✅ Goroutines executam de forma assíncrona: a função principal continua rodando enquanto outras goroutines executam o resto das operações em paralelo.
Ao contrário dos threads tradicionais existentes em outras linguagens de programação, as Goroutines são projetadas para serem altamente eficientes e fáceis de se trabalhar, observe um exemplo:
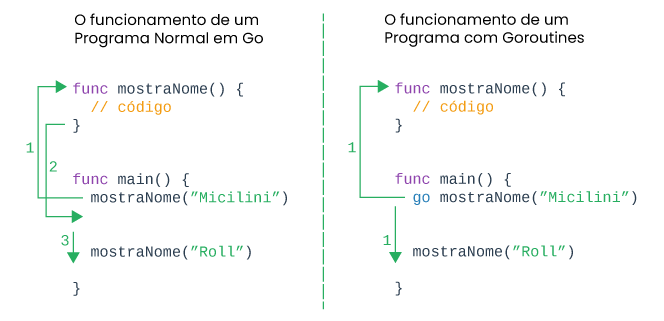
No exemplo acima, o funcionamento normal de um programa em Go acontece em um formato de passo a passo, onde chamamos a função mostraNome("micilini"), e sua segunda chamada mostraNome("roll") só acontece após o término da primeira.
Já quando chamamos uma função por meio do comando go (go mostraNome("Micilini")) estamos fazendo o uso do conceito de concorrência, onde ambas as funções serão executadas de forma simultânea.
É claro que o resultado no terminal pode mostrar algo diferente, o que nos faz pensar que cada uma das funções ali existentes foram executadas uma após a outra, mas se você olhar atentamente (e profundamente) vai perceber que "talvez" o runtime do Go tenha dividido a execução de ambas as funções em núcleos diferentes.
Mas por que "talvez"? 🤨
Porque nem sempre um processo que faz o uso do goruntime sempre irá executar em núcleos diferentes, uma vez que o próprio runtime do go fará um julgamento de forma a analisar se isto é realmente necessário ou não.
Alguns processos são tão básicos e podem ser executados de forma tão rápida, que o runtime do go vê que não vale a pena jogar o processo para um núcleo diferente.
Creio que você deve estar com a mão coçando para colocar a mão na massa, estou certo? 😄
Sim, e eu também estaria se você fosse...
Mas antes, temos um passo super importante, a configuração da pasta do nosso projeto 😅 (como de praxe)
Criando seu projeto de testes
Dentro da pasta JornadaGoLang, nós iremos criar uma nova pasta chamada de 21-concorrencia-em-go, onde dentro dela, vamos criar o nosso arquivo main.go:
package main
func main() {
}Feito isso, partiu então colocar a mão na massa! 😉
Usando o recurso goroutines no seu projeto
Diferente do que você pode estar pensando, goroutines não é uma biblioteca que importamos no nosso projeto, mas sim um recurso nativo da linguagem, assim como um for, if, else etc.
E isso significa que você não precisa instalar nada, e muito menos fazer qualquer tipo de configuração adicional para usá-la 😁
Mas antes de eu te ensinar a usar, gostaria que você desse uma olhada nesse exemplo abaixo:
package main
import "fmt"
func mostrarMensagem(texto string) {
fmt.Println(texto)
}
func main() {
mostrarMensagem("Quando iremos aprender a usar goroutines, micilini?")
}O programa acima demonstra uma execução sequencial simples. Onde chamamos uma simples função (mostrarMensagem) que imprime uma string no terminal:
Quando iremos aprender a usar goroutines, micilini?Se você quiser executar este mesmo programa usando goroutines, você poderia fazer o uso do comando go antes da chamada da função, da seguinte forma:
package main
import "fmt"
func mostrarMensagem(texto string) {
fmt.Println(texto)
}
func main() {
go mostrarMensagem("Quando iremos aprender a usar goroutines, micilini?")
}Se você executar o programa acima, inicialmente você não vai notar diferença nenhuma, pois o resultado foi impresso imediatamente no terminal.
No entanto, a sua função principal (main()) pode ser concluída antes que o goroutine tenha terminado de imprimir "Quando iremos aprender a usar goroutines, micilini?".
Isso se deve à natureza concorrente de Go, pois quando a goroutine principal sai, o programa inteiro termina, interrompendo potencialmente quaisquer goroutines restantes 🥲
Então isso significa que a minha aplicação pode fechar, e a mensagem no terminal nem chegar a aparecer?
Sim, infelizmente... pois no momento o Go não tem autonomia inteligência o suficiente para saber que existem tarefas pendentes antes de terminar o programa.
Uma das formas de "contornar este problema", é adicionando um Sleep para que a sua aplicação "durma" e aguarde um tempo antes de finalizar a função main(), o que daria mais tempo para que o goroutine seja executado:
package main
import (
"fmt"
"time"
)
func mostrarMensagem(texto string) {
fmt.Println(texto)
}
func main() {
go mostrarMensagem("Quando iremos aprender a usar goroutines, micilini?")
// O comando abaixo meio que congela a execução do programa neste ponto, antes de executar os próximos comandos:
time.Sleep(2 * time.Second)// Congela em 2 segundos, tempo suficiente para o goroutine mostrar uma mensagem no terminal
fmt.Println("Final da Main()")
}Com isso, garantiremos que o goroutine tenha tempo o suficiente para ser executado.
Uma outra forma de contar esse problema é fazendo o uso de um for em conjunto com uma variável global, observe:
package main
import (
"fmt"
"time"
)
var mensagemMostrada bool = false
func mostrarMensagem(texto string) {
fmt.Println(texto)
mensagemMostrada = true
}
func main() {
go mostrarMensagem("Quando iremos aprender a usar goroutines, micilini?")
// Loop para aguardar a execução da goroutine
for !mensagemMostrada {
time.Sleep(100 * time.Millisecond) // Pequeno delay para evitar alto consumo de CPU
}
fmt.Println("Final da Main()")
}Entretanto, há uma série de problemas em fazer o uso do Sleep() no seu programa em Go:
Imprecisão: o uso de time.Sleep() adiciona atrasos arbitrários, e a duração da pausa pode não refletir com precisão o tempo necessário para que uma goroutine conclua sua tarefa.
Se uma goroutine demorar mais do que o esperado ou terminar rapidamente, o tempo de espera pode ser insuficiente ou excessivo, afetando o comportamento do programa.
Imprevisibilidade: o tempo real de execução das goroutines pode variar dependendo de fatores como carga do sistema, e disponibilidade de recursos.
Confiar em intervalos de tempo fixos pode levar a condições de corrida e comportamentos inesperados na sua aplicação, tornando o código menos confiável.
Desperdício de Recursos: durante o período de espera, o programa fica essencialmente ocioso, desperdiçando ciclos de CPU que poderiam ser utilizados para outras tarefas.
Esse desperdício pode impactar negativamente o desempenho, especialmente em aplicações de alto desempenho ou que exigem eficiência.
Bloqueio da Execução: quando time.Sleep() é usado na função principal (main), ele bloqueia toda a execução do programa, impedindo que outras operações sejam realizadas enquanto aguarda a conclusão do tempo estipulado.
Isso pode tornar a aplicação menos responsiva e menos eficiente.
Então se um simples uso de um Sleep pode causar esse transtorno todo... quais são as minhas alternativas? 🧐
Atualmente temos duas: Channels e sync.Waitgroup.
Conhecendo Channel (canais) em Go
Como a própria tradução já nos diz, Channels em português significa Canais, que nada mais são do que estruturas que permitem a comunicação e sincronização segura entre as suas goroutines (funções executadas de forma paralela).
Serão por meio dos channels que você poderá bloquear a execução de outras tarefas, enquanto determinadas tarefas ainda estão sendo executadas de forma assíncrona.
Ou de forma mais técnica: São por meio dos channels que você sincroniza suas goroutines ao enviar ou receber dados, a goroutine bloqueia sua execução até que outra goroutine realize a operação correspondente, coordenando tarefas assíncronas.
É importante ressaltar que o bloqueio não é geral, mas ele ocorre durante a operação de send/receive de um canal 😄
Mas antes de vermos tudo isso na prática, é importante que você tenha uma ideia de como criar um channel, ou pelo menos a variável que irá armazenar uma instância de um.
Um Channel pode ser criado por meio do uso do comando Make(), onde no primeiro parâmetro, representamos o tipo de dado que o canal irá transportar (por exemplo, chan int), e o segundo parâmetro — opcional — indica a capacidade do buffer, ou seja, quantos valores podem ficar enfileirados antes de que um novo envio o bloqueie.
Vejamos um exemplo:
// canal de inteiros, sem buffer (unbuffered)
c := make(chan int)
// canal de strings, com buffer de tamanho 3
s := make(chan string, 3)make(chan T): cria um canal não bufferizado que transporta valores do tipo T.
make(chan T, N): cria um canal bufferizado com capacidade N; até N valores podem ser enviados sem bloquear.
É importante ressaltar que você pode criar canais usando quaisquer tipos básicos da linguagem GoLang, como booleanos, strings, inteiros e afins, por exemplo:
// Canal de booleanos (não bufferizado)
boolChan := make(chan bool)
// Canal de strings (não bufferizado)
strChan := make(chan string)
// Canal de inteiros (não bufferizado)
intChan := make(chan int)Perfeito, agora que você já entende como criar um canal, vamos aprender a como fazer o uso de um 🤓
package main
import (
"fmt"
)
// It prints the text and sends a signal to the channel when done. Mostra um texto e envia um sinal para o canal indicando que a execução da função foi finalizada
func mostreAlgo(text string, done chan bool) {
fmt.Println(text)
done <- true // Envie um sinal (verdadeiro) no canal 'concluído' para indicar a conclusão
}
func main() {
done := make(chan bool) // Cria um novo canal do tipo Bool chamado done
go mostreAlgo("Micilini Roll", done)
<-done // Bloqueia a execução das próximas lógicas abaixo até a função mostreAlgo dizer ao Channel que a execução foi finalizada
fmt.Println("Saindo da função principal...")
}O resultado da lógica acima será:
Micilini Roll
Saindo da função principal...Agora vamos às explicações ☺️
Tudo começa quando definimos uma função chamada mostreAlgo, que recebe dois parâmetros principais: text que representa uma string, e um canal chamado de done.
Dentro da função, ele mostra o valor existente na variável text no terminal, e por fim, envia o valor true de volta ao canal, fazendo com que ele entenda que a execução daquela função foi terminada.
Já dentro da função principal (main), nos criamos um canal chamado done, usando a função make(chan bool).
Em seguida, chamamos a função mostreAlgo, usando o termo go antes do seu nome (go mostreAlgo), o que indica que nós lançamos uma nova goroutine, fazendo com que ela seja responsável por executar a função mostreAlgo, e fique aguardando o recebimento de um sinal por meio do canal done que criamos anteriormente.
Por fim, o comando <-done segura a execução da lógica restante até o canal done receber um sinal.
Após receber o sinal (quando a Goroutine estiver concluída), a própria goroutine principal continua a execução do restante do código presente na função main(), imprimindo “Saindo da função principal...”.
Simples, não acha? 🫡
Ainda não! 🫣
No código acima, nós vimos como criar Canais e usá-los em conjunto com goroutines, porém a função mostreAlgo é simples demais para precisar de uma goroutines, concorda?
Para te dar um exemplo um pouco mais "realista", vamos fazer com que a função mostreAlgo durma por uns 5 segundos de forma a simular uma operação lenta e bastante trabalhosa:
package main
import (
"fmt"
"time"
)
// Mostra um texto, dorme 5 segundos e envia um sinal para o canal indicando que terminou
func mostreAlgo(text string, done chan bool) {
fmt.Println(text)
time.Sleep(5 * time.Second) // pausa de 5 segundos
done <- true // sinal de conclusão
}
func main() {
done := make(chan bool) // canal de sinalização
go mostreAlgo("Micilini Roll", done)
<-done // bloqueia até receber o sinal de done
fmt.Println("Saindo da função principal...")
}No exemplo acima, fizemos o uso do módulo "time" para fazer com que a execução do nosso sistema parasse por 5 segundos antes de retornar um sinal de conclusão. O resultado do terminal ainda seria o mesmo visto anteriormente, com a diferença de alguns segundos a mais de demora:
Micilini Roll
Saindo da função principal...Dúvida: Isso significa dizer que sempre que eu for trabalhar com goroutines e canais em GoLang, eu sempre vou precisar fazer o uso dessa estrutura:
- Criar um canal com Make (
s:= make(chan bool)) - Chamar uma função com Go e passar o canal criado via parâmetro (
go mostreAlgo(..., s)) - Aguardar a resposta do canal (
<-s)
Sim, e não! O padrão que nós vimos anteriormente representa uma forma didática de sincronizar uma única goroutine, mas nem de longe é a única forma, e nem algo que você precise repetir toda vez que for fazer o uso de uma goroutine, 😉
Uma outra forma de fazer isso, é criando uma função que retorna um Channel, de forma a encapsular a sincronização, observe:
package main
import (
"fmt"
"time"
)
func mostreAlgo(text string) <-chan bool {
done := make(chan bool)
go func() {
fmt.Println(text)
time.Sleep(5 * time.Second)
done <- true
close(done)
}()
return done
}
func main() {
done := mostreAlgo("Micilini Roll")
<-done
fmt.Println("Pronto")
}Note que no comando acima, nós criamos um canal fora e o passamos por parâmetro, tudo isso para deixá-lo criar e retornar o próprio canal.
E sim, você pode perceber que o código acima ficou bem mais limpo, pois quem é responsável por criar/fechar o canal é a própria função. Entretanto, este estilo padroniza apenas um único sinal de conclusão.
Dúvida: Se é possível criar um canal do tipo bool, string, int etc, será que é possível capturarmos o envio do sinal enviado ao canal?
Sim, isso é totalmente possível. Supondo que você tenha um canal do tipo string, e queria saber o conteúdo retornado por ele, você pode fazer isso da seguinte forma:
package main
import (
"fmt"
)
// sendString envia a mensagem pelo canal e imprime um log
func sendString(ch chan string, msg string) {
fmt.Println("Enviando:", msg)
ch <- msg
}
func main() {
// Cria um canal de strings
msgChan := make(chan string)
// Chama a função em uma goroutine separada
go sendString(msgChan, "Olá, canal de strings!")
// Recebe a mensagem enviada e armazena em 'received'
received := <-msgChan
fmt.Println("Recebido do canal:", received)
}No exemplo acima, estamos salvando dentro da variável received, o conteúdo que foi retornado pelo canal (<-msgChan). Fácil, não? 😁
Criando canais com Buffer
Anteriormente, vimos que é possível criar um canal e passar uma espécie de buffer como segundo parâmetro, você ainda se lembra?
done := make(chan bool, 2)No universo da programação em GoLang, um buffer está relacionado a sua capacidade de armazenar valores internamente, sem que seja preciso uma goroutine receptora imediata.
Em outras palavras, quando você criamos um canal bufferizado (make(chan T, N)) você está criando um canal que suporta até a capacidade de N.
Isso significa dizer, que você pode fazer até N envios consecutivos sem bloqueio, ou seja, o canal guarda esses valores em seu buffer, e só quando o buffer estiver cheio, o próximo send bloqueia até que alguém leia e libere espaço.
E por que um desenvolvedor faria o uso de canais bufferizados? Simples:
Eles desacoplam produtor e consumidor: com buffer, o produtor pode enviar várias mensagens mesmo que o consumidor ainda não esteja lendo, desde que não ultrapasse a capacidade.
Eles aumentam o throughput: em cenários onde produzir dados é rápido e consumir é relativamente mais demorado, o buffer dá folga ao produtor.
Eles controlam o back-pressure: quando o buffer enche, o produtor é automaticamente bloqueado, isso sinaliza ao seu código que o consumidor não está dando conta, sem precisar de lógica extra.
Para exemplificar isso, vamos fazer a seguinte brincadeira:
package main
import (
"fmt"
)
// 3 funções que imprimem um texto e enviam um sinal de conclusão
func mostreAlgo(text string, done chan bool) {
fmt.Println(text)
done <- true
}
func mostreAlgo2(text string, done chan bool) {
fmt.Println(text)
done <- true
}
func mostreAlgo3(text string, done chan bool) {
fmt.Println(text)
done <- true
}
func main() {
// canal bufferizado com capacidade para 2 sinais
done := make(chan bool, 2)
// Disparamos 3 goroutines
go mostreAlgo("Chamou mostreAlgo", done)
go mostreAlgo2("Chamou mostreAlgo2", done)
go mostreAlgo3("Chamou mostreAlgo3", done)
<-done
<-done
<-done
fmt.Println("Saindo da função principal...")
}
O resultado da lógica acima pode variar dependendo de qual função for executada primeiro pelo runtime do Go:
Chamou mostreAlgo
Chamou mostreAlgo3
Chamou mostreAlgo2
Saindo da função principal...No caso do comando acima, nos criamos um único canal que é capaz de administrar diversas goroutines de forma simultânea.
É importante ressaltar que na lógica acima, o canal bufferizado com capacidade para 2 sinais, não diz a respeito que ele só vai conseguir executar duas funções mostreAlgo, de modo a ignorar a terceira, mas sim que ele só determine quantos valores podem ficar “enfileirados” no canal sem que o remetente o bloqueie.
Na lógica acima, como nós fizemos três chamadas para funções diferentes (go mostreAlgo...) e em seguida realizamos três leituras (<-done), significa que estamos recebendo todos os sinais, mesmo tendo um buffer de 2.
Na verdade, o que aconteceu foi:
- As duas primeiras goroutines conseguiram fazer
done <- trueimediatamente, pois cabiam no buffer. - A terceira goroutine só pôde completar o
done <- truedepois que você leu um dos valores do canal, liberando espaço no buffer. - Por fim, Como você leu três vezes, liberou três vagas (duas vagas já haviam sido usadas + a vaga liberada pela primeira leitura), e assim todas as goroutines foram concluídas.
Para exemplificar isso de uma forma mais didática, vamos analisar outro exemplo abaixo:
package main
import (
"fmt"
"time"
)
func send(id int, ch chan int) {
fmt.Printf("Goroutine %d: antes de enviar\n", id)
ch <- id
fmt.Printf("Goroutine %d: depois de enviar\n", id)
}
func main() {
ch := make(chan int, 2) // buffer de capacidade 2
// Dispara 3 goroutines que tentam enviar
go send(1, ch)
go send(2, ch)
go send(3, ch)
// Dá um tempinho para vermos as duas primeiras passarem
time.Sleep(500 * time.Millisecond)
// Vamos ler apenas UMA vez
fmt.Println("Main: lendo um valor ->", <-ch)
// Aguarda mais um pouco para destravar a 3ª goroutine
time.Sleep(500 * time.Millisecond)
// Leitura final para esvaziar o canal
fmt.Println("Main: lendo os restantes ->", <-ch, <-ch)
}Veja o resultado do terminal:
Goroutine 1: antes de enviar
Goroutine 1: depois de enviar // 1 enfileirado
Goroutine 2: antes de enviar
Goroutine 2: depois de enviar // 2 enfileirado (buffer cheio)
Goroutine 3: antes de enviar // chega aqui e **bloqueia** no ch <- 3
Main: lendo um valor -> 1 // libera espaço no buffer
Goroutine 3: depois de enviar // agora consegue enfileirar o 3
Main: lendo os restantes -> 2 3
(Lembrando que o resultado pode não ter o mesmo resultado na sua máquina, ok?)
- Buffer = 2: permite que 2 envios sucedam sem bloqueio.
- O 3º envio bloqueia até que você faça uma leitura e libere uma vaga.
- Depois de ler todas as mensagens do canal (fazendo
<-chtantas vezes quantos valores foram enviados), você recebe todos os valores, independentemente do tamanho do buffer.
Em resumo:
- Se o buffer está cheio, o próximo
sendfica bloqueado até alguém ler e liberar espaço. - Além disso, um buffer não representa o limite de quantas quantas goroutines você pode usar ou quantos
<-chvocê pode fazer no total — apenas controla o comportamento de bloqueio/espera.
Sendo assim podemos concluir que o buffer nada mais é do que a representação de um chef de cozinha, e suas funções com goroutines um prato a ser feito.
No exemplo acima, tínhamos 3 pratos na fila (3 chamadas para funções usando goroutines), e apenas 2 chefes de cozinha disponíveis (buffer de 2), onde o terceiro prato só seria produzido quando um dos dois chefs terminassem sua tarefa.
No final das contas, o terceiro prato também seria entregue de uma forma ou de outra, porém ele só seria feito após um dos chefs concluir o prato atual.
Conhecendo o Sync.WaitGroup
Além dos canais (channels), você também pode gerenciar operações assíncronas usando a biblioteca sync.WaitGroup do pacote sync, que é uma biblioteca pensada para sincronizar um conjunto de goroutines sem precisar criar canais de sinalização manualmente.
Ele funciona como um contador de "tarefas independente", onde conseguimos adicionar (Add) quantas goroutines serão lançadas, sinalizando sua conclusão com o Done().
Tudo começa quando importamos a referência dessa biblioteca em nosso arquivo em Go:
import "sync"Ou caso estiver usando mais de uma biblioteca em seu arquivo:
import(
....
"sync"
)Após isso, dentro da sua função Main(), o ideal é que você crie uma nova variável que seja responsável por criar um WaitGroup:
var wg sync.WaitGroupEm seguida, precisamos definir a quantidade de goroutines que serão executadas usando a função Add:
wg.Add(n int)Após o comando Add(), o ideal é que você chame suas funções por meio do comando go, da mesma forma como fizemos com os canais, mas sem se esquecer de passar o WaitGroup:
go mostreAlgo("Micilini Roll", &wg)Já dentro de cada uma de nossas funções, executamos o comando Done() de modo a decrementar o contador em 1:
func mostreAlgo(text string, wg *sync.WaitGroup){
defer wg.Done() // garante que sempre decrementa o contador
//....
}Costuma-se usar defer wg.Done() logo na entrada da goroutine, garantindo que mesmo em caso de pânico ou return antecipado, aquele contador será decrementado.
E por fim, usamos o comando wg.Wait() para bloquear até que o contador interno seja igual a zero(até que todas as goroutines sinalizadas com Add chamem Done):
wg.Wait()Agora chega de papo e vamos ver tudo isso que eu disse acima na prática 😆
package main
import (
"fmt"
"sync"
)
func mostreAlgo(text string, wg *sync.WaitGroup) {
defer wg.Done() // Sinaliza que esta Goroutine está pronta quando a função sai
fmt.Println(text)
}
func main() {
var wg sync.WaitGroup // Cria uma WaitGroup
wg.Add(1) // Incrementa o contador WaitGroup
go mostreAlgo("Micilini Roll", &wg)
wg.Wait() // Espera que todas as GoRoutines terminem
fmt.Println("Saindo da função principal...")
}Tudo começa com a criação de um WaitGroup chamado wg. Em seguida incrementamos nosso contador (Add) para refletir o número de goroutines que serão esperadas.
Como no exemplo anterior só chamamos uma única função, inserimos o valor 1 dentro de Add.
Já dentro da função mostraAlgo, somos obrigados a declarar o comando Done em conjunto com defer, de modo a sinalizar que a goroutine concluiu sua tarefa com sucesso.
Por fim, fechamos nosso WaitGroup com o Wait(), impedindo que comandos posteriores a isso tenham que aguardar a execução final das nossas goroutines.
Dúvida: Isso significar dizer que todas minhas goroutines que quero que sejam aguardadas pelo restante do sistema, estejam encapsuladas pelos comandos Add() e Wait()?
Sim, se você quiser que o programe aguarde a execução de todas as suas goroutines e estiver usando a biblioteca WaitGroup, a lógica é essa mesmo.
Só não se esqueça de definir dentro de Add a quantidade de goroutines que deverão ser aguardadas, e chamar cada uma de suas funções com o comando go 😌
Dúvida: O que acontece se eu inserir 3 goroutines entre Add e Wait, mas só definir duas esperas dentro de Add, por exemplo:
package main
import (
"fmt"
"sync"
)
func task(id int, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("Task %d concluída\n", id)
}
func main() {
var wg sync.WaitGroup
wg.Add(2) // Só adicionamos duas “esperas” ao WaitGroup
go task(1, &wg)
go task(2, &wg)
go task(3, &wg) // Terceira goroutine
wg.Wait()
fmt.Println("Todas as tarefas esperadas concluídas")
}Simples, o wg.Add(2) define o contador interno para 2. Já as duas primeiras goroutines que forem executadas chamarão o Done(), o que reduz o contador para 0.
Porém, quando o GoLang executar a terceira goroutine, assim que o sistema bater no Done() e tentar reduzir de 0 para -1, o sistema retornará um panic:
Task 1 concluída
Task 2 concluída
panic: sync: negative WaitGroup counter
goroutine 6 [running]:
sync.(*WaitGroup).Add(0xc0000xxxx0, -1)
/usr/local/go/src/sync/waitgroup.go:74 +0x...
exit status 2Mas e se você tentar remover o Done() de uma de suas goroutines?
Neste caso, o contador começaria em 2, você só chamaria Done() duas vezes (nas outras duas goroutines), e o wg.Wait() ficaria bloqueado para sempre, pois o contador jamais chegaria a zero — resultando em deadlock 🥶
Portanto, para evitar futuros problemas garanta que você informou o número certo de goroutines dentro do seu Add antes de continuar! 😁
O que é uma condição de corrida em Go? (Race Condition)

Uma condição de corrida (Race Condition) é uma das situações que acontece com certa frequência na programação concorrente, onde o comportamento de um programa depende do tempo relativo dos eventos que estão acontecendo em paralelo, o que resulta em resultados inesperados e errôneos.
Imagine uma corrida que está acontecendo entre várias threads ou goroutines que lutam entre si para acessar recursos compartilhados, isso é uma condição de corrida 😮
Além disso, o resultado da corrida pode variar dependendo de qual thread ou goroutine "vença", ou seja, consegue entregar uma tarefa primeiro.
Em GoLang, nós podemos fazer o uso da flag -race em conjunto com go build, go test ou go run para habilitar o Go Race Detector, que nada mais é do que uma ferramenta integrada que foi construída para detectar e diagnosticar condições de corrida de dados que acontecem em programas feitos com Go.
Para exemplificar isso, vamos voltar naquele exemplo onde temos 3 goroutines executando de forma simultânea:
package main
import (
"fmt"
"sync"
)
func task(id int, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("Task %d concluída\n", id)
}
func main() {
var wg sync.WaitGroup
wg.Add(3)
go task(1, &wg)
go task(2, &wg)
go task(3, &wg)
wg.Wait()
fmt.Println("Todas as tarefas esperadas concluídas")
}Se executarmos a lógica acima em nosso terminal passando a flag -race:
go run -race main.goPodemos nos deparar com duas respostas distintas:
1) O CGO não está habilitado:
go: -race requires cgo; enable cgo by setting CGO_ENABLED=1Como a flag -race depende de código C gerado pelo CGO, se ele não estiver habilitado (CGO_ENABLED=0, como costuma ser o padrão no Windows sem um compilador C instalado), o build com -race não funciona.
Uma forma de tentar contornar este erro em versões mais novas do GoLang é inserindo a flag -race no final:
go run main.go -raceCaso isso não adiantar, uma forma mais fácil de habilitar o CGO é executando um dos comandos abaixo no seu terminal:
1.1) Se estiver usando o PowerShell use:
$Env:CGO_ENABLED = "1"
go run -race main.go
1.2) Se estiver usando um terminal Unix-like (Git Bash, WSL, etc.)
export CGO_ENABLED=1
go run -race main.go
Se precisar apontar explicitamente, também defina a variável CC. Exemplo no Bash:
export CC=x86_64-w64-mingw32-gcc # exemplo para MinGW
export CGO_ENABLED=1
go run -race main.goPara mais informações sobre como ativar o CGO consulte a documentação da ferramenta.
2) Retorno padrão
Task 1 concluída
Task 2 concluída
Task 3 concluída
Todas as tarefas esperadas concluídasA verdade é que a flag -race só imprimiria algo se houvesse acesso concorrente indevido à memória, mas como tudo está sincronizado corretamente pelo o WaitGroup, então não haverão alertas a serem emitidos 😅
Agora, se alterássemos nosso código para algo como:
wg.Add(2)
go task(1, &wg)
go task(2, &wg)
go task(3, &wg)
wg.Wait()A flag -race retornaria o seguinte erro:
Task 1 concluída
Task 2 concluída
Task 3 concluída
Todas as tarefas esperadas concluídas
panic: sync: negative WaitGroup counter
goroutine 8 [running]:
sync.(*WaitGroup).Add(0xc000026270?, 0x0?)
C:/Program Files/Go/src/sync/waitgroup.go:64 +0xd8
sync.(*WaitGroup).Done(...)
C:/Program Files/Go/src/sync/waitgroup.go:89
main.task(0x0?, 0x0?)
C:/Users/William Lima/Desktop/GoLang/main.go:11 +0x96
created by main.main in goroutine 1
C:/Users/William Lima/Desktop/GoLang/main.go:20 +0xe5
exit status 2Devido ao fato de criarmos o contador do WaitGroup com valor 2, porém foi disparado 3 goroutines que fazem o uso do wg.Done(), ou seja, criamos uma condição de corrida.
De qualquer forma, o GoLang vai executar perfeitamente seu código, mas tenha em mente que isso poderá prejudicar sua aplicação futuramente, por esse motivo é sempre bom definir o número certo dentro do comando Add().
Mutex e Condição de Corrida (Race Condition)
Um Mutex (de "mutual exclusion") em Go é um objeto do pacote sync que garante que apenas uma goroutine por vez entre em uma seção crítica – isto é, um trecho de código que acessa ou modifica um recurso compartilhado.
Basicamente, enquanto uma goroutine segura o mutex (Lock()), qualquer outra que tentar fazer Lock() ficará bloqueada até que o mutex seja liberado (Unlock()).
Para usar o Mutex em Go, é bem simples, primeiro precisamos declará-lo:
var mu sync.MutexEm seguida, dentro da seção crítica, devemos travar o acesso ao recurso compartilhado:
mu.Lock()
// ... código que acessa recurso compartilhado ...E após isso, destravar logo em seguida:
// ... código que acessa recurso compartilhado ...
mu.Unlock()
É idiomático usar defer imediatamente após o Lock, por exemplo:
mu.Lock()
defer mu.Unlock()
// seção críticaVejamos agora um exemplo completo dos comandos aprendidos acima em ação:
package main
import (
"fmt"
"sync"
)
func main() {
var (
counter int
mu sync.Mutex
wg sync.WaitGroup
)
numWorkers := 5
wg.Add(numWorkers)
for i := 1; i <= numWorkers; i++ {
go func(id int) {
defer wg.Done()
mu.Lock() // bloqueia o acesso ao counter
defer mu.Unlock() // libera quando sair do bloco
// seção crítica
counter++
fmt.Printf("Goroutine %d incrementou contador para %d\n", id, counter)
}(i)
}
wg.Wait() // espera todas as goroutines terminarem
fmt.Println("Valor final do contador:", counter)
}Tudo começa quando declaramos um counter compartilhado, junto com um sync.Mutex (mu) e um WaitGroup (wg).
Em seguida, dentro da nossa função main, nós disparamos 5 goroutines, onde cada uma executa a seguinte lógica:
- Dispara o
mu.Lock()para ter acesso exclusivo aocounter. - Incrementa
countere imprime o valor. - Executa o
mu.Unlock()(viadefer) logo em seguida, liberando-o para a próxima.
Além disso, temos a presença do comando wg.Wait() que é responsável por bloquear o main até todas as goroutines chamarem wg.Done().
No final, vemos um contador consistente (de 1 a 5), sem interferência entre as goroutines.
Dúvida: "No final, vemos um contador consistente (de 1 a 5), sem interferência entre as goroutines...", então quer dizer que sem o uso do Mutex, podemos ver contadores aleatórios, como: 3, 2, 1, 5 ou 1, 2, 5, 4, 3 etc?
Exatamente, pois sem nenhum mecanismo de sincronização (mutex, canal, etc.), suas goroutines fazem data race ao incrementarem o mesmo contador, e com isso o valor final, e até os valores intermediários podem ser totalmente imprevisíveis, podendo perder incrementos ou ter leituras “atrasadas”.
Por que usar o Mutex?
Quando fazemos o uso do Mutex nós evitamos condições de corrida (race conditions) em variáveis ou estruturas de dados compartilhados.
Não só isso, como seu uso é forma mais simples e direta, pois com ele você consegue controlar exatamente onde começa e termina a seção crítica.
E por fim, e não menos importante, ele é usado para complementar outros mecanismos, ou seja, você pode usar Mutex junto com WaitGroup e até channels, dependendo do padrão de concorrência que melhor se encaixa no seu problema.
A grande verdade é que quando combinamos o sync.Mutex para proteger dados e sync.WaitGroup para sincronizar o término das goroutines, nós conseguimos construir programas concorrentes em Go de forma segura e determinística.
Sem o uso do Mutex, podemos enfrentar este probleminha aqui, observe:
package main
import (
"fmt"
"sync"
)
func worker(id int, wg *sync.WaitGroup, counter *int) {
defer wg.Done()
*counter++ // data race aqui!
fmt.Printf("Goroutine %d: counter = %d\n", id, *counter)
}
func main() {
var (
counter int
wg sync.WaitGroup
)
for i := 1; i <= 5; i++ {
wg.Add(1)
go worker(i, &wg, &counter)
}
wg.Wait()
fmt.Println("Valor final do contador:", counter)
}Onde podemos ter as seguintes saídas:
Goroutine 2: counter = 1
Goroutine 1: counter = 2
Goroutine 5: counter = 3
Goroutine 3: counter = 3 // aqui o incremento da 4 pode ter sido “sobreposto”
Goroutine 4: counter = 4
Valor final do contador: 4Ou quem sabe:
Goroutine 4: counter = 1
Goroutine 3: counter = 2
Goroutine 1: counter = 3
Goroutine 2: counter = 3
Goroutine 5: counter = 4
Valor final do contador: 4
Ou até mesmo:
Goroutine 5: counter = 1
Goroutine 3: counter = 1
Goroutine 2: counter = 2
Goroutine 1: counter = 3
Goroutine 4: counter = 4
Valor final do contador: 4
Em alguns casos você verá Valor final do contador: 3 se dois ou mais incrementos “colidirem” e um sobrescrever o outro. A ordem e o resultado são não-determinísticos sem sincronização.
Entende agora por que o Mutex é importante? 😅
Seleção de canais com Go
No Go nós temos acesso a um recurso muito poderoso chamado de select, que nos ajuda a coordenar goroutines via canais.
Ele funciona de forma bastante similar ao Switch, a diferença é que ao invés de avaliar expressões, ele escolhe operações de comunicação (envio ou recebimento em canais) que estejam prontos.
A sintaxe básica de um select em Go é a seguinte:
select {
case x := <-ch1:
// se ch1 tiver valor pronto, executa aqui
case ch2 <- y:
// se ch2 puder enviar, executa aqui
default:
// (opcional) executa se nenhum canal estiver pronto
}O select é usado para bloquear até que uma das operações de canal esteja pronta, e então executa o bloco correspondente.
Se houver vários canais prontos, Go escolhe um aleatoriamente, garantindo prioridade igualitária.
Porém, se nenhum estiver pronto e houver default, executa o default imediatamente (não bloqueia).
Vamos ver agora um exemplo completo do uso do select em Go:
func main() {
ordersA := make(chan int)
ordersB := make(chan int)
go feed(ordersA, 100*time.Millisecond)
go feed(ordersB, 250*time.Millisecond)
for i := 0; i < 5; i++ {
select {
case o := <-ordersA:
fmt.Println("Pedido A:", o)
case o := <-ordersB:
fmt.Println("Pedido B:", o)
case <-time.After(300 * time.Millisecond):
fmt.Println("Nenhum pedido em 300ms — fazendo manutenção")
}
}
}
// feed envia inteiros a cada intervalo dado
func feed(ch chan<- int, interval time.Duration) {
for i := 1; ; i++ {
time.Sleep(interval)
ch <- i
}
}No código acima o feed em A e B disparam pedidos com ritmos diferentes, já o select consome de A, B ou, se ficar 300 ms sem nada, faz manutenção (timeout).
O loop executa 5 iterações, demonstrando múltiplas formas de uso de select.
Em resumo, o imagine o select como se fosse uma espinha dorsal da concorrência orientada a canais em Go, onde podemos:
- Esperar múltiplos eventos simultaneamente
- Implementar timeouts e cancelamentos
- Construir pipelines dinâmicos
- Garantir fairness e controle fino sobre bloqueios
Ufa!
Até o momento aprendemos bastante coisas relacionadas com a concorrência em GoLang 😮💨
Que tal darmos uma pausa antes de seguirmos para a parte 2? 🙃
Repositório da lição
Todos os arquivos relacionados com esta lição, podem ser encontrados nos seguintes repositórios abaixo:
Conclusão
Nesta lição, você aprendeu um pouco mais sobre goroutines, concorrência, paralelismo, channels, WaitGroup e Select.
Respira mais um pouco, e partiu para a segunda parte 😄

