No material anterior nós aprendemos um pouco como funciona o processo de colaboração entre os desenvolvedores usando o Fork Workflow.
Recapitulando, com ele nós começamos com uma cópia de um determinado repositório, realizamos modificações nos códigos para que mais tarde, possamos fazer um Pull Request, e esperar que o dono do repositório original faça um merge.
E o mesmo processo se aplica a cada colaborador existente naquele repositório:

Entretanto, quando existe um fluxo intenso de trabalho que está acontecendo de forma simultânea entre os colaboradores, aonde muitas vezes diversos colaboradores precisam estar a par das modificações de outros colaboradores, nós podemos ter essa pequena confusão aqui:

Imagina todos os colaboradores tendo que rastrear o Fork dos outros colaboradores, para entender o que cada um está fazendo ou deixando de fazer no mesmo projeto?
Complicado, não?
Apesar dessas complicações, geralmente os donos dos repositórios estabelecem regras de modo a “barrar” essas complexidades, permitindo que elas não ocorram.
Então é possível configurar certos filtros nas configurações de um determinado repositório?
Não, quando eu digo “regras”, digo que determinados donos de repositório criam documentos do tipo .README que estabelecem regras e dicas de como desenvolver e trabalhar melhor em equipe.
De modo a evitar que complicações como essas, aconteçam de fato.
Exemplo de uma possível regra criada por usuários do GitHub:
+ Regra N° 1 – Se você quer adicionar uma nova funcionalidade, faça isso sem precisar depender de outra funcionalidade ou modificação catalogada nas Issues.
Um exemplo prático, é quando temos duas Issues relacionadas a um determinado repositório.
A primeira (Issue #1) diz a respeito da necessidade de uma tela de login (Back-end e Front-end), e a segunda (Issue #2) diz que é necessário criar um banco de dados para a tela de login e cadastro de clientes.
Imaginando que o projeto tenha dois colaboradores, se o primeiro colaborador pegar a Issue #1, e o segundo a Issue #2, em algum ponto do projeto eles vão precisar sincronizar seus Forks.
Uma vez que o colaborador um vai precisar se comunicar com o banco de dados para recuperar algumas informações, do mesmo modo que o colaborador dois, vai precisar entender a lógica da tela de login para criar uma tabela otimizada, não é verdade?
Se a Regra N° 1 for respeitada pelos colaboradores, o colaborador que pegou a Issue #1, inevitavelmente terá que resolver também a Issue #2.
Já com a metodologia do GitHub Workflow, nós temos um fluxo de trabalho mais simplificado.
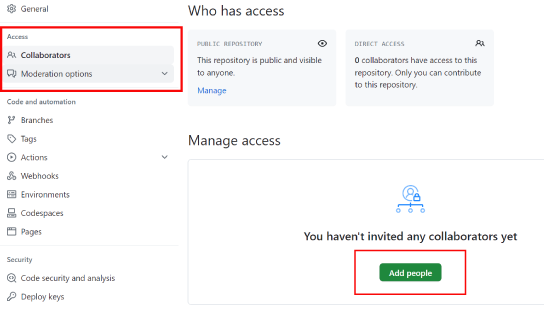
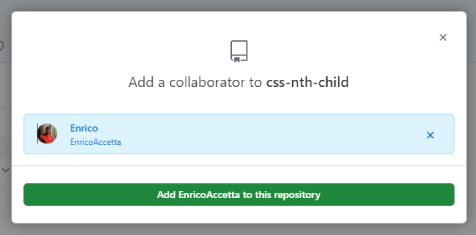
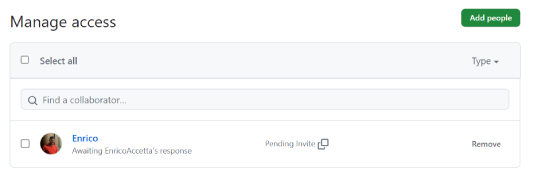
No Git Workflow, cada pessoa que colabora com um determinado projeto, é um desenvolvedor cadastrado dentro do repositório original, permitindo que eles façam um clone direto do repositório original, e envie alterações diretamente para ele, excluindo a necessidade de se realizar um Pull Request.
É como se o repositório original fosse seu, de modo que quando você fizer um PUSH, todos os outros colaboradores terão acesso as suas modificações com um simples PULL.
Para você que ainda não entendeu, é como se você criasse uma nova branch em um repositório que você tem acesso.