


Dividindo a imagem em blocos (8×8, 16×16) e por que fazer isso?
Olá leitor, seja muito bem vindo de volta a mais uma etapa da nossa jornada aqui no Portal da Micilini 😊
Este é o oitavo artigo da nossa série de ~20, e marca o início da Fase 3 — O Coração de um CODEC de Imagem.
Nos últimos 7 artigos, construímos duas bases sólidas:
- Fase 1 (artigos 1-3): aprendemos como cores funcionam, o que é RGB, YCbCr e Chroma Subsampling.
- Fase 2 (artigos 4-7): aprendemos os fundamentos de compressão — entropia, RLE, Huffman e LZ77/DEFLATE.
Agora chegou a hora de juntar tudo.
A Fase 3 é onde a teoria se transforma na prática de um CODEC real. É aqui que vamos entender exatamente como o JPEG funciona por dentro, e como o nosso CODEC autoral vai funcionar.
E o primeiro passo dessa jornada é entender por que os CODECs de imagem dividem a imagem em blocos pequenos antes de fazer qualquer compressão.
Parece um detalhe bobo, certo? "Ah, é só cortar a imagem em quadradinhos."
Mas essa decisão aparentemente simples tem implicações profundas em termos de qualidade, velocidade e eficiência de compressão.
Então pega seu café ☕, sente-se confortavelmente, e vamos entrar no coração de um CODEC de imagem!
Por que não processar a imagem inteira de uma vez?
Antes de entender por que dividimos em blocos, vamos entender por que não processamos a imagem inteira de uma vez.
No próximo artigo, vamos aprender a DCT (Discrete Cosine Transform), a transformada matemática que converte pixels em frequências. Essa é a etapa mais importante do pipeline do JPEG.
A DCT precisa operar sobre um conjunto de pixels e transformá-los em coeficientes de frequência. Teoricamente, você poderia aplicar a DCT na imagem inteira (todos os pixels de uma vez). Isso é o que alguns formatos mais sofisticados fazem (como o JPEG 2000 com wavelets).
Só que... se você optar por este caminho em pleno 2026, você vai se deparar com os seguintes problemas:
Problema 1 — Memória:
Se resolvéssemos aplicar isso em uma imagem Full HD (1920×1080), teríamos que fazer isso com 2.073.600 pixels.
Se aplicarmos a DCT na imagem inteira, precisamos de uma matriz de 2.073.600 × 2.073.600 pra armazenar os coeficientes da transformada.
Isso daria mais de 4 trilhões de elementos, supondo que são 4 bytes por elemento (float), seriam mais de 16 terabytes de memória. Só pra uma foto.
É obviamente impossível com a tecnologia que temos hoje 🫣
Mesmo com otimizações, a complexidade computacional de uma DCT num bloco de N×N pixels é O(N² log N). Com N = 1920 (só uma dimensão!), o custo é absurdamente maior do que com N = 8.
Problema 2 — Velocidade
A complexidade da DCT cresce com o tamanho do bloco. Uma DCT em 8×8 (64 pixels) é extremamente rápida.
Isso se dá de forma tão rápida que processadores modernos têm instruções especializadas pra calcular DCT 8×8 em poucos ciclos de clock (a instrução SSE/AVX dos processadores Intel e AMD foi otimizada pra esse tamanho).
Uma DCT na imagem inteira seria ordens de magnitude mais lenta, mesmo com hardware especializado.
Problema 3 — Localidade
Aqui vem a razão mais sutil e mais importante.
Na maioria das imagens reais, as características visuais mudam de região pra região. Uma foto de uma pessoa na praia tem:
- Céu: área suave, poucas frequências altas, muito uniforme
- Rosto: área com detalhes médios, texturas de pele, contornos
- Cabelo: área com muita textura, muitas frequências altas
- Areia: textura granular, frequências médias a altas
- Espuma do mar: alto contraste, bordas nítidas
Se aplicarmos uma transformada na imagem inteira, estamos jogando todas essas características diferentes num único caldeirão. A transformada não consegue tratar cada região de forma otimizada. Ela produz uma "média geral" que não é ótima pra nenhuma região específica.
Mas se dividirmos a imagem em blocos pequenos (8×8 pixels), cada bloco contém uma região relativamente homogênea da imagem. Um bloco de céu será processado como "conteúdo suave", um bloco de cabelo será processado como "conteúdo com muita textura". A compressão pode ser otimizada pra cada bloco individualmente.
É como a diferença entre fazer uma dieta genérica (todo mundo come a mesma coisa) e uma dieta personalizada (cada pessoa recebe o que funciona pra ela).
E não preciso nem dizer que a abordagem personalizada é mais eficiente.
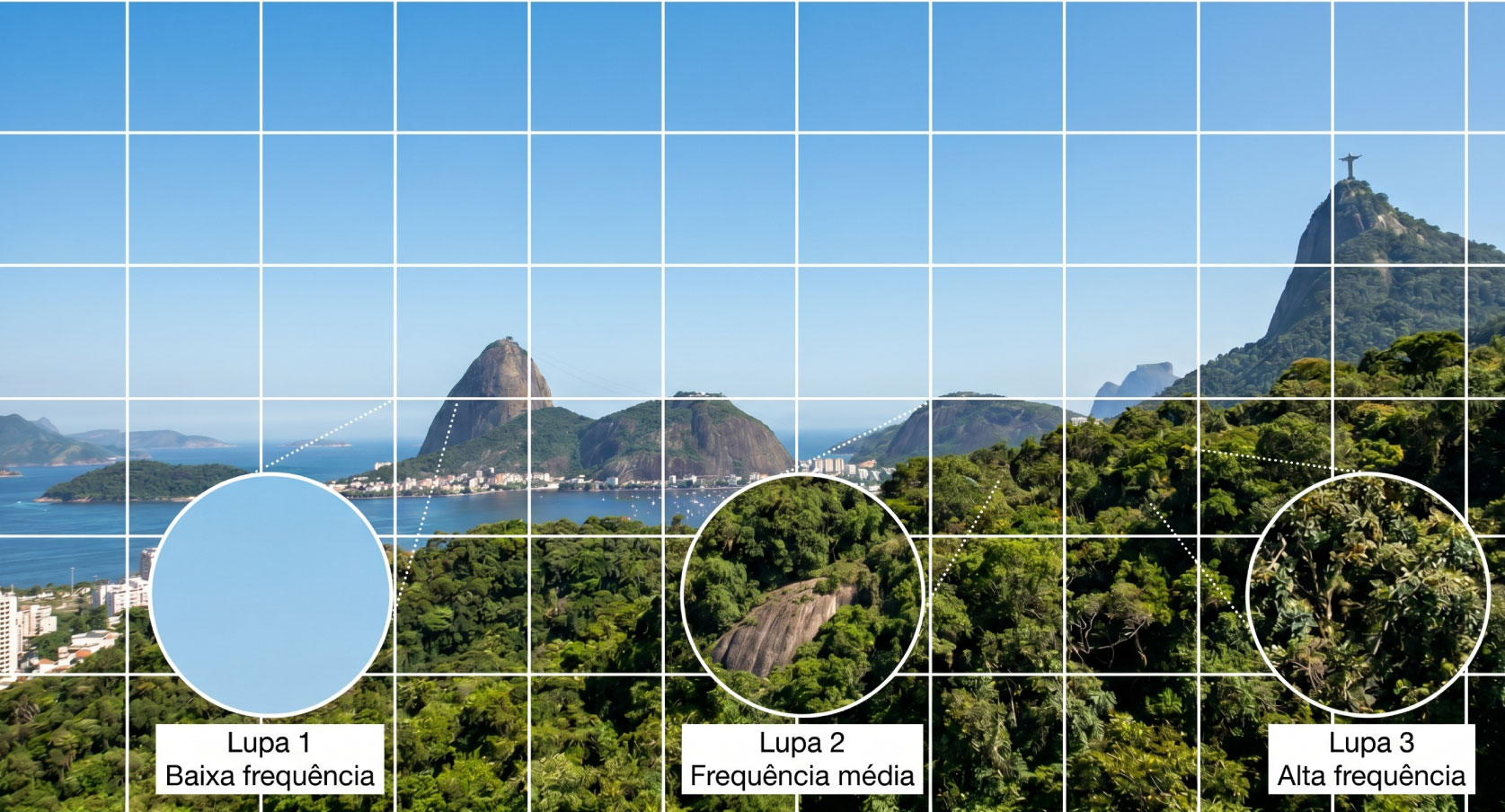
O tamanho mágico: por que 8×8?
Já vimos anteriormente que faz bastante sentido dividir em blocos, mas porque especificamente 8x8? Por que não 4×4, ou 16×16, ou 32×32?
A escolha do 8×8 no JPEG (e em muitos outros CODECs) não foi arbitrária. Ela é o resultado de um equilíbrio cuidadoso entre vários fatores que veremos abaixo.
Fator 1 — Eficiência da DCT
Blocos maiores significam uma DCT com mais coeficientes, o que teoricamente permite uma representação mais precisa das frequências. Mas depois da quantização (artigo 10), a maioria dos coeficientes de alta frequência será zerada de qualquer jeito. Então ter muitos coeficientes não ajuda tanto.
Com 8×8 temos 64 coeficientes, temos o suficiente pra representar bem as variações de brilho e cor dentro de um bloco pequeno, sem desperdício.
Com 4×4 temos 16 coeficientes, teríamos representação muito limitada. Cada bloco seria quase uma "média" com poucos detalhes.
Com 16×16 temos 256 coeficientes, teríamos muitos coeficientes extras que seriam zerados na quantização, desperdiçando bits no cabeçalho sem ganho real de qualidade.
Fator 2 — Artefatos de bloco (blocking artifacts)
Esse é o trade-off mais visível. Lembra daqueles quadradinhos que aparecem quando você comprime demais um JPEG? Aqueles quadradinhos têm exatamente o tamanho dos blocos, e eles são os artefatos de bloco.
Eles aparecem porque cada bloco é processado de forma independente. Nas bordas entre dois blocos vizinhos, os valores quantizados podem ser ligeiramente diferentes, criando uma "costura" visível.
Blocos menores (4×4) criam mais costuras por área, mas cada costura é menos perceptível (porque a diferença entre blocos vizinhos de 4×4 tende a ser menor). Blocos maiores (16×16) criam menos costuras, mas cada uma pode ser mais perceptível (porque regiões maiores são "homogeneizadas").
O 8×8 é o ponto onde os artefatos são toleráveis em qualidade média e quase invisíveis em qualidade alta.
💡 Curiosidade: Os CODECs de vídeo modernos (H.264, H.265, AV1) usam tamanhos de bloco variáveis. Em vez de sempre usar 8×8, o encoder analisa cada região e escolhe o melhor tamanho: 4×4 pra bordas nítidas, 16×16 ou 32×32 pra áreas suaves. Isso produz resultados muito melhores, mas é muito mais complexo de implementar. O H.265 pode usar blocos de 4×4 até 64×64!
Fator 3 — Hardware e história
Quando o JPEG foi padronizado em 1992, os computadores da época tinham processadores muito mais lentos que os de hoje. Uma DCT 8×8 podia ser calculada eficientemente com os recursos disponíveis. Blocos maiores teriam sido impraticáveis na velocidade necessária pra aplicações em tempo real.
Além disso, o 8 é uma potência de 2 (2³), o que permite otimizações com shifts de bits e alinhamento de memória em praticamente qualquer arquitetura de processador.
Hoje em dia, processadores modernos incluem instruções SIMD (Single Instruction, Multiple Data) como SSE e AVX que foram literalmente projetadas pra calcular DCTs 8×8 de forma ultra-rápida. Os fabricantes de CPU otimizaram pra esse tamanho justamente porque é o mais usado.
Fator 4 — Homogeneidade local
Em uma imagem típica, uma região de 8×8 pixels é pequena o suficiente pra conter conteúdo relativamente uniforme (dentro da mesma textura, dentro da mesma superfície). Mas grande o suficiente pra capturar variações locais significativas (um gradiente, uma borda, um detalhe).
Com 4×4, muitos blocos conteriam apenas uma cor quase sólida, desperdiçando coeficientes. Com 32×32, muitos blocos conteriam múltiplas texturas diferentes, prejudicando a eficiência da DCT.
Pra ter uma noção de escala: num monitor Full HD (1920×1080), a imagem é dividida em 240 × 135 = 32.400 blocos de 8×8 pixels. Cada bloquinho mede cerca de 0.1mm × 0.1mm na tela. Quase invisível ao olho nu.
Blocos 16×16: o macroblock dos codecs de vídeo
Embora o JPEG use blocos de 8×8 pra DCT, o conceito de 16×16 também é extremamente importante, especialmente em codecs de vídeo.
No H.264 (e em outros codecs de vídeo), a unidade básica de processamento é o macroblock de 16×16 pixels. Mas esse macroblock não é processado como um bloco único de DCT, ele é subdividido internamente da seguinte forma:
Macroblock 16×16
┌──────────┬──────────┐
│ 8×8 (Y) │ 8×8 (Y) │
│ bloco 0 │ bloco 1 │
├──────────┼──────────┤
│ 8×8 (Y) │ 8×8 (Y) │
│ bloco 2 │ bloco 3 │
└──────────┴──────────┘
+ 8×8 (Cb) + 8×8 (Cr)Num macroblock de 16×16 pixels com Chroma Subsampling 4:2:0 (lembra do artigo 3?), temos:
- 4 blocos de 8×8 pra luminância (Y): porque a luminância tem resolução completa
- 1 bloco de 8×8 pra crominância Cb: resolução reduzida pela metade horizontal e vertical
- 1 bloco de 8×8 pra crominância Cr: idem...
Total: 6 blocos de 8×8 por macroblock.
E cada um desses blocos 8×8 é processado pela DCT individualmente. Então no fundo, mesmo quando falamos de "blocos 16×16", a DCT continua operando em 8×8.
Por que o macroblock é 16×16 e não 8×8?
Porque o macroblock agrupa a lógica de decisão do encoder. É no nível do macroblock que o codec de vídeo decide:
- Qual modo de predição usar (intra ou inter)
- Quanta quantização aplicar
- Se vale a pena subdividir em blocos menores
Mas pra transformada e quantização, a unidade continua sendo 8×8.
Pro nosso CODEC (que é de imagem, não de vídeo), vamos usar blocos 8×8 diretamente, sem a camada extra do macroblock.
Mas é bom saber que ela existe, porque quando chegarmos no artigo 20 (a ponte pro codec de vídeo), esse conceito vai aparecer de novo 😉
Na prática, como uma imagem é dividida em blocos?
Para sabermos como essa divisão funciona, se pegarmos uma imagem de 640×480 pixels (VGA, pra facilitar as contas), depois da conversão RGB → YCbCr e do Chroma Subsampling 4:2:0, nós temos os seguintes valores:
Canal Y: 640 × 480 pixels (resolução completa)
Canal Cb: 320 × 240 pixels (metade de cada dimensão)
Canal Cr: 320 × 240 pixels (metade de cada dimensão)Agora dividimos cada canal em blocos de 8×8:
Canal Y: 640 ÷ 8 = 80 blocos na horizontal × 480÷8 = 60 blocos na vertical = 4.800 blocos
Canal Cb: 320 ÷ 8 = 40 blocos × 240÷8 = 30 blocos = 1.200 blocos
Canal Cr: 320 ÷ 8 = 40 blocos × 240÷8 = 30 blocos = 1.200 blocos
Total: 4.800 + 1.200 + 1.200 = 7.200 blocos de 8×8Cada bloco contém 64 valores (8×8 = 64 pixels). Cada valor é um número de 0 a 255.
A partir daqui, o pipeline do CODEC processa cada bloco independentemente: DCT → Quantização → RLE → Huffman. Bloco por bloco, 7.200 vezes.
E quando as dimensões não são múltiplas de 8?
E se a imagem tiver, digamos, 645×483 pixels? 645 ÷ 8 = 80.625 e 483 ÷ 8 = 60.375. Não fecha!
A solução é o padding: o encoder adiciona pixels extras nas bordas direita e inferior pra completar os blocos. Esses pixels extras geralmente são uma repetição do último pixel da borda (chamado de "edge replication" ou "mirror padding").
Imagem original: 645 × 483
Próximo múltiplo de 8: 648 × 488
Padding: 3 colunas extras à direita + 5 linhas extras embaixoEsses pixels de padding são processados normalmente pela DCT e quantização, mas na hora de decodificar, o decoder sabe (pelo header do arquivo) qual é o tamanho real da imagem e descarta os pixels extras.
O header do nosso CODEC (que vamos definir no artigo 13) vai armazenar tanto as dimensões reais quanto as dimensões com padding. Assim o decoder sabe exatamente o que descartar.
A ordem de processamento dos blocos
Outra decisão importante é a ordem em que os blocos são processados e armazenados no arquivo comprimido.
No JPEG, a ordem padrão é raster scan (da esquerda pra direita, de cima pra baixo), processando todos os macroblocks em sequência, por exemplo:
Ordem raster scan num macroblock 4:2:0:
Para cada macroblock (16×16 pixels):
→ Bloco Y (topo-esquerda 8×8)
→ Bloco Y (topo-direita 8×8)
→ Bloco Y (baixo-esquerda 8×8)
→ Bloco Y (baixo-direita 8×8)
→ Bloco Cb (8×8, cobrindo os mesmos 16×16 pixels)
→ Bloco Cr (8×8, cobrindo os mesmos 16×16 pixels)
Próximo macroblock (16 pixels à direita)...
Quando a linha de macroblocks acaba, desce pra próxima linha...Essa ordem é chamada de interleaved (entrelaçada) porque alterna entre Y, Cb e Cr dentro de cada macroblock.
Existe também o modo non-interleaved, onde todos os blocos Y são processados primeiro, depois todos os Cb, depois todos os Cr. É mais simples de implementar, mas menos eficiente pra decodificação progressiva (onde a imagem vai aparecendo gradualmente na tela).
Inicialmente, para o nosso CODEC, nós vamos usar a ordem non-interleaved por simplicidade:
Todos os blocos 8×8 do canal Y (da esquerda pra direita, de cima pra baixo)
Todos os blocos 8×8 do canal Cb (idem)
Todos os blocos 8×8 do canal Cr (idem)Isso facilita tanto o encoder quanto o decoder, porque cada canal é processado de forma contígua. Mas depois disso, focaremos exclusivamente na interleaved.
Implementando a divisão em blocos em C (Modo Non-Interleaved)
Agora vamos ao código. Vamos construir um programa completo que:
- Lê uma imagem RGB24 (crua ou gerada internamente)
- Converte pra YCbCr
- Aplica Chroma Subsampling 4:2:0
- Divide cada canal em blocos 8×8 (com padding automático)
- Reconstrói a imagem a partir dos blocos (pra provar que é lossless)
- Salva tudo pra visualização
Esse código vai ser a base real do encoder. As funções que criarmos aqui serão reutilizadas diretamente nos artigos seguintes.
Sendo assim, cria uma pasta chamada de codec-blocks-test, e dentro dela um arquivo chamado main.c com o seguinte conteúdo:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
// ============================================================
// CONSTANTES
// ============================================================
#define BLOCK_SIZE 8 // tamanho do bloco (8×8 pixels)
// ============================================================
// ESTRUTURAS
// ============================================================
typedef struct { unsigned char r, g, b; } PixelRGB;
typedef struct { unsigned char y, cb, cr; } PixelYCbCr;
// Um bloco 8×8 de valores (usado pra qualquer canal)
typedef struct {
double valores[BLOCK_SIZE][BLOCK_SIZE];
} Bloco8x8;
// Estrutura que representa um canal (Y, Cb ou Cr) já dividido em blocos
typedef struct {
int largura_original; // largura do canal antes do padding
int altura_original; // altura do canal antes do padding
int largura_padded; // largura com padding (múltiplo de 8)
int altura_padded; // altura com padding (múltiplo de 8)
int blocos_h; // número de blocos na horizontal
int blocos_v; // número de blocos na vertical
int total_blocos; // blocos_h × blocos_v
Bloco8x8 *blocos; // array de blocos
unsigned char *pixels; // array linear dos pixels do canal (com padding)
} CanalEmBlocos;
// ============================================================
// CONVERSÃO RGB ↔ YCbCr (dos artigos anteriores)
// ============================================================
PixelYCbCr rgb_para_ycbcr(PixelRGB rgb) {
PixelYCbCr p;
double y = 0.299*rgb.r + 0.587*rgb.g + 0.114*rgb.b;
double cb = -0.169*rgb.r - 0.331*rgb.g + 0.500*rgb.b + 128.0;
double cr = 0.500*rgb.r - 0.419*rgb.g - 0.081*rgb.b + 128.0;
if(y<0)y=0; if(y>255)y=255;
if(cb<0)cb=0; if(cb>255)cb=255;
if(cr<0)cr=0; if(cr>255)cr=255;
p.y=(unsigned char)round(y);
p.cb=(unsigned char)round(cb);
p.cr=(unsigned char)round(cr);
return p;
}
PixelRGB ycbcr_para_rgb(PixelYCbCr p) {
PixelRGB rgb;
double r = p.y + 1.402*(p.cr-128.0);
double g = p.y - 0.344*(p.cb-128.0) - 0.714*(p.cr-128.0);
double b = p.y + 1.772*(p.cb-128.0);
if(r<0)r=0; if(r>255)r=255;
if(g<0)g=0; if(g>255)g=255;
if(b<0)b=0; if(b>255)b=255;
rgb.r=(unsigned char)round(r);
rgb.g=(unsigned char)round(g);
rgb.b=(unsigned char)round(b);
return rgb;
}
// ============================================================
// ARREDONDAR PRA CIMA PRO PRÓXIMO MÚLTIPLO DE 8
// ============================================================
//
// Exemplos:
// arredondar_para_8(640) = 640 (já é múltiplo)
// arredondar_para_8(645) = 648 (próximo múltiplo)
// arredondar_para_8(100) = 104
int arredondar_para_8(int valor) {
return ((valor + BLOCK_SIZE - 1) / BLOCK_SIZE) * BLOCK_SIZE;
}
// ============================================================
// CRIAR CANAL COM PADDING E DIVISÃO EM BLOCOS
// ============================================================
//
// Essa função recebe os pixels brutos de um canal (Y, Cb ou Cr),
// aplica o padding necessário (edge replication), e divide em
// blocos 8×8.
//
// Edge replication: os pixels da borda são repetidos pra
// preencher o padding. Isso é preferível a preencher com zeros,
// porque zeros criariam uma descontinuidade brusca que produziria
// coeficientes DCT desnecessários (alta frequência artificial).
CanalEmBlocos criar_canal_em_blocos(unsigned char *pixels_originais,
int largura, int altura) {
CanalEmBlocos canal;
canal.largura_original = largura;
canal.altura_original = altura;
canal.largura_padded = arredondar_para_8(largura);
canal.altura_padded = arredondar_para_8(altura);
canal.blocos_h = canal.largura_padded / BLOCK_SIZE;
canal.blocos_v = canal.altura_padded / BLOCK_SIZE;
canal.total_blocos = canal.blocos_h * canal.blocos_v;
// Aloca o array de pixels com padding
int total_padded = canal.largura_padded * canal.altura_padded;
canal.pixels = (unsigned char *) malloc(total_padded);
// Copia os pixels originais e aplica edge replication
for (int j = 0; j < canal.altura_padded; j++) {
for (int i = 0; i < canal.largura_padded; i++) {
// Clamp: se estamos fora da imagem original, usamos
// o pixel da borda mais próxima
int src_i = i;
int src_j = j;
if (src_i >= largura) src_i = largura - 1;
if (src_j >= altura) src_j = altura - 1;
canal.pixels[j * canal.largura_padded + i] =
pixels_originais[src_j * largura + src_i];
}
}
// Aloca o array de blocos
canal.blocos = (Bloco8x8 *) malloc(canal.total_blocos * sizeof(Bloco8x8));
// Divide os pixels em blocos 8×8
for (int bv = 0; bv < canal.blocos_v; bv++) {
for (int bh = 0; bh < canal.blocos_h; bh++) {
int bloco_idx = bv * canal.blocos_h + bh;
// Canto superior esquerdo deste bloco na imagem
int x0 = bh * BLOCK_SIZE;
int y0 = bv * BLOCK_SIZE;
// Copia os 64 pixels deste bloco
for (int y = 0; y < BLOCK_SIZE; y++) {
for (int x = 0; x < BLOCK_SIZE; x++) {
int px = x0 + x;
int py = y0 + y;
canal.blocos[bloco_idx].valores[y][x] =
(double) canal.pixels[py * canal.largura_padded + px];
}
}
}
}
return canal;
}
// ============================================================
// RECONSTRUIR PIXELS A PARTIR DOS BLOCOS
// ============================================================
//
// Faz o inverso: pega os blocos 8×8 e monta o array linear
// de pixels de volta. Usado pelo decoder.
void reconstruir_pixels_de_blocos(CanalEmBlocos *canal) {
for (int bv = 0; bv < canal->blocos_v; bv++) {
for (int bh = 0; bh < canal->blocos_h; bh++) {
int bloco_idx = bv * canal->blocos_h + bh;
int x0 = bh * BLOCK_SIZE;
int y0 = bv * BLOCK_SIZE;
for (int y = 0; y < BLOCK_SIZE; y++) {
for (int x = 0; x < BLOCK_SIZE; x++) {
int px = x0 + x;
int py = y0 + y;
double val = canal->blocos[bloco_idx].valores[y][x];
// Clamp pro range 0-255
if (val < 0) val = 0;
if (val > 255) val = 255;
canal->pixels[py * canal->largura_padded + px] =
(unsigned char) round(val);
}
}
}
}
}
// ============================================================
// EXTRAIR PIXELS ORIGINAIS (sem padding)
// ============================================================
unsigned char *extrair_sem_padding(CanalEmBlocos *canal) {
int w = canal->largura_original;
int h = canal->altura_original;
unsigned char *saida = (unsigned char *) malloc(w * h);
for (int j = 0; j < h; j++) {
for (int i = 0; i < w; i++) {
saida[j * w + i] = canal->pixels[j * canal->largura_padded + i];
}
}
return saida;
}
void liberar_canal(CanalEmBlocos *canal) {
free(canal->pixels);
free(canal->blocos);
}
// ============================================================
// CHROMA SUBSAMPLING 4:2:0 (do artigo 3)
// ============================================================
void subsample_420(unsigned char *cb_full, unsigned char *cr_full,
int width, int height,
unsigned char *cb_half, unsigned char *cr_half) {
int hw = width / 2;
for (int j = 0; j < height / 2; j++) {
for (int i = 0; i < hw; i++) {
int tl = (2*j)*width + (2*i);
int tr = (2*j)*width + (2*i+1);
int bl = (2*j+1)*width + (2*i);
int br = (2*j+1)*width + (2*i+1);
cb_half[j*hw+i] = (unsigned char)((cb_full[tl]+cb_full[tr]+cb_full[bl]+cb_full[br]+2)/4);
cr_half[j*hw+i] = (unsigned char)((cr_full[tl]+cr_full[tr]+cr_full[bl]+cr_full[br]+2)/4);
}
}
}
// ============================================================
// MAIN — Pipeline completo: RGB → YCbCr → 4:2:0 → Blocos 8×8
// ============================================================
int main() {
// Dimensões da imagem de teste (propositalmente NÃO múltiplas de 8
// pra testar o padding)
int width = 100;
int height = 100;
int total = width * height;
printf("=== Pipeline: RGB → YCbCr → 4:2:0 → Blocos 8×8 ===\n\n");
printf("Imagem: %d × %d pixels\n\n", width, height);
// ----- 1. Criar imagem RGB de teste -----
PixelRGB *rgb = (PixelRGB *) malloc(total * sizeof(PixelRGB));
for (int j = 0; j < height; j++) {
for (int i = 0; i < width; i++) {
int idx = j * width + i;
rgb[idx].r = (unsigned char)((i * 255) / (width - 1));
rgb[idx].g = (unsigned char)((j * 255) / (height - 1));
rgb[idx].b = 128;
}
}
printf("Passo 1: Imagem RGB criada (%d pixels, %d bytes)\n",
total, total * 3);
// ----- 2. Converter RGB → YCbCr -----
unsigned char *canal_y_full = (unsigned char *) malloc(total);
unsigned char *canal_cb_full = (unsigned char *) malloc(total);
unsigned char *canal_cr_full = (unsigned char *) malloc(total);
for (int i = 0; i < total; i++) {
PixelYCbCr ycbcr = rgb_para_ycbcr(rgb[i]);
canal_y_full[i] = ycbcr.y;
canal_cb_full[i] = ycbcr.cb;
canal_cr_full[i] = ycbcr.cr;
}
printf("Passo 2: Convertido pra YCbCr\n");
// ----- 3. Chroma Subsampling 4:2:0 -----
int half_w = width / 2;
int half_h = height / 2;
unsigned char *canal_cb_half = (unsigned char *) malloc(half_w * half_h);
unsigned char *canal_cr_half = (unsigned char *) malloc(half_w * half_h);
subsample_420(canal_cb_full, canal_cr_full, width, height,
canal_cb_half, canal_cr_half);
printf("Passo 3: Chroma Subsampling 4:2:0 aplicado\n");
printf(" Canal Y: %d × %d\n", width, height);
printf(" Canal Cb: %d × %d\n", half_w, half_h);
printf(" Canal Cr: %d × %d\n\n", half_w, half_h);
// ----- 4. Dividir cada canal em blocos 8×8 -----
CanalEmBlocos blocos_y = criar_canal_em_blocos(canal_y_full, width, height);
CanalEmBlocos blocos_cb = criar_canal_em_blocos(canal_cb_half, half_w, half_h);
CanalEmBlocos blocos_cr = criar_canal_em_blocos(canal_cr_half, half_w, half_h);
printf("Passo 4: Dividido em blocos 8×8\n");
printf(" Canal Y: %d×%d → padded %d×%d → %d×%d = %d blocos\n",
blocos_y.largura_original, blocos_y.altura_original,
blocos_y.largura_padded, blocos_y.altura_padded,
blocos_y.blocos_h, blocos_y.blocos_v, blocos_y.total_blocos);
printf(" Canal Cb: %d×%d → padded %d×%d → %d×%d = %d blocos\n",
blocos_cb.largura_original, blocos_cb.altura_original,
blocos_cb.largura_padded, blocos_cb.altura_padded,
blocos_cb.blocos_h, blocos_cb.blocos_v, blocos_cb.total_blocos);
printf(" Canal Cr: %d×%d → padded %d×%d → %d×%d = %d blocos\n",
blocos_cr.largura_original, blocos_cr.altura_original,
blocos_cr.largura_padded, blocos_cr.altura_padded,
blocos_cr.blocos_h, blocos_cr.blocos_v, blocos_cr.total_blocos);
printf(" Total: %d blocos de 8×8 (%d coeficientes)\n\n",
blocos_y.total_blocos + blocos_cb.total_blocos + blocos_cr.total_blocos,
(blocos_y.total_blocos + blocos_cb.total_blocos + blocos_cr.total_blocos) * 64);
// ----- 5. Mostrar conteúdo de um bloco exemplo -----
printf("Passo 5: Conteúdo do bloco Y [0][0] (canto superior esquerdo):\n");
for (int y = 0; y < BLOCK_SIZE; y++) {
printf(" ");
for (int x = 0; x < BLOCK_SIZE; x++) {
printf("%5.1f ", blocos_y.blocos[0].valores[y][x]);
}
printf("\n");
}
printf("\n");
printf("Conteúdo do bloco Y [último] (canto inferior direito):\n");
int ultimo = blocos_y.total_blocos - 1;
for (int y = 0; y < BLOCK_SIZE; y++) {
printf(" ");
for (int x = 0; x < BLOCK_SIZE; x++) {
printf("%5.1f ", blocos_y.blocos[ultimo].valores[y][x]);
}
printf("\n");
}
printf("\n");
// ----- 6. Verificação lossless: reconstruir e comparar -----
printf("Passo 6: Verificação lossless (reconstruir a partir dos blocos)...\n");
reconstruir_pixels_de_blocos(&blocos_y);
unsigned char *y_restaurado = extrair_sem_padding(&blocos_y);
int ok = (memcmp(canal_y_full, y_restaurado, total) == 0);
printf(" Canal Y: %s\n",
ok ? "✅ IDÊNTICO ao original" : "❌ DIFERENTE (ERRO!)");
reconstruir_pixels_de_blocos(&blocos_cb);
unsigned char *cb_restaurado = extrair_sem_padding(&blocos_cb);
int ok_cb = (memcmp(canal_cb_half, cb_restaurado, half_w * half_h) == 0);
printf(" Canal Cb: %s\n",
ok_cb ? "✅ IDÊNTICO ao original" : "❌ DIFERENTE (ERRO!)");
reconstruir_pixels_de_blocos(&blocos_cr);
unsigned char *cr_restaurado = extrair_sem_padding(&blocos_cr);
int ok_cr = (memcmp(canal_cr_half, cr_restaurado, half_w * half_h) == 0);
printf(" Canal Cr: %s\n\n",
ok_cr ? "✅ IDÊNTICO ao original" : "❌ DIFERENTE (ERRO!)");
// ----- 7. Salvar pra visualização -----
FILE *f = fopen("original.rgb", "wb");
fwrite(rgb, sizeof(PixelRGB), total, f);
fclose(f);
f = fopen("canal_y_blocos.gray", "wb");
fwrite(canal_y_full, 1, total, f);
fclose(f);
printf("Arquivos salvos! Para visualizar:\n");
printf(" ffplay -f rawvideo -pixel_format rgb24 -video_size %dx%d original.rgb\n",
width, height);
printf(" ffplay -f rawvideo -pixel_format gray -video_size %dx%d canal_y_blocos.gray\n",
width, height);
// ----- Pipeline summary -----
printf("\n=== RESUMO DO PIPELINE ===\n");
printf("RGB24: %d bytes (100%%)\n", total * 3);
printf("YCbCr 4:4:4: %d bytes (100%%)\n", total * 3);
printf("YCbCr 4:2:0: %d bytes (50%%)\n",
total + half_w*half_h + half_w*half_h);
printf("Em blocos: %d blocos × 64 = %d coeficientes\n",
blocos_y.total_blocos + blocos_cb.total_blocos + blocos_cr.total_blocos,
(blocos_y.total_blocos + blocos_cb.total_blocos + blocos_cr.total_blocos) * 64);
printf("\n→ Próximo passo: aplicar DCT em cada bloco (artigo 9)!\n");
// Limpeza
free(rgb);
free(canal_y_full); free(canal_cb_full); free(canal_cr_full);
free(canal_cb_half); free(canal_cr_half);
free(y_restaurado); free(cb_restaurado); free(cr_restaurado);
liberar_canal(&blocos_y);
liberar_canal(&blocos_cb);
liberar_canal(&blocos_cr);
return 0;
}Para compilar e rodar execute isso no seu terminal:
cd ~/codec-blocks-test
gcc main.c -o blocos -lm
./blocosRepare que esse código integra tudo que aprendemos até agora: conversão RGB→YCbCr (artigo 2), Chroma Subsampling 4:2:0 (artigo 3), e agora a divisão em blocos. É o pipeline real do CODEC tomando forma!
A verificação lossless no Passo 6 é fundamental: ela prova que a divisão em blocos + reconstrução não perde nenhum dado.
A estrutura Bloco8x8 usa double (ponto flutuante de 64 bits) em vez de unsigned char justamente pra que no próximo artigo, quando aplicarmos a DCT, os coeficientes (que podem ser positivos, negativos e fracionários) caibam sem problemas.
Implementando a divisão em blocos em C (Modo Interleaved)
Como dito anteriormente, faz muito sentido seguirmos também com a implementação interleaved, que organiza os macroblocos em Y0, Y1, Y2, Y3, Cb, Cr, próximos a ele...
No modo interleaved, a imagem é percorrida em blocos de 16×16 pixels (macroblocks). Cada macroblock agrupa os 6 blocos 8×8 que cobrem aquela região:
Macroblock 16×16 (no canal Y, resolução completa):
┌────────┬────────┐
│ Y0 │ Y1 │
│ (8×8) │ (8×8) │
├────────┼────────┤
│ Y2 │ Y3 │
│ (8×8) │ (8×8) │
└────────┴────────┘
A mesma região no Cb e Cr (subamostrado 4:2:0, metade em cada eixo):
┌────────┐ ┌────────┐
│ Cb │ │ Cr │
│ (8×8) │ │ (8×8) │
└────────┘ └────────┘
Total por macroblock: 4 blocos Y + 1 bloco Cb + 1 bloco Cr = 6 blocosE a ordem no bitstream fica assim:
MB[0]: Y0 → Y1 → Y2 → Y3 → Cb → Cr
MB[1]: Y0 → Y1 → Y2 → Y3 → Cb → Cr
MB[2]: Y0 → Y1 → Y2 → Y3 → Cb → Cr
...Todos os dados de uma região 16×16 ficam contíguos no arquivo. Isso é melhor pra decodificação progressiva (a imagem vai aparecendo região por região) e pra cache de memória (o decoder não precisa pular entre canais distantes).
Sendo assim, crie uma nova pasta chamada de codec-blocks-test-interleaved, e dentro dela um arquivo main.c com a seguinte lógica:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#define BLOCK_SIZE 8
// ============================================================
// ESTRUTURAS
// ============================================================
typedef struct { unsigned char r, g, b; } PixelRGB;
typedef struct { unsigned char y, cb, cr; } PixelYCbCr;
// Um bloco 8×8 de valores (usado pra qualquer canal)
typedef struct {
double valores[BLOCK_SIZE][BLOCK_SIZE];
} Bloco8x8;
// Um macroblock 16×16 no formato 4:2:0 contém:
// 4 blocos 8×8 de Y (cobrindo os 16×16 pixels de luminância)
// 1 bloco 8×8 de Cb (cobrindo os mesmos 16×16 pixels, subamostrado)
// 1 bloco 8×8 de Cr (idem)
// Total: 6 blocos por macroblock
//
// Disposição dos blocos Y dentro do macroblock:
// ┌────┬────┐
// │ Y0 │ Y1 │ Y0 = topo-esquerda (pixels 0-7 x 0-7)
// ├────┼────┤ Y1 = topo-direita (pixels 8-15 x 0-7)
// │ Y2 │ Y3 │ Y2 = baixo-esquerda (pixels 0-7 x 8-15)
// └────┴────┘ Y3 = baixo-direita (pixels 8-15 x 8-15)
typedef struct {
Bloco8x8 y[4]; // Y0, Y1, Y2, Y3
Bloco8x8 cb; // Cb subamostrado (cobre o macroblock inteiro)
Bloco8x8 cr; // Cr subamostrado (idem)
} Macroblock;
// Estrutura que representa a imagem inteira organizada em macroblocks
typedef struct {
int img_width; // largura original da imagem
int img_height; // altura original da imagem
int padded_width; // largura com padding (múltiplo de 16)
int padded_height; // altura com padding (múltiplo de 16)
int mb_cols; // macroblocks na horizontal
int mb_rows; // macroblocks na vertical
int total_mb; // total de macroblocks
int total_blocos; // total de blocos 8×8 (total_mb × 6)
Macroblock *macroblocks; // array de macroblocks
// Canais com padding (pra extração e reconstrução dos blocos)
unsigned char *y_padded; // Y com padding (padded_width × padded_height)
unsigned char *cb_padded; // Cb subamostrado com padding
unsigned char *cr_padded; // Cr subamostrado com padding
int cb_width; // largura do Cb/Cr (padded_width / 2)
int cb_height; // altura do Cb/Cr (padded_height / 2)
} ImagemInterleaved;
// ============================================================
// CONVERSÃO RGB ↔ YCbCr (dos artigos anteriores)
// ============================================================
PixelYCbCr rgb_para_ycbcr(PixelRGB rgb) {
PixelYCbCr p;
double y = 0.299*rgb.r + 0.587*rgb.g + 0.114*rgb.b;
double cb = -0.169*rgb.r - 0.331*rgb.g + 0.500*rgb.b + 128.0;
double cr = 0.500*rgb.r - 0.419*rgb.g - 0.081*rgb.b + 128.0;
if(y<0)y=0; if(y>255)y=255;
if(cb<0)cb=0; if(cb>255)cb=255;
if(cr<0)cr=0; if(cr>255)cr=255;
p.y=(unsigned char)round(y);
p.cb=(unsigned char)round(cb);
p.cr=(unsigned char)round(cr);
return p;
}
PixelRGB ycbcr_para_rgb(PixelYCbCr p) {
PixelRGB rgb;
double r = p.y + 1.402*(p.cr-128.0);
double g = p.y - 0.344*(p.cb-128.0) - 0.714*(p.cr-128.0);
double b = p.y + 1.772*(p.cb-128.0);
if(r<0)r=0; if(r>255)r=255;
if(g<0)g=0; if(g>255)g=255;
if(b<0)b=0; if(b>255)b=255;
rgb.r=(unsigned char)round(r);
rgb.g=(unsigned char)round(g);
rgb.b=(unsigned char)round(b);
return rgb;
}
// ============================================================
// FUNÇÕES AUXILIARES
// ============================================================
// Arredonda pra cima pro próximo múltiplo de 16
// (macroblocks são 16×16, então precisamos múltiplo de 16)
int arredondar_para_16(int valor) {
return ((valor + 15) / 16) * 16;
}
// Extrai um bloco 8×8 de um canal na posição (x0, y0)
Bloco8x8 extrair_bloco(unsigned char *canal, int stride, int x0, int y0) {
Bloco8x8 b;
for (int y = 0; y < BLOCK_SIZE; y++) {
for (int x = 0; x < BLOCK_SIZE; x++) {
b.valores[y][x] = (double) canal[(y0 + y) * stride + (x0 + x)];
}
}
return b;
}
// Escreve um bloco 8×8 de volta num canal na posição (x0, y0)
void escrever_bloco(unsigned char *canal, int stride, int x0, int y0,
Bloco8x8 *b) {
for (int y = 0; y < BLOCK_SIZE; y++) {
for (int x = 0; x < BLOCK_SIZE; x++) {
double val = b->valores[y][x];
if (val < 0) val = 0;
if (val > 255) val = 255;
canal[(y0 + y) * stride + (x0 + x)] = (unsigned char) round(val);
}
}
}
// Cria um canal com padding usando edge replication
unsigned char *criar_canal_padded(unsigned char *original,
int orig_w, int orig_h,
int pad_w, int pad_h) {
unsigned char *padded = (unsigned char *) calloc(pad_w * pad_h, 1);
for (int j = 0; j < pad_h; j++) {
for (int i = 0; i < pad_w; i++) {
int si = (i < orig_w) ? i : orig_w - 1;
int sj = (j < orig_h) ? j : orig_h - 1;
padded[j * pad_w + i] = original[sj * orig_w + si];
}
}
return padded;
}
// ============================================================
// CONSTRUIR A IMAGEM EM MACROBLOCKS (INTERLEAVED)
// ============================================================
//
// Pipeline completo:
// 1. Recebe imagem RGB
// 2. Converte pra YCbCr
// 3. Aplica Chroma Subsampling 4:2:0
// 4. Faz padding pra múltiplo de 16
// 5. Divide em macroblocks 16×16
// 6. Cada macroblock contém Y0, Y1, Y2, Y3, Cb, Cr
//
// A ORDEM INTERLEAVED no bitstream:
// Para cada macroblock (esquerda→direita, cima→baixo):
// → Y0 (topo-esquerda 8×8)
// → Y1 (topo-direita 8×8)
// → Y2 (baixo-esquerda 8×8)
// → Y3 (baixo-direita 8×8)
// → Cb (8×8, cobrindo todo o macroblock subamostrado)
// → Cr (8×8, idem)
// Próximo macroblock...
ImagemInterleaved construir_interleaved(PixelRGB *rgb, int width, int height) {
ImagemInterleaved img;
img.img_width = width;
img.img_height = height;
img.padded_width = arredondar_para_16(width);
img.padded_height = arredondar_para_16(height);
img.mb_cols = img.padded_width / 16;
img.mb_rows = img.padded_height / 16;
img.total_mb = img.mb_cols * img.mb_rows;
img.total_blocos = img.total_mb * 6; // 6 blocos por macroblock
int total = width * height;
// --- Passo 1: Converter RGB → YCbCr ---
unsigned char *y_full = (unsigned char *) malloc(total);
unsigned char *cb_full = (unsigned char *) malloc(total);
unsigned char *cr_full = (unsigned char *) malloc(total);
for (int i = 0; i < total; i++) {
PixelYCbCr p = rgb_para_ycbcr(rgb[i]);
y_full[i] = p.y;
cb_full[i] = p.cb;
cr_full[i] = p.cr;
}
// --- Passo 2: Chroma Subsampling 4:2:0 ---
int half_w = width / 2;
int half_h = height / 2;
unsigned char *cb_half = (unsigned char *) malloc(half_w * half_h);
unsigned char *cr_half = (unsigned char *) malloc(half_w * half_h);
for (int j = 0; j < half_h; j++) {
for (int i = 0; i < half_w; i++) {
int tl = (2*j)*width + (2*i);
int tr = (2*j)*width + (2*i+1);
int bl = (2*j+1)*width + (2*i);
int br = (2*j+1)*width + (2*i+1);
cb_half[j*half_w+i] =
(unsigned char)((cb_full[tl]+cb_full[tr]+cb_full[bl]+cb_full[br]+2)/4);
cr_half[j*half_w+i] =
(unsigned char)((cr_full[tl]+cr_full[tr]+cr_full[bl]+cr_full[br]+2)/4);
}
}
// --- Passo 3: Padding pra múltiplo de 16 ---
img.y_padded = criar_canal_padded(y_full, width, height,
img.padded_width, img.padded_height);
img.cb_width = img.padded_width / 2;
img.cb_height = img.padded_height / 2;
img.cb_padded = criar_canal_padded(cb_half, half_w, half_h,
img.cb_width, img.cb_height);
img.cr_padded = criar_canal_padded(cr_half, half_w, half_h,
img.cb_width, img.cb_height);
// --- Passo 4: Dividir em macroblocks (INTERLEAVED) ---
//
// Para cada macroblock na posição (mb_col, mb_row):
//
// No canal Y (resolução completa):
// O macroblock cobre 16×16 pixels começando em (mb_col*16, mb_row*16)
// Dividimos em 4 blocos 8×8:
// Y0 = (mb_col*16, mb_row*16) topo-esquerda
// Y1 = (mb_col*16 + 8, mb_row*16) topo-direita
// Y2 = (mb_col*16, mb_row*16 + 8) baixo-esquerda
// Y3 = (mb_col*16 + 8, mb_row*16 + 8) baixo-direita
//
// No canal Cb/Cr (resolução metade, por causa do 4:2:0):
// A mesma região 16×16 corresponde a 8×8 pixels em Cb/Cr
// Então é exatamente 1 bloco 8×8 em (mb_col*8, mb_row*8)
img.macroblocks = (Macroblock *) malloc(img.total_mb * sizeof(Macroblock));
for (int mb_row = 0; mb_row < img.mb_rows; mb_row++) {
for (int mb_col = 0; mb_col < img.mb_cols; mb_col++) {
int mb_idx = mb_row * img.mb_cols + mb_col;
// Posição no canal Y (resolução completa)
int y_x0 = mb_col * 16;
int y_y0 = mb_row * 16;
// Extrai os 4 blocos Y
img.macroblocks[mb_idx].y[0] = extrair_bloco(
img.y_padded, img.padded_width, y_x0, y_y0); // topo-esq
img.macroblocks[mb_idx].y[1] = extrair_bloco(
img.y_padded, img.padded_width, y_x0 + 8, y_y0); // topo-dir
img.macroblocks[mb_idx].y[2] = extrair_bloco(
img.y_padded, img.padded_width, y_x0, y_y0 + 8); // baixo-esq
img.macroblocks[mb_idx].y[3] = extrair_bloco(
img.y_padded, img.padded_width, y_x0 + 8, y_y0 + 8); // baixo-dir
// Posição no canal Cb/Cr (metade das coordenadas)
int c_x0 = mb_col * 8;
int c_y0 = mb_row * 8;
img.macroblocks[mb_idx].cb = extrair_bloco(
img.cb_padded, img.cb_width, c_x0, c_y0);
img.macroblocks[mb_idx].cr = extrair_bloco(
img.cr_padded, img.cb_width, c_x0, c_y0);
}
}
free(y_full); free(cb_full); free(cr_full);
free(cb_half); free(cr_half);
return img;
}
// ============================================================
// RECONSTRUIR OS CANAIS A PARTIR DOS MACROBLOCKS
// ============================================================
//
// Faz o inverso da divisão: pega os blocos de cada macroblock
// e escreve de volta nos canais Y, Cb, Cr.
// Usado pelo decoder pra reconstruir a imagem.
void reconstruir_de_macroblocks(ImagemInterleaved *img) {
for (int mb_row = 0; mb_row < img->mb_rows; mb_row++) {
for (int mb_col = 0; mb_col < img->mb_cols; mb_col++) {
int mb_idx = mb_row * img->mb_cols + mb_col;
Macroblock *mb = &img->macroblocks[mb_idx];
// Escreve os 4 blocos Y de volta
int y_x0 = mb_col * 16;
int y_y0 = mb_row * 16;
escrever_bloco(img->y_padded, img->padded_width,
y_x0, y_y0, &mb->y[0]);
escrever_bloco(img->y_padded, img->padded_width,
y_x0 + 8, y_y0, &mb->y[1]);
escrever_bloco(img->y_padded, img->padded_width,
y_x0, y_y0 + 8, &mb->y[2]);
escrever_bloco(img->y_padded, img->padded_width,
y_x0 + 8, y_y0 + 8, &mb->y[3]);
// Escreve Cb e Cr de volta
int c_x0 = mb_col * 8;
int c_y0 = mb_row * 8;
escrever_bloco(img->cb_padded, img->cb_width,
c_x0, c_y0, &mb->cb);
escrever_bloco(img->cr_padded, img->cb_width,
c_x0, c_y0, &mb->cr);
}
}
}
// ============================================================
// ITERAR SOBRE BLOCOS NA ORDEM INTERLEAVED
// ============================================================
//
// Essa função mostra como percorrer todos os blocos na ordem
// exata em que seriam escritos no bitstream do arquivo.
// É essa ordem que o encoder usaria pra serializar os dados
// e que o decoder usaria pra ler.
//
// A callback recebe cada bloco e um label dizendo o que ele é.
typedef void (*CallbackBloco)(Bloco8x8 *bloco, const char *label,
int mb_idx, int bloco_no_mb);
void iterar_blocos_interleaved(ImagemInterleaved *img,
CallbackBloco callback) {
for (int mb_row = 0; mb_row < img->mb_rows; mb_row++) {
for (int mb_col = 0; mb_col < img->mb_cols; mb_col++) {
int mb_idx = mb_row * img->mb_cols + mb_col;
Macroblock *mb = &img->macroblocks[mb_idx];
// A ordem JPEG interleaved: Y0, Y1, Y2, Y3, Cb, Cr
callback(&mb->y[0], "Y0", mb_idx, 0);
callback(&mb->y[1], "Y1", mb_idx, 1);
callback(&mb->y[2], "Y2", mb_idx, 2);
callback(&mb->y[3], "Y3", mb_idx, 3);
callback(&mb->cb, "Cb", mb_idx, 4);
callback(&mb->cr, "Cr", mb_idx, 5);
}
}
}
void liberar_interleaved(ImagemInterleaved *img) {
free(img->y_padded);
free(img->cb_padded);
free(img->cr_padded);
free(img->macroblocks);
}
// ============================================================
// MAIN — Testa o pipeline interleaved completo
// ============================================================
// Callback pra contar blocos durante a iteração
int g_contador = 0;
void callback_contar(Bloco8x8 *bloco, const char *label,
int mb_idx, int bloco_no_mb) {
// Mostra os primeiros blocos pra o leitor ver a ordem
if (g_contador < 18) { // 3 macroblocks × 6 blocos
if (bloco_no_mb == 0) {
printf(" MB[%d]:", mb_idx);
}
printf(" %s", label);
if (bloco_no_mb == 5) {
printf("\n");
}
} else if (g_contador == 18) {
printf(" ...\n");
}
g_contador++;
}
int main() {
int width = 100;
int height = 100;
int total = width * height;
printf("=== Pipeline INTERLEAVED: RGB → YCbCr → 4:2:0 → Macroblocks ===\n\n");
printf("Imagem: %d × %d pixels\n\n", width, height);
// Criar imagem RGB de teste
PixelRGB *rgb = (PixelRGB *) malloc(total * sizeof(PixelRGB));
for (int j = 0; j < height; j++) {
for (int i = 0; i < width; i++) {
int idx = j * width + i;
rgb[idx].r = (unsigned char)((i * 255) / (width - 1));
rgb[idx].g = (unsigned char)((j * 255) / (height - 1));
rgb[idx].b = 128;
}
}
// Construir estrutura interleaved
ImagemInterleaved img = construir_interleaved(rgb, width, height);
printf("Dimensões:\n");
printf(" Original: %d × %d\n", img.img_width, img.img_height);
printf(" Com padding: %d × %d (múltiplo de 16)\n",
img.padded_width, img.padded_height);
printf(" Macroblocks: %d × %d = %d\n",
img.mb_cols, img.mb_rows, img.total_mb);
printf(" Blocos 8×8: %d MB × 6 = %d blocos\n",
img.total_mb, img.total_blocos);
printf(" Coeficientes: %d blocos × 64 = %d\n\n",
img.total_blocos, img.total_blocos * 64);
// Mostrar a ordem interleaved (primeiros 3 MBs)
printf("Ordem dos blocos no bitstream:\n");
g_contador = 0;
iterar_blocos_interleaved(&img, callback_contar);
printf(" Total: %d blocos processados\n\n", g_contador);
// Mostrar conteúdo de blocos do MB[0]
printf("Conteúdo do MB[0], bloco Y0 (topo-esquerda):\n");
for (int y = 0; y < BLOCK_SIZE; y++) {
printf(" ");
for (int x = 0; x < BLOCK_SIZE; x++)
printf("%5.1f ", img.macroblocks[0].y[0].valores[y][x]);
printf("\n");
}
printf("\n");
printf("Conteúdo do MB[0], bloco Y3 (baixo-direita):\n");
for (int y = 0; y < BLOCK_SIZE; y++) {
printf(" ");
for (int x = 0; x < BLOCK_SIZE; x++)
printf("%5.1f ", img.macroblocks[0].y[3].valores[y][x]);
printf("\n");
}
printf("\n");
printf("Conteúdo do MB[0], bloco Cb:\n");
for (int y = 0; y < BLOCK_SIZE; y++) {
printf(" ");
for (int x = 0; x < BLOCK_SIZE; x++)
printf("%5.1f ", img.macroblocks[0].cb.valores[y][x]);
printf("\n");
}
printf("\n");
// Verificação lossless
printf("Verificação lossless (zera canais → reconstrói dos macroblocks):\n");
int pad_total = img.padded_width * img.padded_height;
int cb_total = img.cb_width * img.cb_height;
unsigned char *y_bak = (unsigned char *) malloc(pad_total);
unsigned char *cb_bak = (unsigned char *) malloc(cb_total);
unsigned char *cr_bak = (unsigned char *) malloc(cb_total);
memcpy(y_bak, img.y_padded, pad_total);
memcpy(cb_bak, img.cb_padded, cb_total);
memcpy(cr_bak, img.cr_padded, cb_total);
// Zera tudo (força a reconstrução)
memset(img.y_padded, 0, pad_total);
memset(img.cb_padded, 0, cb_total);
memset(img.cr_padded, 0, cb_total);
// Reconstrói a partir dos macroblocks
reconstruir_de_macroblocks(&img);
int ok_y = (memcmp(y_bak, img.y_padded, pad_total) == 0);
int ok_cb = (memcmp(cb_bak, img.cb_padded, cb_total) == 0);
int ok_cr = (memcmp(cr_bak, img.cr_padded, cb_total) == 0);
printf(" Canal Y: %s\n", ok_y ? "✅ IDÊNTICO" : "❌ ERRO!");
printf(" Canal Cb: %s\n", ok_cb ? "✅ IDÊNTICO" : "❌ ERRO!");
printf(" Canal Cr: %s\n\n", ok_cr ? "✅ IDÊNTICO" : "❌ ERRO!");
// Comparação didática
printf("=== Non-interleaved vs Interleaved ===\n\n");
printf(" Non-interleaved:\n");
printf(" Y[0] Y[1] Y[2] ... Y[%d] (todos os Y primeiro)\n",
img.total_mb*4-1);
printf(" Cb[0] Cb[1] ... Cb[%d] (depois todos os Cb)\n",
img.total_mb-1);
printf(" Cr[0] Cr[1] ... Cr[%d] (depois todos os Cr)\n\n",
img.total_mb-1);
printf(" Interleaved:\n");
printf(" MB[0]: Y0 Y1 Y2 Y3 Cb Cr (tudo de uma região junto)\n");
printf(" MB[1]: Y0 Y1 Y2 Y3 Cb Cr\n");
printf(" ...\n");
printf(" MB[%d]: Y0 Y1 Y2 Y3 Cb Cr\n\n", img.total_mb-1);
printf(" Vantagem interleaved:\n");
printf(" Todos os dados de uma região 16×16 ficam contíguos.\n");
printf(" Melhor pra decodificação progressiva e cache de memória.\n");
printf(" É o modo padrão do JPEG.\n\n");
printf(" Vantagem non-interleaved:\n");
printf(" Mais simples de implementar.\n");
printf(" Cada canal é um bloco contíguo de dados.\n");
free(rgb);
free(y_bak); free(cb_bak); free(cr_bak);
liberar_interleaved(&img);
return 0;
}Antes de continuarmos vamos entender as principais diferenças entre a versão non-interleaved.
Estrutura MacroBlock: agrupa 4 blocos Y + 1 Cb + 1 Cr numa única struct, representando uma região 16×16 da imagem.
Padding pra múltiplo de 16: em vez de 8, porque macroblocks são 16×16. A imagem 100×100 fica 112×112 (em vez de 104×104).
Ordem no bitstream: Y0→Y1→Y2→Y3→Cb→Cr por macroblock. Todos os dados de uma região ficam contíguos, exatamente como o JPEG faz.
Função iterar_blocos_interleaved com callback: essa é a peça mais estratégica. Quando chegar na hora de construir o encoder (artigo 13), basta plugar o callback que faz "DCT → quantização → Huffman" e o encoder tá pronto.
Verificação pesada: zera os 3 canais por completo e reconstrói 100% a partir dos macroblocks. Os 3 canais voltaram idênticos.
Pra compilar e rodar:
cd ~/codec-blocks-test-interleaved
gcc main.c -o blocos -lm
./blocosA saída mostra o pipeline completo, a ordem exata dos blocos no bitstream, o conteúdo dos blocos Y0, Y3 e Cb do primeiro macroblock, e a verificação lossless (que zera todos os canais e reconstrói puramente a partir dos macroblocks).
Repare na função iterar_blocos_interleaved
Quando chegarmos no artigo 13 (construindo o encoder), essa função será o coração do loop de serialização, basta trocar o callback por "aplica DCT + quantiza + codifica com Huffman" e temos o encoder completo.
Vejamos os resultados dos testes:
=== Pipeline INTERLEAVED: RGB → YCbCr → 4:2:0 → Macroblocks ===
Imagem: 100 × 100 pixels
Dimensões:
Original: 100 × 100
Com padding: 112 × 112 (múltiplo de 16)
Macroblocks: 7 × 7 = 49
Blocos 8×8: 49 MB × 6 = 294 blocos
Coeficientes: 294 blocos × 64 = 18816
Ordem dos blocos no bitstream:
MB[0]: Y0 Y1 Y2 Y3 Cb Cr
MB[1]: Y0 Y1 Y2 Y3 Cb Cr
MB[2]: Y0 Y1 Y2 Y3 Cb Cr
...
Total: 294 blocos processados
Verificação lossless (zera canais → reconstrói dos macroblocks):
Canal Y: ✅ IDÊNTICO
Canal Cb: ✅ IDÊNTICO
Canal Cr: ✅ IDÊNTICONote que o padding aqui é pra múltiplo de 16 (não de 8 como na versão non-interleaved), porque macroblocks são 16×16.
Por isso a imagem 100×100 fica 112×112 (em vez de 104×104), resultando em 294 blocos (em vez de 267). São 27 blocos a mais por causa do padding maior, mas esses blocos extras contêm pixels de edge replication e serão descartados na decodificação.
Os artefatos de bloco: o preço da divisão
Antes de fechar, preciso ser honesto sobre o custo da divisão em blocos.
Lembra que eu disse que cada bloco é processado independentemente?
Isso tem um efeito colateral: nas bordas entre blocos vizinhos, podem aparecer descontinuidades visíveis. Essas descontinuidades são os famosos artefatos de bloco (blocking artifacts).
Quando a quantização é leve (qualidade alta), os artefatos são quase imperceptíveis. Mas quando a quantização é pesada (qualidade baixa), os blocos 8×8 ficam claramente visíveis como uma grade de quadradinhos na imagem.

Os CODECs modernos lidam com isso de duas formas diferentes:
- Deblocking filter (filtro de desblocking): aplica um leve blur nas bordas entre blocos depois da decodificação, suavizando as descontinuidades. O H.264 e o H.265 fazem isso por padrão. Vamos ver isso no artigo 19.
- Blocos de tamanho variável: em vez de sempre usar 8×8, o encoder pode usar blocos maiores em áreas suaves (onde artefatos seriam mais visíveis) e blocos menores em áreas complexas. O H.265 pode usar de 4×4 até 64×64. O AV1 pode usar até 128×128.
Pro nosso CODEC, vamos começar usando blocos fixos de 8×8 sem deblocking filter (pra manter a simplicidade).
Em seguida, vamos explorar como o deblocking filter pode ser adicionado como melhoria ☺️
Resumo: a fundação do processamento por blocos
Vamos recapitular tudo o que aprendemos neste artigo:
- Os CODECs dividem a imagem em blocos pequenos (tipicamente 8×8) porque processar a imagem inteira de uma vez é impraticável em termos de memória, velocidade e eficiência.
- O tamanho 8×8 é o equilíbrio ideal entre eficiência da DCT, artefatos visuais, otimização de hardware e homogeneidade local.
- CODECs de vídeo usam macroblocks de 16×16 que contêm 4 blocos 8×8 de Y + 1 de Cb + 1 de Cr (com 4:2:0).
- Quando as dimensões da imagem não são múltiplas de 8, o encoder faz padding (edge replication) nas bordas.
- A ordem de processamento pode ser interleaved (Y+Cb+Cr por macroblock) ou non-interleaved (todos os Y, depois Cb, depois Cr).
- A divisão em blocos pode causar artefatos de bloco em compressão pesada, resolvidos com deblocking filters ou blocos de tamanho variável.
- As estruturas de dados que criamos (CanalEmBlocos, Bloco8x8) serão reutilizadas diretamente nos próximos artigos.
No próximo artigo, vamos aplicar a DCT (Discrete Cosine Transform) em cada bloco 8×8, a transformada que converte pixels em frequências e é o coração absoluto de qualquer CODEC baseado em DCT (JPEG, H.264, H.265, AV1...).
Prepare-se, porque o próximo artigo é o mais denso e mais fascinante da série inteira. É lá que tudo se conecta 🚀

